ACE-ADK: 論文「Agentic Context Engineering」をGoogle ADKで実装してみた
LLM(大規模言語モデル)の進化に伴い、単にプロンプトに応答するだけでなく、自らの経験から学び、継続的に性能を向上させる「自己改善するLLMシステム」への関心が高まっています。このようなシステムを実現するためのアプローチの一つとして、論文「Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models」で提唱されたACE (Agentic Context Engineering) フレームワークがあります。
ACEは、LLMに与えるコンテキスト(指示や過去の経験など)を「進化する戦略書(Playbook)」として扱い、エージェント自身が試行錯誤を通じてこのPlaybookを洗練させていく仕組みです。
本記事では、このACEフレームワークのコンセプトを解説し、Googleが提供するエージェント開発用フレームワーク Google ADK (Agent Development Kit) を用いてその中核的なサイクルを実装したスタータープロジェクト「ACE-ADK」を紹介します。
第1部: Agentic Context Engineering (ACE) とは?
1. Context Adaptationの課題
LLMの性能を向上させる手法として、モデルの重みを更新するファインチューニングとは別に、プロンプトや外部メモリなどのコンテキストを工夫するContext Adaptation(またはContext Engineering)が注目されています。これは、迅速かつ解釈可能な形でLLMの振る舞いを調整できる強力なアプローチです。
しかし、論文では既存のContext Adaptation手法に2つの主要な課題があると指摘しています。
Brevity Bias(簡潔さへの偏り)
多くのプロンプト最適化手法は、短く汎用的な指示を生成する傾向があります。しかし、エージェントが複雑なタスクを遂行するには、ドメイン固有のヒューリスティクスや過去の失敗から得られた具体的な教訓が不可欠です。簡潔さを追求するあまり、こうした詳細な知識が失われてしまう問題が「Brevity Bias」です。
Context Collapse(文脈の崩壊)
コンテキストを反復的にLLM自身に要約・書き換えさせると、回を重ねるごとに情報が劣化し、最終的には非常に短く内容の薄いものに収束してしまうことがあります。これにより、せっかく蓄積した知識が失われ、性能が大幅に低下する現象が「Context Collapse」です。論文では、適応を重ねるうちにコンテキストのトークン数が激減し、精度がベースライン以下に落ち込む実験結果が示されています(下図参照)。
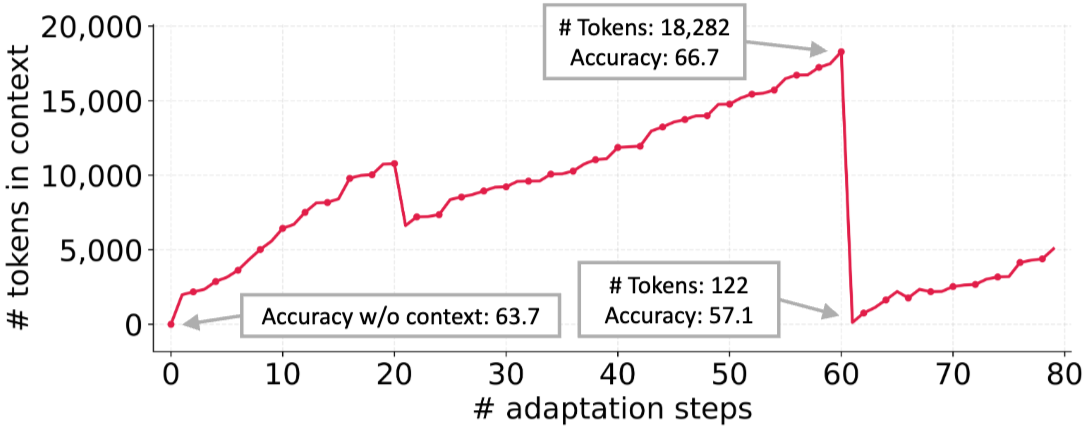
論文 Figure 2 より引用
2. ACEフレームワークの概要
これらの課題を解決するため、ACEはコンテキストを静的な指示書ではなく、「進化するPlaybook」として扱います。このPlaybookは、エージェントがタスクを経験する中で戦略を蓄積し、整理し、洗練させていくための動的な知識ベースです。
ACEフレームワークは、人間が「実験→反省→整理」というサイクルで学習するプロセスに着想を得ており、以下の3つの役割を持つエージェント(またはモジュール)が連携して動作します。
- Generator: 現在のPlaybookを参考に、与えられたクエリに対する回答や行動計画(Trajectory)を生成します。
- Reflector: Generatorが生成したTrajectoryの結果(成功、失敗、エラーなど)を批判的に分析し、そこから具体的な教訓や洞察(Insights)を抽出します。
- Curator: Reflectorが抽出した洞察を整理し、Playbookを更新するための差分データ(Delta Context Items)に変換します。
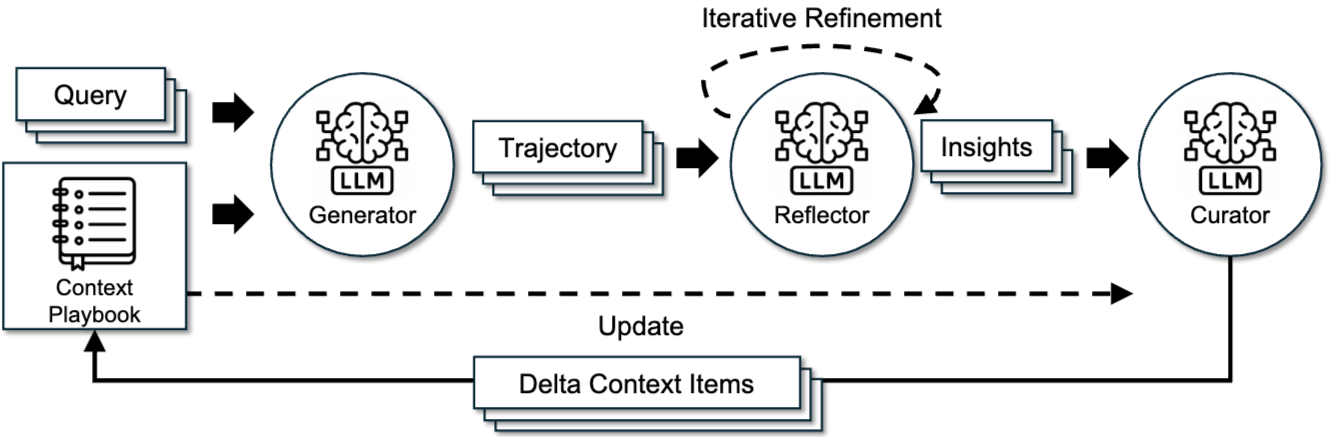
論文 Figure 4 より引用
このアーキテクチャは、以下の革新的な特徴を持っています。
- Reflectorによる評価と洞察抽出の分離: 生成役と評価役を明確に分けることで、客観的で質の高い洞察を得やすくなります。
- Incremental Delta Updates: Playbook全体を書き換えるのではなく、差分(追加・更新・削除)のみを適用することで、Context Collapseを防ぎ、低コストで効率的な更新を実現します。Playbookは構造化された箇条書き(bullet)の集まりとして表現されます。
- Grow-and-Refineメカニズム: Playbookを継続的に成長させつつ、重複や不要な情報を定期的に整理することで、品質を維持します。
3. ACEの利点
ACEフレームワークは、以下のような多くの利点をもたらします。
- 高性能・自己改善エージェントの実現: エージェントが自身の経験から学び、Playbookを改善していくことで、タスク遂行能力が向上します。
- ドメイン特化ベンチマークでの性能向上: 金融分析などの専門知識が求められる領域で、ドメイン固有の知見をPlaybookに蓄積し、高い性能を発揮します。
- 低コスト・低レイテンシでの適応: 差分更新により、LLMの呼び出し回数や計算コストを大幅に削減できます。
- ラベルなし教師データでの適応能力: 正解ラベルがなくても、コードの実行結果やAPIの応答といった自然なフィードバックを活用して学習を進めることができます。
第2部: Google ADKによる実装「ACE-ADK」
今回紹介する「ACE-ADK」は、このACEフレームワークの中核的なサイクルをGoogle ADKで実装したスタータープロジェクトです。
https://github.com/sunyeul/ace-adk
1. ACE-ADK プロジェクト概要
ACE-ADKは、「生成→内省→知見反映」というサイクルを実際に動かし、Playbookが改善されていく様子を体験することを目的に作られています。主な特徴は以下の通りです。
- ACEサイクルの実装:
Generator,Reflector,Curatorが連携し、状態(session.state)内のapp:playbookを更新します。 - スキーマによる厳格な入出力: Pydanticスキーマを用いて各エージェントの入出力を定義し、安定した動作を実現します。
- ローカルでの簡単な起動:
uvコマンドを使って、数分でWeb UIを起動し、動作を確認できます。
2. アーキテクチャと主要コンポーネント
ACE-ADKは、複数のサブエージェントを直列に繋いだSequentialAgentとして実装されています。全体のエージェント呼び出しフローは以下の通りです。
StateInitializer → Generator → Reflector → Curator
各コンポーネントの役割と実装を見ていきましょう。
StateInitializer (agents/ace_agent/agent.py)
サイクルの最初に呼び出され、エージェントが動作するために必要な状態(State)を準備します。
- ユーザーからの入力を
user_queryとして設定します。 - Playbook(
app:playbook)がまだ存在しない場合、空のPlaybookオブジェクトを生成して初期化します。 - 正解データ(
ground_truth)を任意で扱えるようにNoneで初期化します。
現在のPlaybookを参照して、ユーザーのクエリに対する回答と、その思考プロセスを生成します。
- 入力:
user_query,app:playbook - 出力:
GeneratorOutputスキーマに基づき、以下の情報を構造化して返します。reasoning: 思考プロセス(Chain of Thought)。bullet_ids: 参照したPlaybookの項目IDリスト。final_answer: 最終的な回答。
- 出力は
generator_outputというキーで状態に保存されます。
Generatorの出力を評価し、改善のための洞察を抽出します。
- 入力:
user_query,generator_output,app:playbook, (オプションでground_truth) - 出力:
Reflectionスキーマに基づき、エラー分析、根本原因、正しいアプローチ、重要な教訓などを構造化して返します。 reflector_とtag_bulletという2つのエージェントから成るSequentialAgentです。reflector_: Generatorのreasoningと結果を分析し、Reflectionを生成します。このとき、参照されたbullet_idsが回答に役立ったか(helpful)、害になったか(harmful)、影響がなかったか(neutral)をbullet_tagsとして出力します。tag_bullet:bullet_tagsの結果に基づき、Playbook内の各Bulletオブジェクトの統計情報(helpful,harmful,neutralのカウント)を更新します。
Reflectorからの洞察を基に、Playbookを具体的にどう変更するかを決定し、実行します。
- 入力:
user_query,reflector_output,app:playbook - 出力:
DeltaBatchスキーマに基づき、Playbookへの変更操作リストを生成します。 curator_とplaybook_updaterという2つのエージェントから構成されます。curator_: Reflectorの分析結果(key_insightなど)を基に、Playbookに対して行うべき操作(ADD,UPDATE,REMOVE)をDeltaOperationのリストとして具体化します。playbook_updater: 生成されたDeltaBatchをapp:playbookに適用し、Playbookオブジェクトを実際に更新します。
3. データモデル (schemas/)
本プロジェクトでは、Playbookとその更新差分をPydanticモデルで厳格に定義しています。
Playbook (agents/ace_agent/schemas/playbook.py)
Bullet: Playbookを構成する最小単位。ID、内容(content)、タグ統計(helpful,harmful,neutral)などを持ちます。Playbook:Bulletの集合を管理するクラス。Bulletの追加・更新・削除や、差分適用(apply_delta)、プロンプト注入用のテキスト生成(as_prompt)などの責務を担います。
agents/ace_agent/schemas/playbook.py
class Bullet(BaseModel): """Single playbook entry.""" id: str section: str content: str helpful: int = 0 harmful: int = 0 neutral: int = 0 created_at: str = Field(...) updated_at: str = Field(...) def tag(self, tag: Literal["helpful", "harmful", "neutral"], increment: int = 1) -> None:
DeltaBatch (agents/ace_agent/schemas/delta.py)
DeltaOperation: Playbookへの単一の変更操作を定義します。type("ADD", "UPDATE", "REMOVE")、対象セクション(section)、内容(content)、対象ID(bullet_id)などを持ちます。DeltaBatch: Curatorの思考プロセス(reasoning)と、DeltaOperationのリスト(operations)をまとめたものです。
agents/ace_agent/schemas/delta.py
OperationType = Literal["ADD", "UPDATE", "REMOVE"] class DeltaOperation(BaseModel): """Single mutation to apply to the playbook.""" type: OperationType section: str content: Optional[str] = None bullet_id: Optional[str] = None class DeltaBatch(BaseModel): """Bundle of curator reasoning and delta operations.""" reasoning: str operations: List[DeltaOperation] = Field(default_factory=list)
4. クイックスタートと設定
リポジトリをクローンし、Pythonのパッケージ管理ツールuvがインストールされていれば、以下のコマンドだけでWeb UIを起動できます。
uv sync
uv run main.py
http://127.0.0.1:8080にアクセスすると、ADKのWeb UIが表示されます。
各エージェントが使用するモデルはconfig.pyで、APIキーなどは.envファイルで設定できます(.env.exampleをコピーして編集してください)。
5. 実行例とPlaybookの進化(概念)
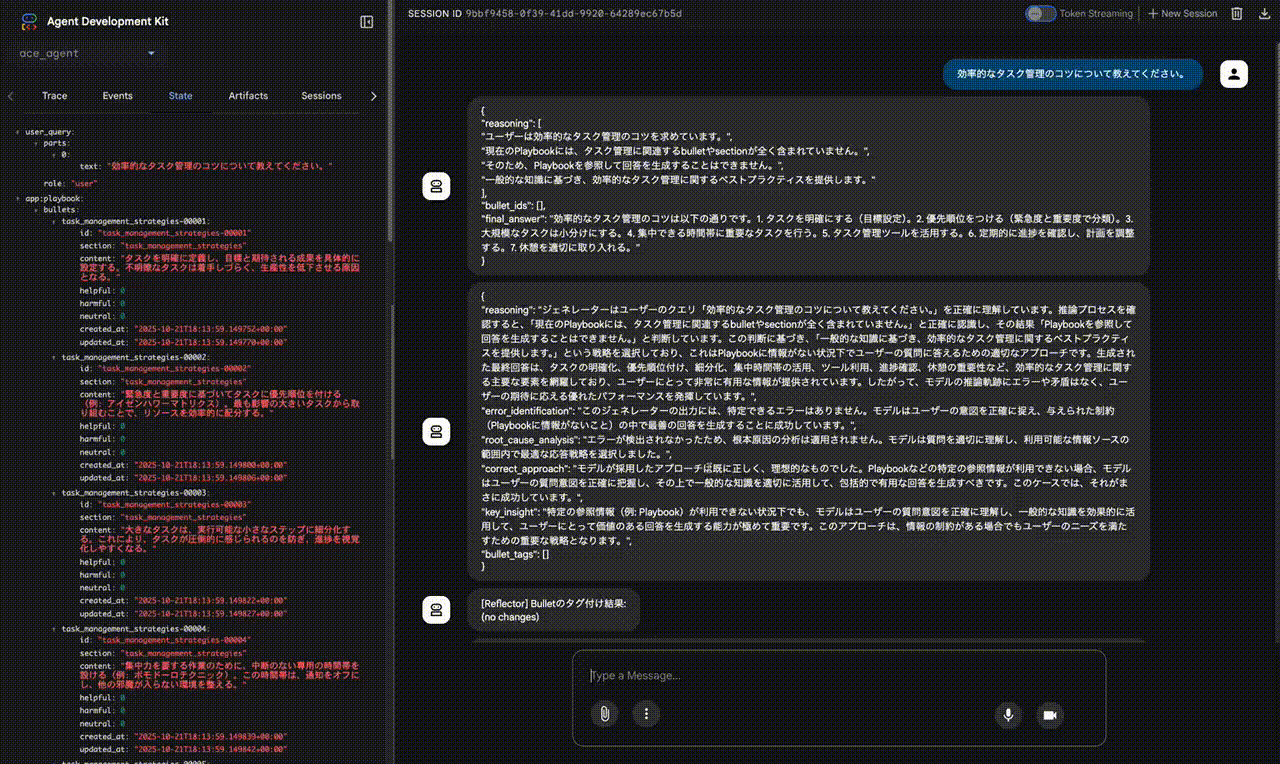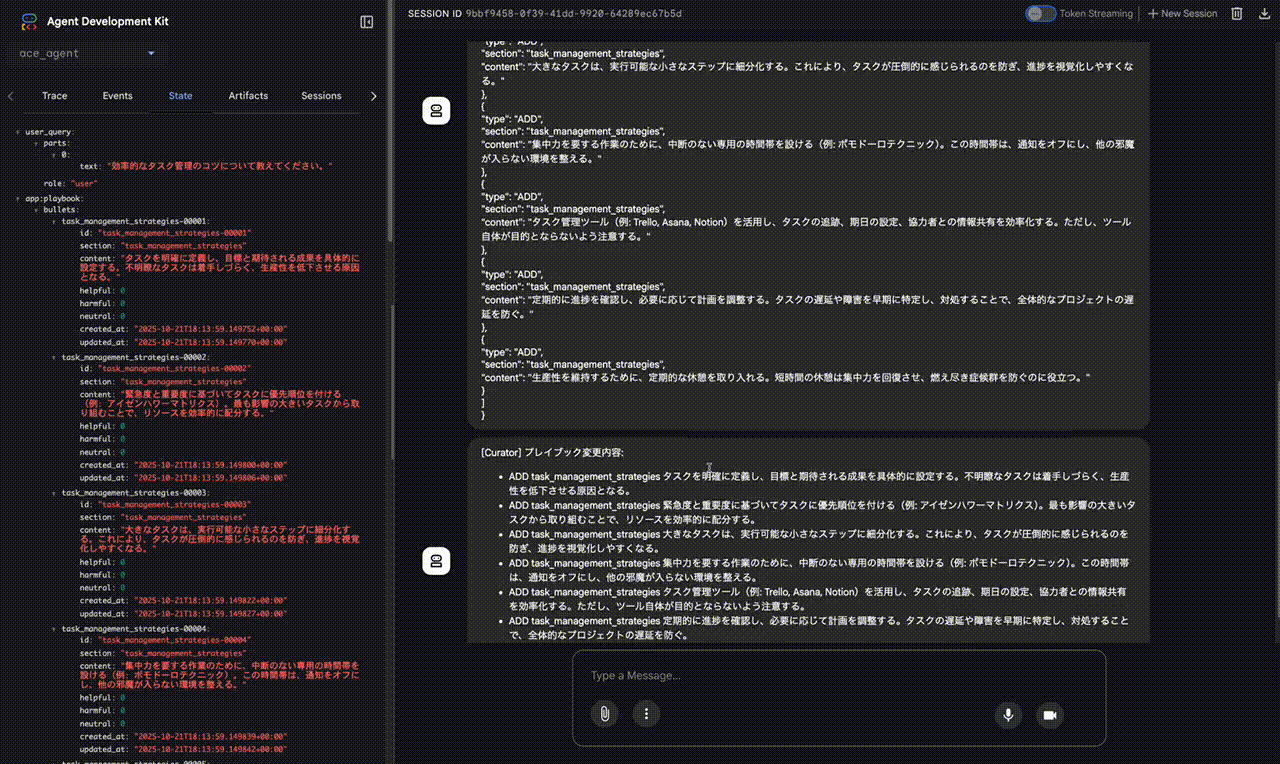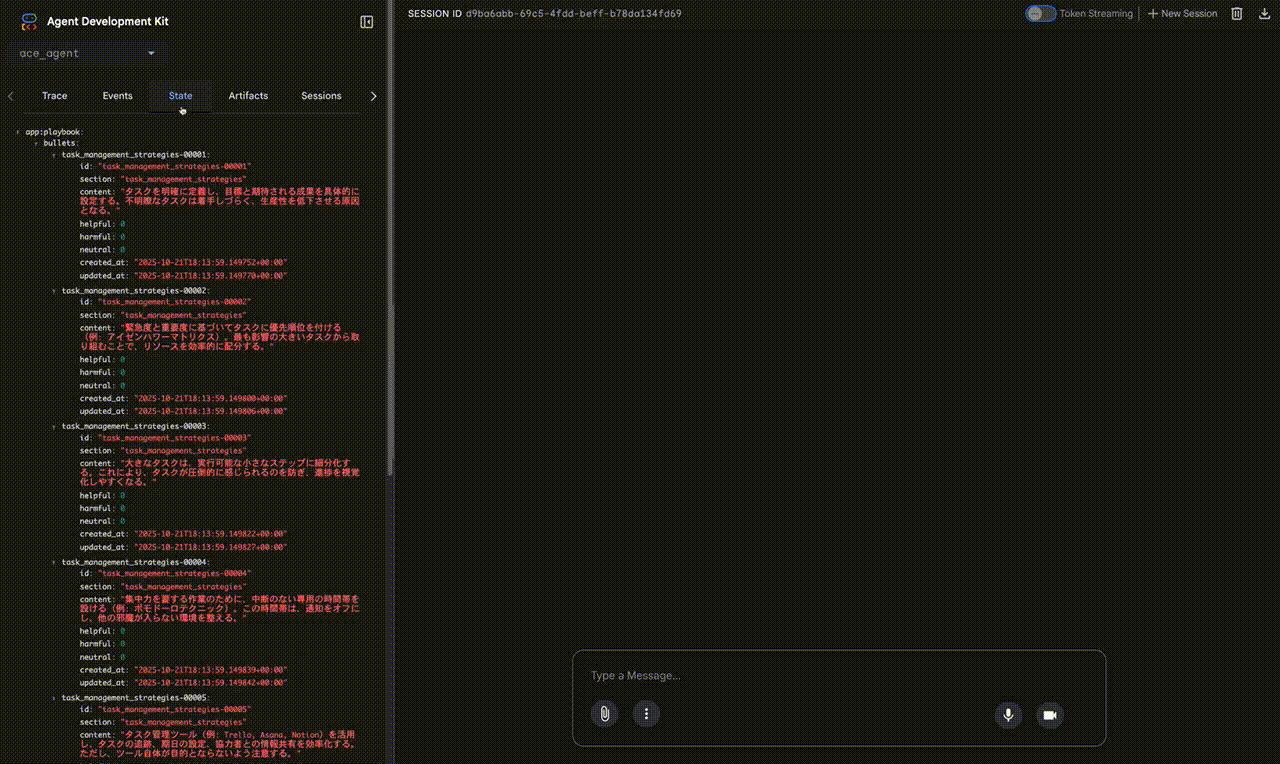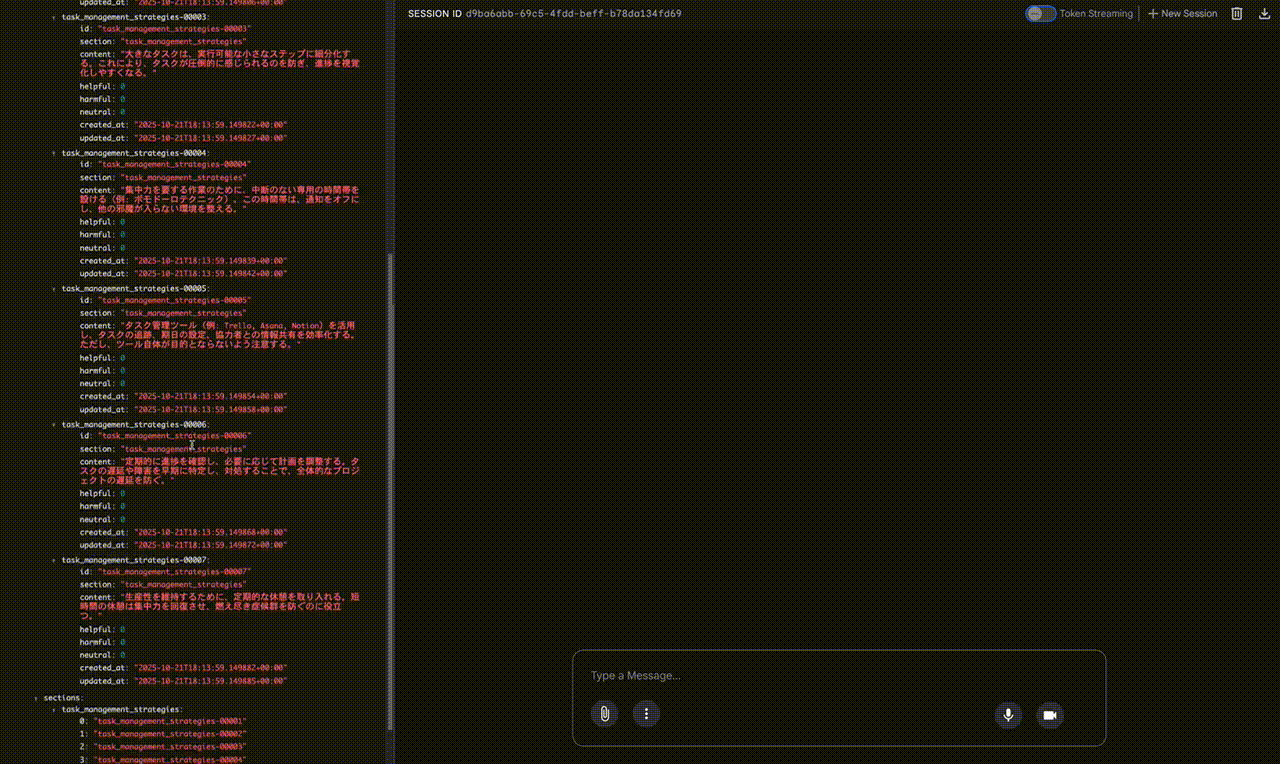
実際にACE-ADKが動作し、Playbookが進化していく様子を、動画デモを元に見ていきましょう。
-
最初のセッション (Playbookが空の状態):
- ユーザー入力: Web UIから「効率的なタスク管理について教えてください」と入力します。
- Generator: この時点では
app:playbookは空なので、Generatorは自身の内部知識だけを頼りに、タスク管理に関する一般的な回答を生成します。reasoning、空のbullet_ids、final_answerが出力されます。 - Reflector: Generatorの出力を分析します。今回はエラーがあったわけではありませんが、一般的なタスク管理の原則に関する洞察 (
key_insight) を抽出します。参照されたBulletがないため、bullet_tagsは空です。 - Curator: Reflectorが抽出した
key_insight(タスク分解、優先順位付け、ツール活用など)は、Playbookにまだ存在しない新しい知識だと判断します。そのため、これらの洞察を具体的なBulletとしてPlaybookに追加するためのDeltaBatch(複数のADD操作)を生成します。 - Playbook更新:
playbook_updaterがDeltaBatchを適用し、app:playbook内にtask_management_strategiesといったセクションと、対応するBulletが初めて作成されます 。
-
新しいセッション (Playbookが更新された状態の確認):
- セッションの開始: 「+ New Session」ボタンがクリックし、新しいセッションが開始されます。
- Playbookの状態: 新しいセッションが開始された直後ですが、左側の
Stateパネルを見ると、app:playbookには最初のセッションでCuratorによって追加されたタスク管理戦略のBulletが既に読み込まれていることが確認できます。 - 状態の永続性: これは、ADKのWeb UI環境(デフォルト設定)では、
app:プレフィックスを持つ状態キー(app:playbookなど)がセッション間で永続化されることを示しています。つまり、一度学習・更新されたPlaybookの内容は、サーバーを再起動しない限り、新しいセッションでも引き継がれます。 - 改善された応答への期待: この状態で再度「タスク管理について教えてください」と入力すれば、Generatorは既に存在するPlaybookの情報を活用して、初回よりも質の高い回答を生成することが期待できます(動画では再度の入力は行われていません)。
このように、ACE-ADKは「生成→フィードバック→内省→Playbook更新」のサイクルを通じてPlaybookを充実させ、その学習結果がセッションを跨いで利用されることで、エージェントが継続的に改善していく様子をデモンストレーションしています。
まとめ
本記事では、自己改善するLLMエージェントのためのフレームワーク「Agentic Context Engineering (ACE)」と、そのコンセプトをGoogle ADKで実装した「ACE-ADK」を紹介しました。
ACEは、Context CollapseやBrevity Biasといった既存手法の課題を、Playbookという動的な知識ベースと、Generator-Reflector-Curatorという役割分担されたアーキテクチャで解決します。ACE-ADKは、この強力なコンセプトをハンズオンで体験できる良いスターターキットです。
今後の展望としては、Playbookの統計情報(stats())を用いてあまり使われないBulletを自動的にアーカイブする仕組みや、複数のサイクルをバッチで実行する機能などが考えられます。
ご興味のある方は、ぜひリポジトリをフォークして、自分だけの自己改善エージェントを育ててみてください。
参考資料
付録: 論文と実装(ACE-ADK)の主な差分
ACE-ADKは論文のコアコンセプトをGoogle ADKで実装したスターターキットですが、論文で述べられているいくつかの機能は簡略化されています。
| 機能 | 論文 (Agentic Context Engineering) | 実装 (ACE-ADK) |
|---|---|---|
| Reflectorの反復的洗練 | 洞察抽出時に、複数回の反復的な自己洗練が可能。 | 1サイクルの分析とタグ付けのみを行う単一パス処理。 |
| Grow-and-Refine | 重複除去や枝刈りなど、Playbookの品質を維持する自動整理メカニズムを提案 [cite: 194-197]。 | BulletのCRUD操作は実装されているが、自動的な洗練ロジックは含まれていない。 |
| 並列Deltaマージ | 複数のDelta Updateを並行してマージできる可能性を示唆。 | SequentialAgentによる逐次処理。並列マージは考慮されていない。 |
| マルチエポック適応 | 同じクエリを複数回処理し、Playbookを段階的に強化できる。 | コアサイクルは1クエリ/1回実行。複数エポックは外部での制御が必要。 |
| 適応スコープ | オフライン/オンライン両方のシナリオへの適用を強調。 | 主にオンライン学習サイクルのデモンストレーションに焦点を当てている。 |
| フィードバックの利用 | 実行時のフィードバックのみで自己改善できる点を強みとする。 | オプションでGround Truthも利用可能だが、なければ実行時フィードバックに相当する分析で動作。 |