Scaling Recommendation Systems with Request-Level Deduplication
Authors: Matt Lawhon | Sr. Machine Learning Engineer; Filip Ryzner | Machine Learning Engineer II; Kousik Rajesh | Machine Learning Engineer II; Chen Yang | Sr. Staff Machine Learning Engineer; Saurabh Vishwas Joshi | Principal Engineer
At Pinterest, scaling our recommendation models delivers outsized impact on the quality of the content we serve to users. Our Foundation Model (oral spotlight, ACM RecSys 2025), for example, achieved a 100x increase in transformer dense parameter counts and a 10x increase in model dimension; translating directly into meaningful quality improvements across multiple recommendation surfaces.¹
But a 100x scaleup creates massive infrastructure pressure. Storage, training, and serving costs all threaten to grow proportionally unless you’re deliberate about efficiency. The single highest-impact technique we’ve deployed to hold costs in check across all three dimensions is request-level deduplication: a family of techniques that ensures we process and store request-level data once, not once per item.
In this post, we’ll walk through what request-level deduplication is, why it matters so much for modern recommendation systems, and how we applied it across the full ML lifecycle , from storage compression to training correctness and speedups to serving throughput gains.
Background
A request is triggered when a user opens their feed, kicking off the recommendation funnel:
- Retrieval: Aggregate user and request information into one or multiple embeddings, then fetch a large set of potentially relevant items from the entire corpus using techniques like nearest neighbor search.
- Ranking: Aggregate user, request, and item information to make predictions about relevance or engagement. Typically there are early-stage ranking models (which need cheap per-item inference since they score many items) and late-stage ranking models (which can afford more expensive per-item inference since fewer items are ranked).
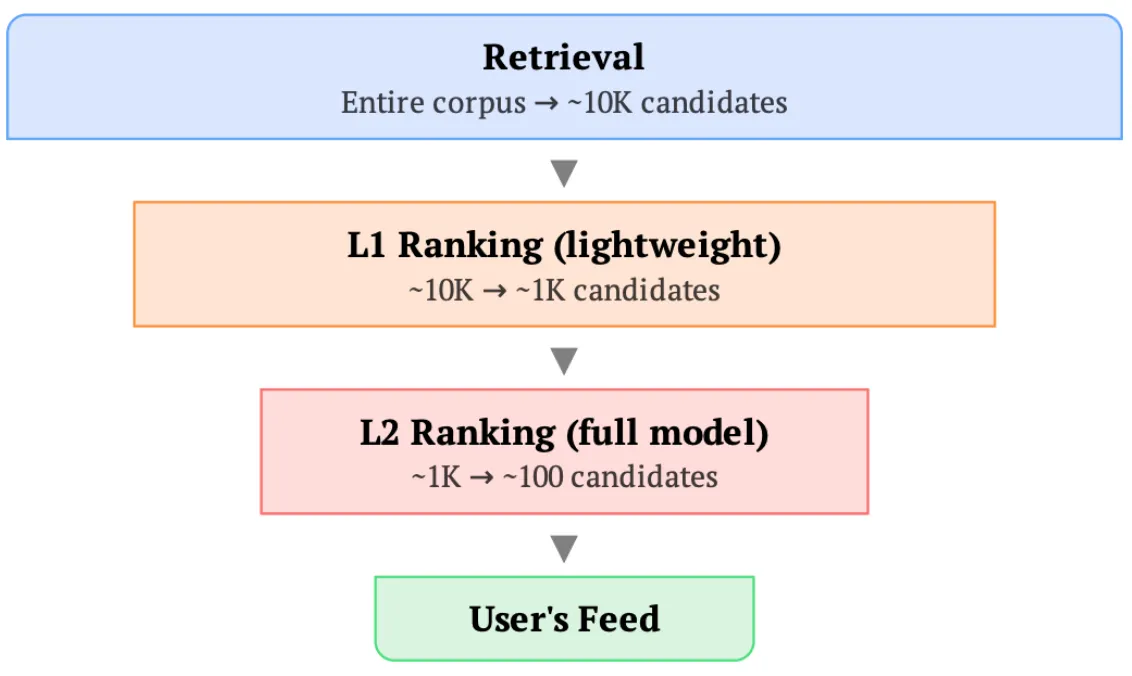
The same user data flows through every stage of this funnel, and within each stage, it’s duplicated across every item scored. Request-level deduplication refers to the category of techniques that eliminate this redundancy when storing, moving, or transforming this data.
The impact can be extremely high because:
- Request-level data is massive. It largely consists of user sequences, approximately 16K tokens encoding all actions a user has taken on the platform. These sequences power sequential user understanding components like the Pinterest Foundation Model and TransAct. Each sequence is duplicated identically for every candidate item scored, hundreds to thousands of copies per request.
Processing this data is expensive. The computation associated with user tower models in retrieval and user sequence understanding components in ranking represents a significant proportion of total recommendation system compute.

Storage
One of the key ways deduplication pays off is at the storage level. A row in a training dataset typically consists of [request/user, content item, engagement label], and we can have hundreds or thousands of content/engagement labels associated with a single request. Without deduplication, the same massive user sequence is stored redundantly for every single content interaction.

By leveraging Apache Iceberg with user ID and request ID based sorting (How Pinterest Accelerates ML Feature Iterations via Effective Backfill, Scaling Pinterest ML Infrastructure with Ray), we achieve 10–50x storage compression on user-heavy feature columns.² When rows sharing the same request are physically co-located, columnar compression algorithms handle the deduplication automatically.
Beyond raw storage savings, request-sorted data enables improved dataset tooling:
- Bucket joins: Matching keys are co-located, eliminating expensive shuffle operations.
- Efficient backfills: We can update only affected user segments rather than reprocessing entire datasets.
- Incremental feature engineering: Adding new request-level features becomes a localized operation: we can append new columns to existing row groups without duplicating the entire dataset.
Stratified sampling: Request-sorted data enables user-level sampling, ensuring training datasets maintain proper diversity without over-representing highly active Pinners.
Training
Addressing Independent and Identically Distributed (IID) Disruption
Early experiments with request-sorted data revealed 1–2% regressions on key offline evaluation metrics in our ranking models.² The root cause was the disruption of the IID assumption.

With IID sampling, each batch contains engagements spread across many users, yielding stable and representative statistics. With request-sorted data, batches become concentrated around fewer users, causing batch-level statistics to fluctuate dramatically based on individual user behavior. Each gradient update is computed from a less representative slice of the data: the model sees a noisier, more biased view of the training distribution, which slows convergence and degrades final quality.
The specific vulnerability lies in Batch Normalization (BatchNorm), which normalizes intermediate values by computing mean and variance across the batch. Standard BatchNorm computes these statistics independently on each device’s local batch. When batches are request-sorted and highly correlated, a batch dominated by a single power user will have dramatically different statistics than one with a casual browser.
Fix: Synchronized Batch Normalization (SyncBatchNorm)
SyncBatchNorm aggregates statistics across all devices before normalization. This effectively increases the “statistical batch size” used for computing means and variances, even though each device still processes its local request-sorted batch. The result is that normalization statistics are computed over a much more diverse set of users and requests, restoring the representative statistics that standard BatchNorm enjoyed with IID data.
In practice, this simple one-line change fully recovered the performance gap. The communication overhead of synchronizing statistics across devices was negligible compared to the training speedups gained from deduplicated computation.


With IID sampling, the probability that a randomly sampled in-batch negative is actually a positive for the anchor user is negligible: users engage with a tiny fraction of the total item corpus. With request-sorted data, however, batches are concentrated around fewer users, and each user may have dozens or hundreds of engagements grouped together. Many in-batch “negatives” are actually items the user engaged with, they’re false negatives. The false negative rate jumps from ~0% with IID sampling to as high as ~30% with request-sorted data, depending on the number of unique users per batch.²
Training the model to push apart items the user actually engaged with actively degrades retrieval quality.
Fix: User-Level Masking
To address this, we extended our existing identity masking to also exclude negatives that belong to the same user as the anchor. The standard InfoNCE loss with logit correction:
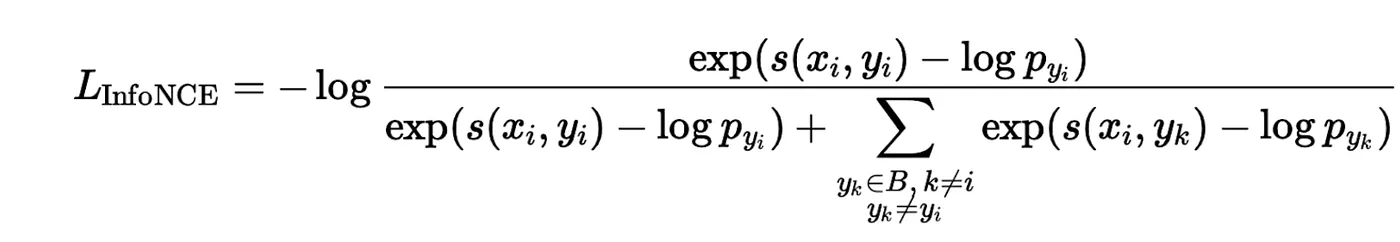
becomes:
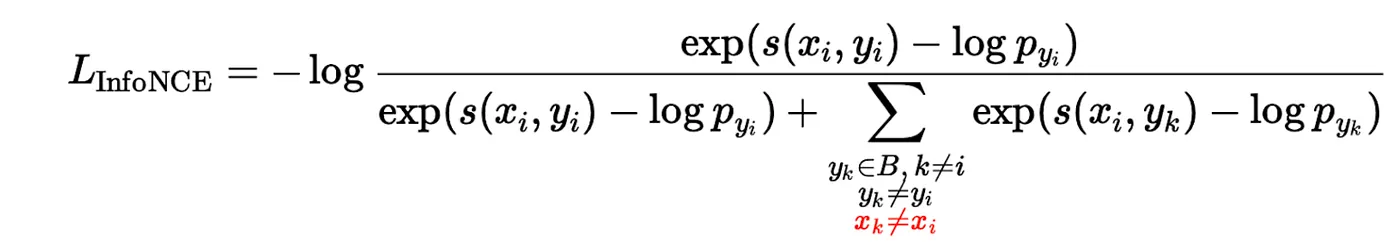
where:
- s(·,·) is the similarity function (e.g., dot product) between user and item embeddings
- x_i is the user embedding for the anchor engagement i
- y_i is the positive (target) item for engagement i
- y_k represents candidate negative items from batch B
- x_k is the user associated with candidate k
- p_y values are streaming frequency estimates (Yi et al., 2019) used for logit correction
- x_k ≠ x_i is the new constraint: only use engagements from other users as negatives
This simple masking change allowed us to successfully adopt request-sorted data for retrieval model training while preserving model quality.
Manifesting Training Speedups
The previous sections focused on correctness, ensuring model quality is preserved when switching to request-sorted data. Here we discuss how to actually realize the compute and memory savings that deduplication enables.
Data Loading
Our data loading infrastructure, shared across ranking and retrieval models, is designed to maintain deduplication as long as possible in the pipeline. All preprocessing and feature transformations operate on deduplicated request-level data. We only reduplicate (expand) at the very end, on GPU or directly in the model’s forward pass. This minimizes CPU-to-GPU transfer costs and memory allocation overhead.
Retrieval Models
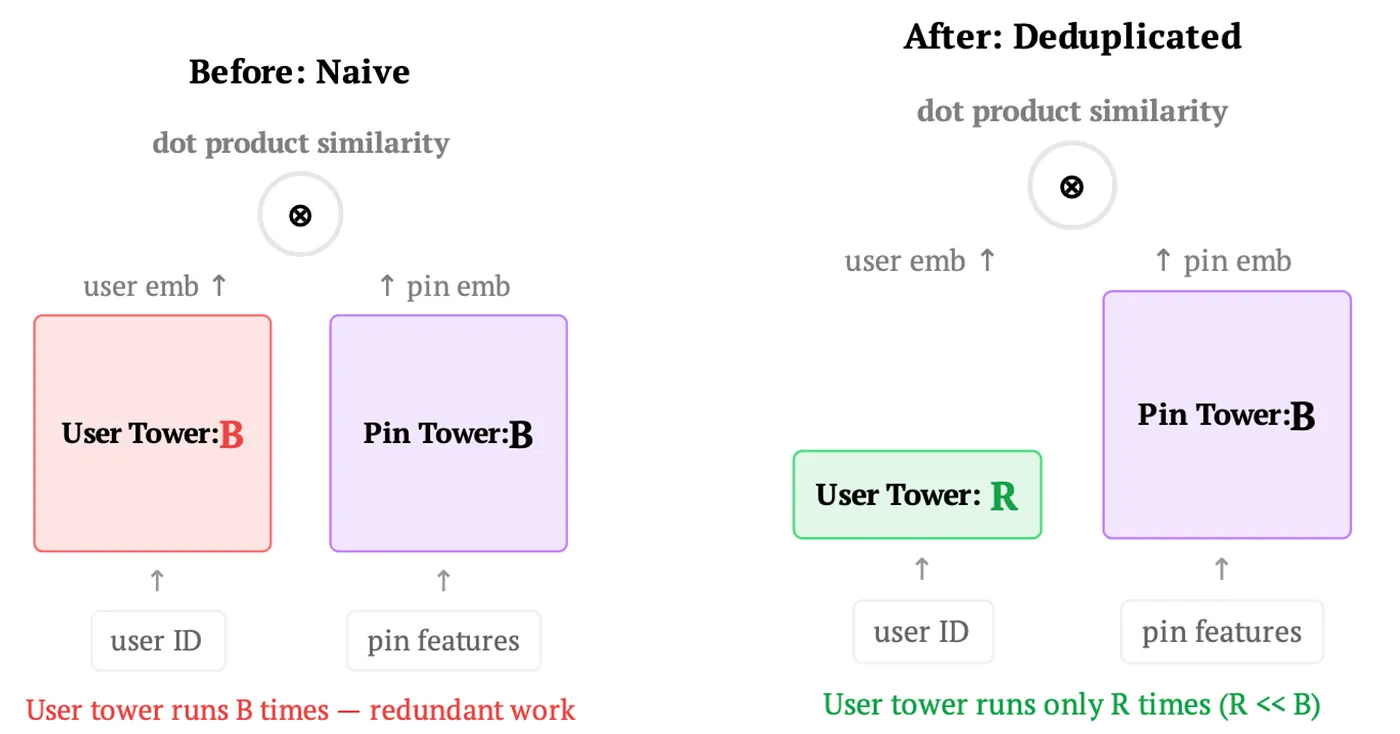
Achieving request-level compute deduplication in retrieval models is straightforward thanks to the two-tower architecture. Since the user tower has no item dependencies by definition, we rewrite the forward pass to run the user tower on the deduplicated batch of R unique requests rather than the full batch of B user-item pairs. The item tower continues to operate on the full batch. Gradients for the user tower are computed at the deduplicated level and appropriately accumulated.
Though conceptually simple, the savings compound in practice, memory allocation, I/O, and compute all benefit, particularly for large user sequence models where the user tower dominates training cost.
Ranking Models: Deduplicated Cross-Attention Transformer (DCAT)
Ranking models present a greater challenge because transformer architectures used for user understanding typically have item dependencies: each candidate item attends to the user history, coupling request-level and item-level computation.
To address this, we developed DCAT, described in detail in the Pinterest Foundation Model paper. The key insight is to separate the transformer into two components:
- Context: Apply the transformer to the user’s historical action sequence once per deduplicated request. The keys and values (KV) from each layer are cached.
- Crossing: Each candidate item performs cross-attention with the cached user history KV, reusing the deduplicated context computation.
This optimization, implemented with custom Triton kernels for both training and serving, achieved significant throughput gains over standard self-attention with FlashAttention.
Training Impact

Taken together, request-level deduplication delivered a 4x end-to-end training speedup for retrieval and a ~2.8x speedup for ranking (40% from deduplicated data loading compounded with a 2x gain from DCAT cross-attention).²
Serving
For retrieval, serving has always been correctly deduplicated by design: we embed the user once and search against the item index. No changes were needed.
For ranking, the DCAT architecture provides the same deduplication benefit at serving time as it does during training. The context transformer processes the user’s action sequence once per request, the key-value (KV) cache stores the intermediate representations, and each candidate item cross-attends to this cached context. This avoids redundantly recomputing the full user sequence for every item scored.
The result is a 7x increase in ranking serving throughput.² This is what made it possible to deploy a 100x larger model without proportional serving cost increases, absorbing the full Foundation Model scaleup while holding infrastructure budgets in check.
Conclusion
Request-level deduplication delivered impact across every layer of our ML lifecycle:
- Storage: 10–50x compression on user-heavy feature columns via Iceberg and request sorting²
- Training: 4x retrieval speedup and 2.8x ranking speedup from deduplicated data loading and DCAT²
- Serving: 7x throughput increase via DCAT and custom Triton kernels²
Three lessons stand out:
- Request-level deduplication is a cross-cutting technique. It improves storage, training, and serving simultaneously because the same fundamental redundancy exists at every layer.
- Simple fixes unlock big wins. SyncBatchNorm and user-level masking are minimal code changes with outsized impact. The hardest part was identifying the problems; the solutions were straightforward.
- Impact compounds across the stack. Storage compression enables faster data pipelines, training speedups accelerate experimentation velocity, and serving throughput reduces infrastructure cost, freeing capacity for the next round of model scaling.
¹ Pin Foundation Model, ACM RecSys 2025. ² Pinterest Internal Data, Global, 2025.
Acknowledgements
This work reflects joint efforts across multiple teams at Pinterest. We’d like to thank: Devin Kreuzer, Piyush Maheshwari, Hanlin Lu, Xue Xia, Abhinav Naikawadi, Yuming Chen, and Aditya Mantha (Personalization); Kousik Rajesh, Xiangyi Chen, Zelun Wang, Hanyu Li, Pong Eksombatchai, Jaewon Yang, Yi-Ping Hsu, and Hongtao Lin (Applied Sciences); Raymond Lee, Sheng Huang, Neha Upadhyay, Nazanin Farahpour, Henry Feng, Alekhya Pyla, Rubin Fergerson, and Shengtong Zhang (ML Platform); Shivin Thukral, Joseph Bongo, Zach Barnes, and Yang Cao (Search); and Anya Trivedi, Akshay Iyer, and Rui Liu (Notifications).