Building Local LM Desktop Applications with Tauri
[

A guide on combining the llama.cpp runtime with a familiar desktop application framework to build great products with local models faster
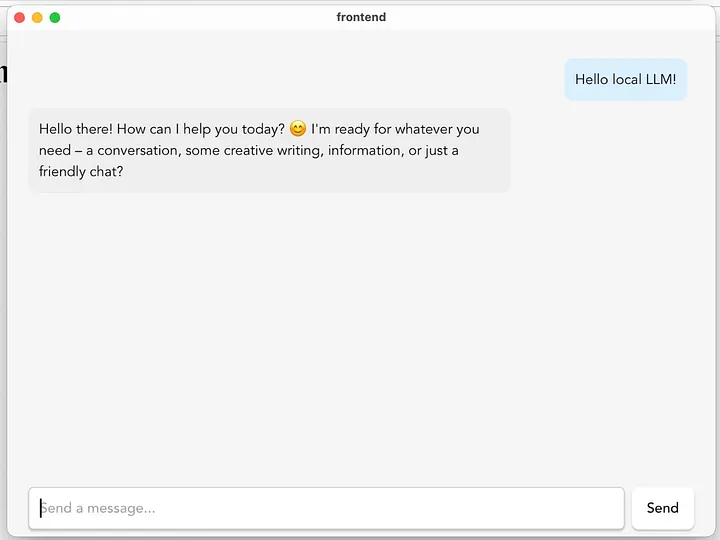
Local LM application we are building with Tauri and llama.cpp
The world of local LMs is incredibly exciting. I’m constantly impressed by how much capability is now packed into smaller models (around 1B–7B parameters) and I’d argue it’s becoming increasingly possible to perform some of the basic tasks I typically rely on models like Claude or GPT-4o for using these lighter alternatives (drafting emails, learning basic concepts, summarising documents).
Several key tools in the current landscape such as Ollama, LM Studio, and Jan make it easier for people to experiment with and interact with local models. As an engineer, I really admire these tools and how much they’ve enabled me to explore my own curiosity. That said, I can’t help but feel that their developer-oriented workflows and design may limit broader accessibility, preventing non-developers/everyday people from fully experiencing the power of local models.
Beyond that, I’ve noticed a bit of a gap between the ability to run local models and the creation of truly polished, user-friendly applications built on top of them.
Upon realising this, it led to a fun little Sunday afternoon hacking project: bundling a local language model and an appropriate inference runtime into a compact desktop application.
Chosen Runtime: Llama.cpp
When a language model (or any AI model for that matter) receives an input, the process of executing the necessary computations to generate an output is called inference. As you might imagine, modern models perform a vast number of operations during inference (matrix multiplication, I’m looking at you). Simple, standalone for-loops aren’t nearly fast enough to meet the performance demands of real-time inference. That’s why running these models efficiently requires a high-performance runtime optimised for speed and parallel computation.
llama.cpp, developed by Georgi Gerganov, is a lightweight C++ implementation of Meta’s LLaMA models (in addition to many other popular models) designed to run entirely on the CPU with minimal dependencies, enabling efficient inference on upper-end consumer hardware. Its super easy to setup and there are prebuilt binaries available, making it even better for a project like this since we could have this inference capability if we can just find a way to package and run these binaries with our app.
Initial Approaches
To kickstart a simple local LLM project, I downloaded the prebuilt binaries for llama.cpp available at their repo. For this article and my experiments, I used Gemma3–1b. There’s a great guide by Unsloth on running and finetuning it here.
Once this was working, I ran the llama-server binary and I found myself quickly in the territory of spinning up a React app then vibe coding up a simple chat UI, updating on any messages sent to llama-server.
Pretty straightforward, very developer friendly approach except this isn’t a desktop application just yet.
Initially I scratched my head a little bit in terms of thinking about how I would go about packaging the runtime with a desktop app. Naively, I figured since Go enables developers to easily compile static binaries, perhaps I could put together a simple proxy that is responsible for starting and talking to llama.cpp throughout the app duration. My desktop application (at the time written in Wails) would then trigger the spawning of the go binary which assuming some uniformity in terms of folder structure, should be able to determine the location of the necessary binaries to run.
I dabbled a little bit in this approach to the point of a working Go proxy and frontend only to have the following shower thoughts accompany me later that night:
- Why exactly do I need to Go proxy, particularly when my requests aren’t different to how I would normally call the llama-server? For the simplicity of what I was trying to do, there didn’t seem to be an immediate benefit to having a proxy and perhaps this was a classic piece of over-engineering (for now).
- Perhaps part of the issue is actually also thinking about how to actually call the processes in JS/TS. This is a more familiar idea to application developers and gives them a greater insight as to how the interfacing works under the hood.
Integrating with Tauri
Before we get into things, please feel free to keep tauri-local-lm open in another tab. Here you can find a navigable codebase which goes through the findings from this article.
Tauri is a framework for building lightweight, cross-platform desktop applications using popular web technologies. You can follow their setup and installation guide here. Creating a Tauri app and getting things up and running should be as simple as the following:
npm create tauri-app@latest
cd <name-of-tauri-project>
npm run tauri dev
Now for the fun part — integrating llama.cpp with our Tauri app!
Sticking with our approach of using prebuilt llama.cpp binaries, we’re lucky that the Tauri ecosystem provides a well-defined method for embedding external binaries.
A sidecar is any binary bundled alongside your application that can be executed to add functionality. In our case, we’ll be adding the llama-server binary as a sidecar.
Inside the src-tauri directory, create a folder called runtime. We can pop our llama.cpp binaries in here:

Binaries located in the src-tauri/runtime/llama-cpp/bin folder of our project
You’ll notice I’ve added the suffix aarch64-apple-darwin to all the llama.cpp binaries. This is because when Tauri builds your application, it needs to select the correct binaries based on the target architecture. In my case, I’m focusing on Macs for now.
And don’t forget, we’re lucky to live in the age of LLMs! A quick prompt can generate a script to handle suffixing for you. I’ve included a sample of the script I used here — it not only appends the correct suffix to your binaries but also updates both tauri.conf.json and default.json accordingly (we’re about to get to why we need to do this in a moment). You can find your architecture name by running rustc -Vv .
The tauri.conf.json file specifies configuration settings for your Tauri application. We’ll need to specify our external binaries in here using the externalBin property:
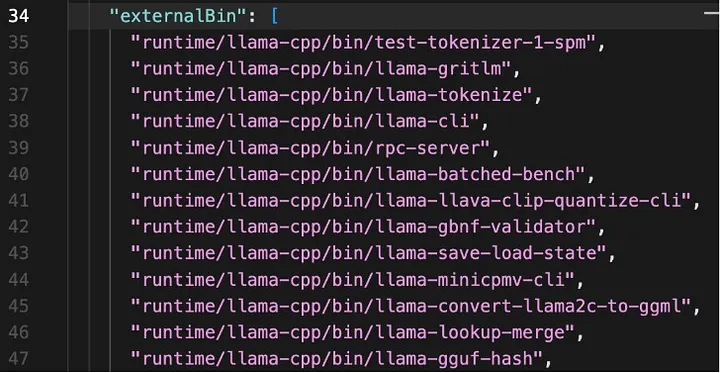
External binaries specification within tauri.conf.json
After completing these steps, we’ve essentially told Tauri about the existence of the llama.cpp binaries and where to find them. But there’s one more thing — we’ll also want to be spawn our runtime from JS/TS code in the webview. In order to do this, we need to first complete a couple of important prerequisite steps:
- Installing the Tauri shell plugin, enabling us to handle execute/spawn of external binaries
- Expose this shell usage capability to the webview for our respective binaries
By running npm run tauri add shell, you can add the shell plugin to your project. However, we still need to ensure we enable our frontend to have the capability to spawn the necessary binaries. To do this, we can modify the default.json file in src-tauri/capabilities:
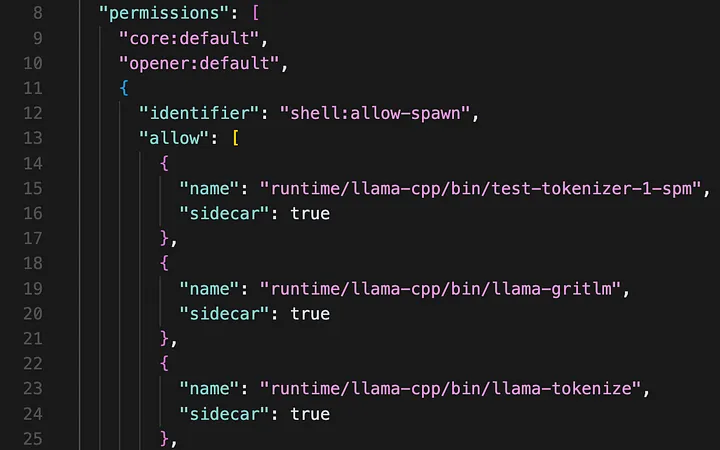
src-tauri/capabilities/default.json
Once we’ve done this, we can add the necessary logic in our frontend to actually spawn the llama-server sidecar from our Tauri webview. If you’ve created your Tauri app with a React template, you could throw the following lines inside of your App.tsx. This will just spawn the llama-server process when your component is loaded.
import { Command } from '@tauri-apps/plugin-shell';
import { useEffect } from 'react';
useEffect(() => {
const startLlamaServer = async () => {
const command = Command.sidecar('runtime/llama-cpp/bin/llama-server', ['-hf', 'ggml-org/gemma-3-1b-it-GGUF']);
const child = await command.spawn() }
startLlamaServer();
}, [])
Once the Llama server has spawned, you could handle messages from your UI text inputs/text areas to then send a request to llama-server:
const conversationHistory = messages.concat(userMessage)
.map((msg: any) => `<start_of_turn>${msg.role}\n${msg.content}<end_of_turn>\n`)
.join('');
const response = await fetch('http://127.0.0.1:8080/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json', },
body: JSON.stringify({
prompt: `
n_predict: 128, })
});
You can also stream responses via Websockets and passing the stream: true param in the request however, I’ve omitted this for simplicity for now and it can be found in the reference repo a little later.
Towards a Working Production Build
To then package our app into something we can distribute, we need to run npm run tauri build. This builds a distributable package for the target platform you are currently on, with the option to specify additional targets. Inside your src-tauri/target/release/bundle folder you should be able to see an executable, download manager, app file etc that you can go on to run your app.
Whilst all might seem good and well, there are some edge case scenarios that would be great to handle before dishing out our app.
- Assuming you are using models from HuggingFace, the first time you run the app on a new machine, the model files will need to be downloaded and installed locally. Whilst we haven’t specified the default directory for this, llama.cpp will place it into a cache directory based on its own internal file structure (for Macs, I believe this is
~/Library/Caches/llama.cpp). With the way we’ve designed the app in this article so far, its quite possible we have a user ready to go and utilise the chat interface in our frontend. However, if this message is sent without llama-server having the model loaded and ready to serve requests, we’ll be delivering a poor user experience - In addition to the above point, models generally take a moment to load in the llama.cpp runtime. During this time, requests can’t be served.

Health checks to llama-server can help us out
Fortunately, we can resolve this situation by doing a heartbeat/ping to llama-server to the /health endpoint. This will only return success if the model is installed and loaded in the runtime. We will want to use a setInterval call to help us ensure we do this periodically. You could implement it like how I’ve done this as the following:
import { useState } from "react";
const [isServerReady, setIsServerReady] = useState(false);
const checkServerHealth = async () => {
try {
const response = await fetch('http://127.0.0.1:8080/health');
return response.status === 200;
} catch (error) {
return false; }};
const healthCheckInterval = setInterval(async () => {
const isHealthy = await checkServerHealth();
setIsServerReady(isHealthy);
}, 2000);
By storing whether the server has spun up in a React state, you can determine whether you want to show your chat UI or not. This is a pretty handy way to deliver a better user experience for users.
Performance Analysis
Llama.cpp returns some pretty useful metrics about the performance of an LM on the hardware it’s run on. Specifically, when using the llama-server binary, these stats can be accessed in the response body.
For benchmarking purposes, I’ve listed some relevant specs below. Mac users can find this information by going to About This Mac > System Report:
Machine: Apple MacBook Air (M1, 2020)CPU: Apple M1 (8-core: 4 performance, 4 efficiency)GPU: Integrated 7-coreRAM: 8GB
Storage: 256GB
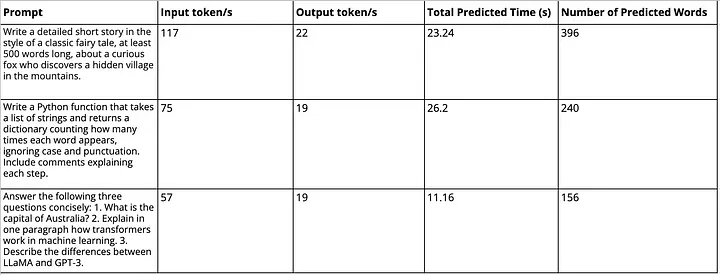
Performance of gemma3–1b on hardware specs listed above
Based on this table, we can see that gemma3–1B model averages around 20 tokens/sec (or roughly 13 words/sec) on my hardware specified above.
Compared to 7B models (and above), the 1B model we’ve used throughout this article isn’t as strong when it comes to advanced tasks like coding or complex reasoning. That said, its ability to summarise, draft basic content or code snippets, and serve as a surface-level oracle for general knowledge is commendable. A friend and I actually used it to revise RLC circuits for an exam recently and it did a solid job explaining the role of resonance in those systems.
Based on that experience, I’d say smaller models could still have a place in desktop applications which aim to rethink simple, everyday functionality — think along the lines of personal note-taking apps or lightweight educational tools. You can view the LM outputs to the prompts in the table above right here.
For more advanced use cases, you may want to consider running a larger model (7B–14B) with Tauri. Additionally, there’s still the limitation of hardware. Based on the specs listed above and rule of thumb about VRAM to model size, you’re likely to hit a ceiling around 2–3B. Anything larger tends to struggle so there’s a clear limitation without higher-end hardware.
Challenges and Future Direction
Whipping up this project gave myself (and hopefully you) a lot of insight as to how integration between these high performance runtimes, local models and familiar desktop app technologies can be combined to create powerful, local LLM applications. However, there are some challenges and pain points I noted along the way.
Firstly, the way I handled setting up binaries for this project was very hacky. Throughout this article, we pretty much just dragged and dropped binaries that worked for our platform. Of course, we could download binaries for other targets as well to support different platforms but then you have issues such as management of binary versions and how you handle them in your code repo start to pop up.
Beyond llama.cpp, there’s still a lot of infrastructure work needed to build robust RAG or agentic systems — things like effective model management, monitoring VRAM usage and preventing edge case runaway processes which could cause multiple instances of the model or runtime to be spun up. These kinds of issues highlight that while powerful, this setup still requires quite a bit of engineering effort to make reliable and production-ready.