How Uber Scaled Data Replication to Move Petabytes Every Day
Uber prioritizes a reliable data lake, which is distributed across on-premise and cloud environments. This multi-region setup presents challenges for ensuring reliable and timely data access due to limited network bandwidth and the need for seamless data availability, particularly for disaster recovery. Uber uses the Hive Sync service, which uses Apache Hadoop® Distcp (Distributed Copy) for data replication. However, with Uber’s Data Lake exceeding 350 PB, Distcp’s limitations became apparent. This blog explores the optimizations made to Distcp to enhance its performance and meet Uber’s growing data replication and disaster recovery needs across its distributed infrastructure.
Distcp is an open-source framework for copying large datasets between different locations in a distributed manner. It uses Hadoop’s MapReduce framework to parallelize and distribute the copy tasks across multiple nodes, allowing for faster and more scalable data transfers, particularly in large-scale environments.
Figure 1: High-level Distcp architecture.
The Distcp architecture comprises several key components:
- Distcp Tool: Identifies files, groups them into blocks (Copy Listing), defines distribution across mappers, and submits the configured Hadoop job to YARN.
- Hadoop Client: Sets up the job environment, determines which mappers handle specific blocks (Input Splitting), and submits the job to YARN.
- RM (Resource Manager): The YARN component that schedules tasks, receives the Distcp job, allocates resources, and delegates execution to the Application Master.
- AM (Application Master): Monitors the MapReduce job life cycle, requests resources (containers) from the RM for Copy Mapper tasks, and consolidates file splits at the destination.
- Copy Mapper: Performs the actual data copying of assigned file blocks, running in a container managed by the YARN Node Manager.
- Copy Committer: Merges the copied blocks to assemble the final files in the destination file system.
Figure 2: Diagram showing Distcp from the /src/ directory to the /dest/ directory.
Figure 2 shows how Distcp replicates three files from the source directory /src/ to the destination directory /dest/ using the components described earlier. The source directory contains three files—File 1, File 2, and File 3—all of the same size. The Copy Listing task, running on the client side, identifies these files and splits each into two blocks (chunks). The Input Splitting task then distributes these file blocks across three mappers.
- Map 1 receives one block from File 1 and another from File 2.
- Map 2 handles one block from File 3 and one from File 1.
- Map 3 processes one block from File 2 and another from File 3.
The Copy Mapper tasks then copy these blocks from the source to the destination directory. After replication, the Copy Committer task runs in the AM, merging the corresponding blocks of each file to recreate the final three files in the destination directory.
HiveSync was initially built on the open-source Airbnb® ReAir project. It supports both bulk (allowing large amounts of data copy in one pass) and incremental replication (syncing incremental updates as new data arrives), keeping Uber’s data lakes in sync across both HDFS™ (Hadoop Distributed File System) and cloud-based object storage. It uses Distcp for large-scale data replication.
Figure 3: HiveSync architecture: Data replication workflow using Distcp.
Figure 3 shows how Hivesync server listens for copy requests from the source Hive cluster. For sizes larger than 256 MB, it submits Distcp jobs to an executor. Multiple workers (asynchronous threads) then prepare and submit these jobs in parallel to YARN using the Hadoop client. A monitoring thread tracks the progress of each job, and once the job is completed successfully, the data is available in the destination cluster.
By Q3 2022, HiveSync faced significant scaling challenges as the daily data replication volume surged from 250 TB to 1 PB in just one quarter.
One factor contributing to this rapid increase was the concentration of data writes in a single data center. In 2022, Uber shifted to an active-passive data lake architecture for cost savings, moving from evenly distributed data generation to having the primary on-premise data center handle 90% of data generation and most batch-compute tasks. This significantly increased the load on the HiveSync server replicating data from the primary to the secondary region. The SRC (Single Region Compute) project’s impact will be discussed separately.
Another factor was onboarding all on-premise Hive datasets to HiveSync. With the new active-passive model, HiveSync became essential for disaster recovery, ensuring data generated in one region was replicated in another geographic region. This required scaling HiveSync to cover Uber’s entire data lake. In just one quarter, the number of datasets managed by HiveSync grew from 30,000 to 144,000, as new datasets were onboarded. This more than doubled the number of replication requests.
As a result of these, the number of daily replication jobs skyrocketed from 10,000 to an average of 374,000, far outpacing the system’s ability to process them. This led to a substantial backlog, making it increasingly difficult to meet the promised SLAs for replication delays. Specifically, the P100 replication lag SLA of 4 hours and the P99.9 SLO of 20 minutes became challenging to uphold at this new scale.
Additionally, the scale of replication requests was expected to increase significantly as HiveSync took on a crucial role in migrating Uber’s data lake from on-premises to cloud regions. This shift was predicted to nearly double the scale and volume of copy requests, putting more pressure on HiveSync to manage the increased workload and optimize its data replication processes to meet the challenges of operating in a cloud infrastructure.
We’ve introduced the following enhancements to Distcp to customize it for our scaling demands. These optimizations dramatically improved Uber’s data replication scale and efficiency.
- Shifting the resource-intensive Copy Listing and Input Splitting tasks to the Application Master, which reduced job submission latency by 90% by mitigating HDFS client contention.
- Parallelizing Copy Listing and Copy Committer tasks that significantly cut down job planning and completion times.
- Implementing Uber jobs for small transfers that helped in eliminating 268,000 container launches daily, optimizing YARN resource usage.
Let’s take a closer look at each of them in detail –
During one of the incidents, we noticed under heavy load on the system, an increase in file system latency led to a corresponding rise in Distcp copy-listing latency.
Figure 4: Increased HDFS FSUtils latency directly affects Distcp Copy Listing task.
When we analyzed the thread dumps during the spike, we found that most threads were stuck waiting for a lock held by the HDFS client for Remote Procedure Calls. This approach doesn’t scale well in a highly multithreaded environment.
Figure 5: Threads blocked on RPC calls.
In a typical Distcp submission flow, several components rely on the HDFS client: the Distcp worker for data comparisons, the Distcp tool for Copy Listing, and the Hadoop Client for Input Splitting. As the number of Distcp executor threads increases, so does the number of parallel HDFS client users.
Figure 6: Multiple parallel calls from different copy job requests create contention on the HDFS client.
We found that while Distcp scales data copying well, it also handles file planning and listing tasks on the client side. This preparation phase, where files to be copied are identified (Input Splitting), caused bottlenecks because it relied on a shared HDFS client, which was also used by other HiveSync components. As data volumes and the number of Distcp workers grew, JVM-level locks in the HDFS client became a major issue, leading to thread contention as parallelism increased. This caused delays, with Copy Listing alone responsible for 90% of the job submission latency.
The problem was made worse by the large number of NameNode calls, which are proportional to the number of files being copied—particularly problematic with large directories.
To ease the load on a single HDFS client, we shifted the resource-heavy tasks of Copy Listing and Input Splitting from the HiveSync server to the AM.
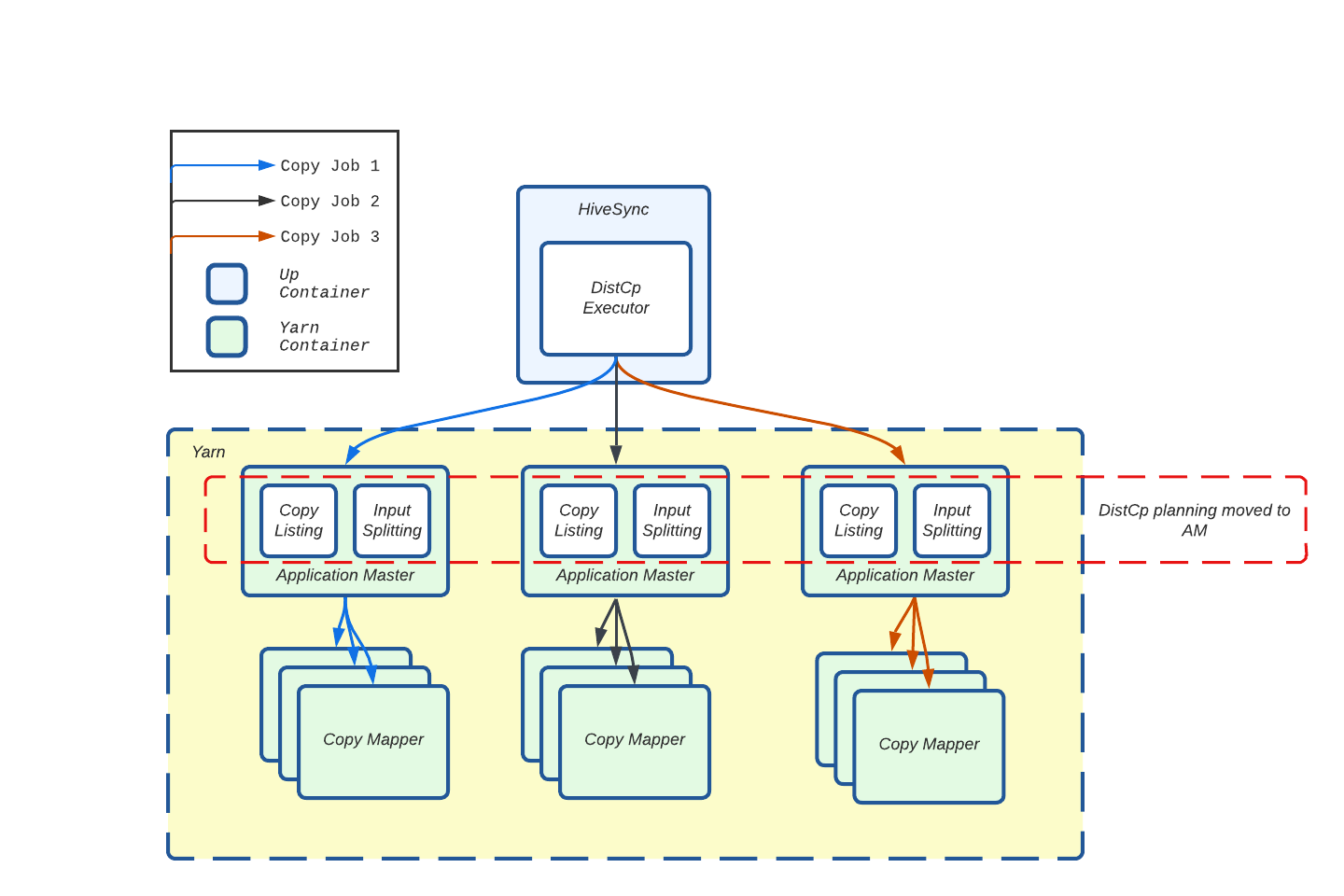
Figure 7: Moved Copy Listing and Input Splitting processes from Hive Sync server (Client) to AM.
Now, each Distcp job performs Copy Listing on its own AM container, which significantly reduces lock contention on the HiveSync Hadoop client. It helped us achieve a 90% reduction in Distcp job submission latency.
Figure 8: Observed 90% reduction in Distcp job submission time.
DistCp tool runs the Copy Listing task to generate filesystem blocks for the files to be copied. These blocks are written into a sequence file, forming a list of file chunks to be copied from the source to the destination cluster by the Copy Mapper task. During this process, the main thread sequentially calls the namenode using the getFileBlockLocations API for files larger than a specified chunk size to create file splits (chunks). It also retries when file status checks fail, making this the most resource-intensive part of DistCp.
Figure 9: p99 latency averaged at around 10 mins for the busiest replication server even after moving this task to Application Master.
We observed that multiple files can be listed in parallel and written in any order in the sequence file. However, the chunks of each file need to stay together and in order, because the Copy Committer algorithm uses them to merge the copied file splits at the destination. Building on this idea, we parallelized the file system namenode calls to reduce Copy Listing latency by assigning a separate thread to create splits for each file, adding them to a blocking queue, with a separate writer thread sequentially writing the blocks to the sequence file. This approach helped improve the Distcp job completion time.
Figure 10: Copy Listing task V2 workflow.
In Figure 10, the listing function uses multithreading to retrieve files from the source cluster via namenode calls. Each thread handles the creation of blocks for one file, allowing parallel processing of multiple files. For example, /src/file1 (1684 MB) is split into two chunks: the first chunk (/src/file1/part0) has 4 HDFS blocks of 256 MB each, and the second chunk (/src/file1/part1) has 3 blocks (2 of 256 MB and 1 of 128 MB). The listing thread synchronously adds these chunks to a blocking queue, while a separate writer thread regularly polls the queue and writes both chunks to the sequence file in order. For fast failure handling, if any thread fails, the main thread stops the process and retries the Distcp job. After the listing function completes and all items in the queue are written to the sequence file, it updates the job status using the Status Updater.
We achieved a 60% reduction in the p99 average Distcp listing latency and a 75% decrease in the maximum latency across all HiveSync servers by using 6 threads.
Figure 11: Improvement in Copy Listing latency on a Hive Sync server with 6 threads.
After the Distcp Copy Mapper tasks complete copying file splits from the source to the destination directory, the Copy Committer Task in the AM merges these splits into full files. For directories with over 500,000 files, this process can take up to 30 minutes. The open-source version merges file chunks sequentially, leading to slower performance.
To address this, we parallelized the file concatenation process, with each thread responsible for merging one file at a time. The Sequence file created during the Copy Listing process is used to identify the order of blocks of individual files that need to be merged at the destination.
Figure 12: Copy Committer task V2 workflow.
In Figure 12, mappers retrieve the file splits created during the Copy Listing process from the Sequence File and copy them to the destination directory under /dest/. Each concatenation thread (Concatenator) gathers the splits for a specific file and merges them to create the final file. The three splits of file 1 (/dest/file_part0__, /dest/file_part1, and /dest/file_part2) are combined to form /dest/file1 at the destination. Similarly for file 2 and file 3. For quick failure handling, if any thread encounters an issue, the main thread halts the process and retries the Distcp job
Figure 13: Mean concat latency dropped by 97.29% using 10 threads.
Around 52% of Distcp jobs submitted by HiveSync servers require only one mapper to copy less than 512 MB and fewer than 200 files. Although these small jobs finish quickly, a significant portion of time is spent on environment setup (allocating a new container in yarn and JVM startup time) rather than copying itself.
Figure 14: More than 50% of Distcp jobs are assigned a single mapper each.
To address this overhead, we leveraged Hadoop’s “Uber jobs” feature, which eliminates the need to allocate and run tasks in separate containers. Instead, the Copy Mapper tasks are executed directly within the Application Master’s JVM, reducing unnecessary container allocation.
Figure 15: Uber Job workflow.
In Figure 15, the AM determines whether a job qualifies as an Uber job. If it does, the Copy Mapper task is executed locally within the AM’s JVM. Otherwise, the AM requests a container via the Node Manager and runs the Copy Mapper task there. Once the task is complete, the AM initiates the Copy Committer task to merge file splits at the destination.
We enabled Uber jobs with the following configurations:
- mapreduce.job.ubertask.enable: true
- mapreduce.job.ubertask.maxmaps: 1 (ensures only 1 mapper is used)
- mapreduce.job.ubertask.maxbytes: 512 MB (limits data copy to 512 MB)
By implementing this approach, we eliminated the need for around 268,000 single-core container launches per day, significantly improving YARN resource usage and job efficiency.
The improvements we made to the Distcp tool at Uber have greatly boosted our incremental data replication abilities across both on-premise and cloud data centers. Thanks to these changes, we’ve increased our data handling capacity across on-premises by 5 times in just one year, without running into any incidents related to scaling.
Figure 16: Scale of Hivesync across on-premise and cloud data centers.
In recent months, we’ve expanded Hivesync’s capabilities to support the replication of on-premise data lake to a cloud-based data lake, as highlighted here. Enhancements to Distcp have played a crucial role in handling the scale of this migration. To date, we’ve successfully migrated over 306 PB of data to the cloud.
Figure 17: Data migrated from on-premise to cloud via the Hivesync service.
We introduced several key metrics that significantly improved observability. These metrics provided insights into Distcp job submission times on both the client and Yarn AM sides, job submission rates, and the performance of key Distcp components like Copy Listing and Copy Committer tasks. We also tracked metrics such as maximum heap memory usage of Hadoop containers, p99 Distcp copy rate per job, and overall copy rate. This enhanced visibility allowed us to better monitor and understand the replication rate of our service, and it played a crucial role in mitigating and diagnosing multiple incidents.
We faced several challenges during the rollout of the changes to production servers. One challenge was OOM (out of memory) exceptions in AM. Rigorous stress testing helped in identifying optimal memory and core usage. We added metrics to detect OOM issues, which helped us later in identifying optimal YARN resource configurations for memory-intensive copy requests.
Another issue was a high job submission rate from HiveSync. Lowering submission latency increased the job submission rate, which often led to “Yarn Queue Full” errors. To prevent overloading YARN, we implemented a circuit breaker in HiveSync that temporarily pauses new submissions until retries are successful. We added metrics to detect such events, enabling real-time monitoring and adjustments to Yarn queue capacity as needed. Managing high copy rates, though efficient, caused high network bandwidth usage and required careful tuning to balance performance with resource limits.
We also faced AM failures due to a long-running Copy Listing task. Initially, the Copy Listing and Input Splitting parts were moved to the setup phase of the AM. This caused problems because the RM expects the AM to send regular heartbeat signals. Since the heartbeat sender only starts after the setup is done, and the Copy Listing task sometimes takes longer than 10 minutes, it causes timeouts. To fix this, the Copy Listing task was moved to the output committer’s setup, which happens after the heartbeat sender has already started, preventing timeouts.
Looking ahead, the team is focusing on several enhancements centered on parallelization, better resource utilization, and network management. These include:
- Parallelizing file permission setting
- Parallelizing input splitting
- Moving compute-intensive commit tasks to the Reduce phase to boost scalability
- Implementing a dynamic bandwidth throttler
Additionally, we plan to contribute an open-source patch for these optimizations. The Uber Hivesync team remains focused on solving data replication challenges, where even small improvements can lead to significant gains at our scale.
Cover Photo Attribution: “Server room with grass!” by Tom Raftery is licensed under CC BY 2.0.
Apache®, Apache HadoopⓇ, Apache Hive™, Apache Hudi™, Apache Spark™, Apache Hadoop YARN™, and Apache Hadoop HDFS™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.