What is an Agent?
Welcome to 2025’s edition of “term so overused to mean so many different things that it starts to lose any real meaning in conversation because everyone is confidently using it to refer to different things.”
If you are a builder trying to build agentic solutions, this article might not be for you. This article is for those who have been in a meeting, a board room, or a conversation, with someone talking about AI agents and are either (a) not really sure what an agent is and how it is different from the generative AI capabilities we’ve seen so far, (b) not really sure the person using the term knows what an agent is, or (c) might have thought that they knew what an agent is until reading the first sentence of this article.
While we will reference Windsurf in this article to make some theoretical concepts more tractable, this is not a sales pitch.
Let’s get started.
The very basic core idea
To answer the title of this article, an agentic AI system can simply be thought of as a system that takes a user input and then performs alternating calls to:
-
An LLM (we call this the “reasoning model”) to decide what action to take given the input, potential additional automatically retrieved context, and the accumulating conversation. The reasoning model will output (a) text that reasons through what the next action should be and (b) structured information to specify the action (which action, value for input parameters of the action, etc). The output “action” could also be that there are no actions left to be taken.
-
Tools, which don’t have to have anything to do with an LLM, which can execute the various actions (as specified by the reasoning model) to generate results that will be incorporated into the information for the next invocation of the reasoning model. The reasoning model is essentially being prompted to choose amongst the set of tools and actions that the system has access to.
This creates a basic agentic loop:

Really, that’s it. There’s different flavors of an agentic system given how this agent loop is exposed to a user, and we’ll get into that later, but you are already most of the way there if you understand the concept that these LLMs are used not as a pure content generator (a la ChatGPT) but more as a tool-choice reasoning component.
This term “reasoning” is also overused - in the agentic world, it has a very specific meaning. It means using an LLM to choose what action to be taken next, i.e. what tool should be called with what parameters.
The term “reasoning” has also been used by models like OpenAI’s o1, and reasoning there means something completely different. For these LLMs, “reasoning” refers to chain-of-thought prompting. The idea there is that the model would first output intermediate steps before trying to provide the end response to the query, attempting to mimic more of how a human would work through a question than relying on pure pattern-matching magic. With these models, there are no tools being called (as in the agentic world), just outputs for the LLM being generated in a way that appears as if it is chaining together multiple thinking invocations (thus “chain-of-thought”).
The other misattribution of “agentic” is to what can be referred to as “AI workflows.” For example, someone might build an automation or workflow that takes in a raw document, uses an LLM to do object recognition, then cleans those extracted elements, then uses another LLM to summarize the elements, and then adds the summary to a database. There are multiple LLM calls, but the LLMs are not being used as tool calling reasoning engines. We are specifying what LLMs should be called and how ahead of time, not letting the LLM decide what tools should be called realtime. This is simply an automation, not an agent.
Super simple example to understand agentic vs non-agentic: let’s say you ask an AI system for a recipe to make a pizza. In the non-agentic world, you’d just pass that prompt into an LLM and let it generate a result:
In an agentic world, one of the tools the agent might have could be to retrieve a recipe from a cookbook, and one of the recipes is for a pizza. In this agentic world, the system will use the LLM (the reasoning model) to determine that, given the prompt, we should be using the “recipe tool” with input of “pizza” to retrieve the right recipe. This tool will then be called, the text of that recipe will be outputted, and then the reasoning model will determine, using the outputs of this tool call, that there is no more work to be done, and it will complete its “loop.”
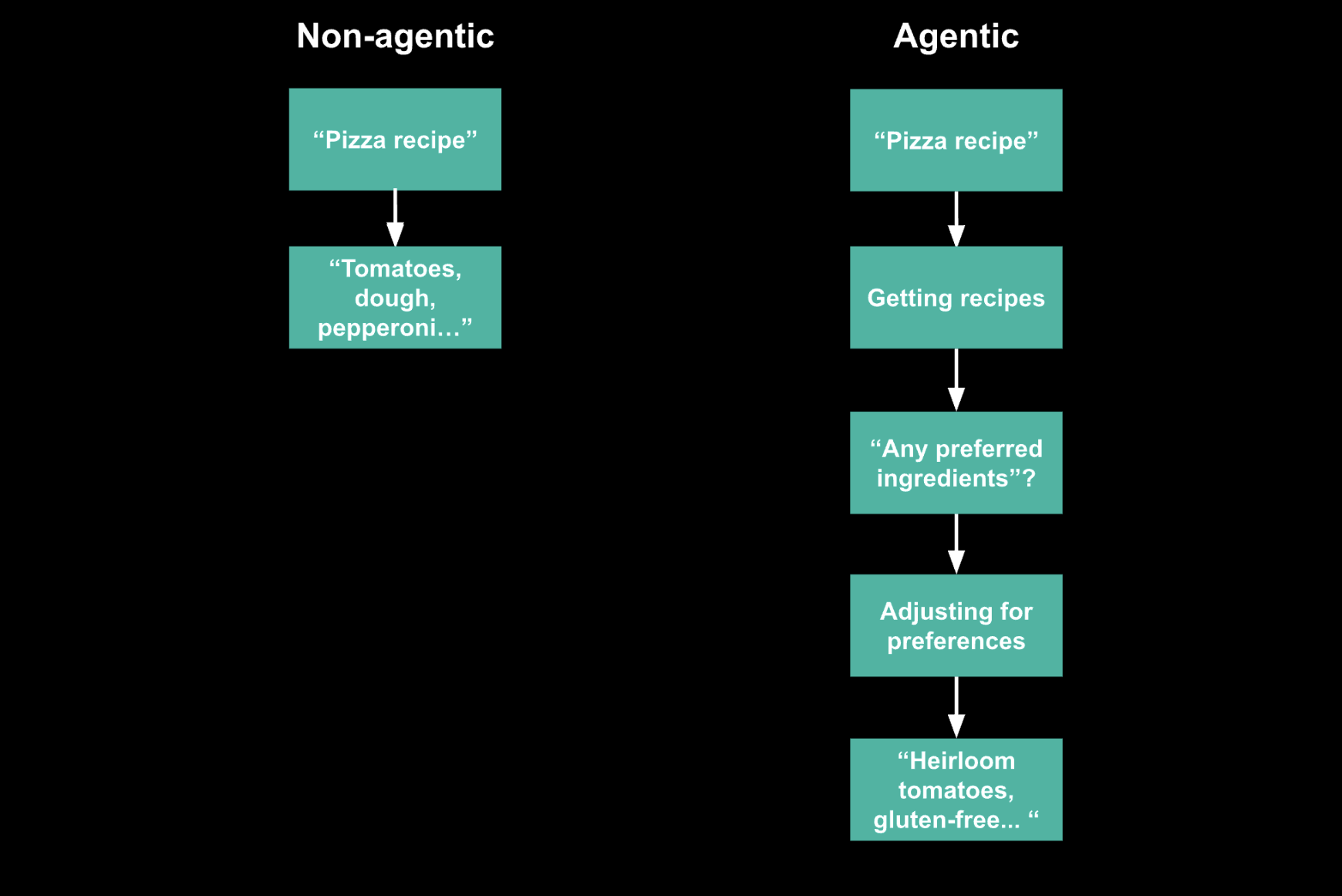
While the difference might now make sense, you might ask - why is this even interesting? This just seems like a technicality in approach.
Well, there are a few reasons why this is interesting:
-
Imagine that the example was a bit more advanced. Something like “get a pizza recipe using healthy ingredients in the style of the city of Napoli.” There’s a chance that the non-agentic system will be able to get something reasonable by the sheer nature of the generative model, but as these requests get more detailed and more layered, it gets more unlikely that a single call to an LLM will have the capacity to nail the request. On the other hand, an agentic system might first reason to use a tool that calls an LLM to describe how the city of Napoli makes pizza, then reason to use a tool to perform a web search on what ingredients would classify as healthy, and only then reason to use the tool that retrieves the recipe, with the information of the past couple of steps informing potential configurable inputs to this final tool. This decomposition of steps should feel natural since it is how we as humans do work, and should decrease the variance in potential results because the agent is using tools that we understand better and have more control over. While not guaranteed to work, this agentic approach gives the AI system a better chance of getting things right than the non-agentic approach.
-
The tools that we can provide the agent can help cover for things LLMs are not good at. Remember, LLMs are stochastic systems that operate purely on patterns in natural language. They have no intrinsic understanding of non-textual concepts. LLMs are not good at math? We can add a calculator tool. LLMs are not aware of current time? We can add a system time tool. LLMs are unable to compile code? We can add a build tool. Now, the reasoning model (the LLM in the agentic world) does not need to actually know intrinsically how to do math, tell time, or compile code. Instead, it just needs to know when it is appropriate to use a calculator, look up the system time, or try to build some source code, and to be able to determine what the right inputs to those tools should be. Knowing how to call these tools is much more tractable and can be based on textual context.
-
The tools can actually make change to the state of the world, not just provide a textual response. For example, let us say in the pizza example, we wanted the AI to send the pizza recipe to my sister instead. Perhaps the agent has access to tools to access my contacts and to send a text. The agent would be able to go into a loop - first reason to retrieve the recipe, then reason to retrieve my sister’s contact information, and then reason to send the text. The first couple of steps might have been achievable with some very smart RAG, but the last step? That ability to actually take action, not just generate text, makes agentic systems have the potential to be very powerful.
Congrats, you now know what an agent is! But there’s a bit more context and information to make you dangerous in conversations around “agents”...
How we got here and why now
Before we get to mental models that you can use to have meaningful discussions about agentic systems, we will do a quick aside on how we got here and add some clarity on the types of AI-based tools given their approach towards agentic. We’ll do this in the context of our domain, software engineering, so that this isn’t completely abstract.
If you can remember the world a few years ago, humans actually did work before generative AI tools. That work could be represented as a timeline of actions. In software engineering, this could range from doing some research on StackOverflow to running a terminal command to actually writing some code:
Then, with the advent of LLMs, we started getting systems that could do scoped tasks very well. ChatGPT to answer a question, GitHub Copilot to autocomplete a couple lines of code, etc. These tools could be trusted because they satisfied two conditions simultaneously:
-
They solved a problem that mattered to the user (ex. every developer hates writing boilerplate, so autocompleting that text is valuable)
-
LLM technology was good enough that they could solve these problems at a robust enough level for the user to trust it for that particular application (ex. developer doesn’t like an autocomplete suggestion? No worries, they can just keep typing and move on).
This latter condition is actually very critical. People have, for years, been constructing incredibly impressive demos of LLM-based systems solving insanely complex tasks. However, many of these are just demos, and can’t be productionized and trusted, which leads to a general disconnect between hype and reality, and an ensuing trough of disillusionment. Take an example like summarizing a pull request. Obvious value to a user (noone likes writing a pull request description), but think about the level of accuracy required for a user to trust it long term. The first time the AI gets the description wrong? The user will forever check all of the files and come up with a description themselves, nullifying the value of the tool. The bar of robustness required for that use case is very high, and perhaps not met with the technology of today. That being said, while this LLM technology is imperfect, it is also rapidly improving, so the frontier of task complexity that can be solved for at a robust enough level is also improving. One day AI will be able to robustly write pull request descriptions.
I digress. This initial intersection between useful and possible was restricted to what I would refer to as “copilot-like” systems. These were AI systems that would perform a single call to an LLM to solve a very scoped task, like responding to a prompt or generating an autocomplete suggestion. The human was always in the loop reviewing the result before “accepting” it, so the potential concern of the AI running loose was not an issue. The major issue was the problem of hallucination, a term that refers to the model providing a result that is inaccurate due to a combination of being intrinsically confident (these models were trained over text on the Internet, and everyone is confident on the internet) and not having the requisite knowledge to ground the response in reality (these models are just super complex pattern matching algorithms at the end of the day). So, these copilot-like systems were improved upon by more-and-more powerful approaches to retrieval augmented generation (i.e. “RAG”), which is a fancy way of saying that these systems would first retrieve relevant information to ground a response for the user’s query, augment the user’s query with this information, and pass that cumulative information to the LLM for the final generation. This access of knowledge to AI systems that could perform scoped tasks defined the first couple of years of LLM-based applications - the “copilot” age:
These copilot-like, non-agentic systems were the ones that were driving real value at a consistency level that a user would trust the system long-term. That being said, it is not that the idea of an “agentic system” is anything new.
The first popular framework for agents, AutoGPT, actually came out early 2023, soon after the launch of ChatGPT. The approach towards agents here was having the agentic loop be something that happens autonomously, so all the user has to do is provide the prompt, let the agent do its thing, and then review the result. Essentially, because these systems had access to tools and performed multiple LLM calls, they were much more long-running and could complete tasks much larger in scope than the copilot-like systems:
However, while AutoGPT remains to be one of the most popular GitHub repositories of all time, agents created with the framework did not actually take off. A year later, Cognition came out with Devin, marketed as a fully functional AI developer that would replace human software developers. Again, a fully autonomous agentic system, with some incredibly powerful tools, yet today is only capable of solving relatively simple problems.
What happened? If agents are meant to be so powerful, why have users primarily gotten value from RAG-powered non-agentic copilot-like systems as opposed to these agentic systems?
Well, remember the intersection between “useful problem” and “technology is ready to be robust enough”? That’s the general challenge with these autonomous agentic systems. While these autonomous agents are where the world is clearly heading, the LLMs are likely not good enough today to complete the complexities of these tasks end-to-end without any human involvement or correction.
This reality brought upon a new approach to agents, one grounded in a recognition that there is going to be some balance between what the human should do and what the agent should do. To distinguish from the autonomous approach to agents, we will refer to these as collaborative agents, or AI flows for shorthand.
Tactically:
-
There needs to be clear ways for the human to observe what the flow is doing as it is executing so that if the flow is going off-base, the human is able to correct it earlier. In other words, bringing back some of the “human-in-the-loop” collaborative aspects of the copilot-like systems.
-
These flows must operate within the same environment that the human would do their work. Most attempts at autonomous agents, because they work independently from the user, are invoked from a surface that is disparate from where the user would do the work if they were to do it manually. For example, Devin is invoked from a webpage when in reality a developer would write code in an IDE. While this might be fine in a world where agents could do literally anything, by not living within the surface where the human would be doing their work, these autonomous agentic systems would be unaware of what the human does manually. Therefore, they would miss a lot of implicit context that can be derived from these actions. For example, if the agent lived in the IDE, then it would be aware of recent manual edits, which would implicitly inform what the agent should do next.
In other words, in this reality, it is important for the human to observe what the agent does, and it is important for the agent to observe what the human does.
Coming back to the intersection between “interesting problem” and “robust enough tech,” the required bar of robustness for a collaborative agentic approach is significantly lower than that of an autonomous agentic approach. This is because the human can always correct the AI on intermediate steps, be required to approve certain actions of the AI (ex. executing terminal commands), and be responsible for reviewing changes in real time.
This is why this is the approach taken by all of today’s generally accessible agentic applications that are conclusively adding value, such as Windsurf’s Cascade, Cursor’s Composer Agent, and GitHub Copilot Workspaces. With flows, both the human and the agent are operating on the same state of the world, all the time:
We go through all of these lengths just to distinguish between an autonomous agent and a collaborative agent, because they are actually drastically different approaches towards building an “agentic” system. Different amounts of human-in-the-loop, different levels of trust required, different methods of interaction, etc. Because the term “agent” is overused, there is frequently a lot of chatter about building autonomous agents and pointing to agentic systems like Windsurf’s Cascade as evidence for agents working, when in reality these two approaches are drastically different.
How to mentally dissect “an agentic system”
Ok, finally what you have been waiting for - a quick checklist incorporating everything we have covered to be able to (a) reason about a conversation about “agents” and (b) ask questions that get to the heart of the technology. Many of these questions could become articles on their own, but I will try to provide a useful first level.
Question 1: Is the system being discussed really agentic?
As it has become clear, too many people call systems “agentic” when they really are not. Is the LLM being used as a tool calling reasoning model, and are there actually tools being called? Or is it just some chain-of-thought reasoning or something else that is using the same terms, just with different meanings?
Question 2: Is it autonomous or collaborative?
Is the approach to the agentic system one in which the agent is meant to work in the background without human involvement, or is it one where the agent has the capacity to take multiple steps independently, but is embedded in existing systems for work and still has a human in the loop?
If the former category, ask the follow up question - are the models actually good enough today to reason over the scale and complexity of the data and tools in question at a consistency that users would be able to rely on the overall agent? Or is the suggestion to make an autonomous agent one that sounds great in theory, but not actually practical?
Question 3: Does the agent have all of the inputs and components to be intrinsically powerful?
This starts getting into the meat of what differentiates different implementations of agents (especially collaborative agents, or flows) that are attempting to solve for the same task.
Question 3a: What tools does the agent have access to?
Not only the list of tools, but how are these tools implemented? For example, Windsurf’s Cascade has a unique approach to performing web search by chunking and parsing website copy. Also, is it easy to add your own unique tools? Approaches like the Model Context Protocol (MCP) from Anthropic are aiming to standardize a low-friction approach to new tools being incorporated into existing agentic systems.
Question 3b: What reasoning model does the agent use?
It is important to remember to evaluate the LLM on its ability to perform tool calling well, not whether it is the best according to standard benchmarks on various tasks and subjects. Just because a model is really good at answering coding questions does not mean that it would be really good at choosing the right tools to solve coding-related tasks in an agentic manner. There is no objectively best LLM that is the best reasoning model for all tasks, and while a model like Anthropic’s Claude 3.5 Sonnet has historically been one of the best for tool calling, these models are rapidly improving. Therefore, it is useful to ask the question of whether it would be more appropriate to make sure that the agent could have optionality to use different kinds of models.
Question 3c: How does the agent deal with existing data?
What data sources can the agent access? Is the agent’s access to these data sources respecting access control rules that exist for the user (especially in the world of collaborative agents)? Sometimes the answer is not as simple as the data source itself - for codebases, does the agent only have access to the repository that is currently checked out in the user’s IDE, or can it access information in other repositories to help ground the results. The latter could add value given how distributed code is, but then questions around access become more important.
Overall, the agentic approach changes the paradigm on how to think of the data retrieval problem. In copilot-like systems, you only have a single call to an LLM, so you only have a single chance to do retrieval, which leads to more and more complex RAG systems. With agentic, if the first retrieval returns poor results, the reasoning model can just choose to do another retrieval pass with different parameters, repeating until it is determined that all relevant information has been collected to take action. This is much more similar to how a human would look through data. Therefore, if the conversation gets too deep around RAG, parsing, and intermediate data structures, ask the question - are we overcomplicating this for the agentic world? More on this a bit later…
That being said, if there is structure in data, it is fair to ask how the information in these data sources is processed. For example, we deal with codebases and code is highly structured, so we can do clever techniques like Abstract Syntax Tree (AST) parsing in order to smartly chunk the code to make it easier for any tool that is trying to reason or search over the codebases. Smart preprocessing and multi-step retrieval are not mutually exclusive.
Question 3d: How does the collaborative agent, or flow, capture user intent?
Are there any implicit signals that can be captured by what the human user is manually doing that would never be encoded explicitly? Now, the agent may not be aware of what is said at the water cooler, but it is often surprising how much more of a valuable and magical experience can be created by “reading the mind” of the user. In our world, this intent can be found in what other tabs the user has open in the IDE, what edits they just made in the text editor, what terminal command they just executed, what they have pasted in their clipboard, and a whole lot more. This comes back to lowering the activation energy to using the agent - if every time the user is expected to spell out every detail that could be derived from these implicit signals, then the user’s bar of expectation on quality of the AI’s results will be higher.
Question 4: What makes the user experience of this agent really good?
So far, we have talked about all of the factors that would affect the quality of the agent’s results. You will likely find conversations about agentic systems focused on these factors, but anyone serious about creating an agentic system that is actually adopted by users should pay attention to all of the axes of user experience that would make it more seamless to use the agent, even if nothing about the underlying agent changes. Many of these axes of user experience are not trivial to build, so should be thought through.
Question 4a: What is the latency of this agentic system?
Imagine that two agentic systems do the same thing for a particular task, but one does it in an hour while the other does it in a minute. If you knew that the systems would definitely complete the task successfully, maybe you don’t care as much about the time difference because you would just do something else in the meantime. But if there was a chance that the agent would be unsuccessful? You would very much prefer the latter agent, because then you would see that failure more quickly, and perhaps change some things about the prompt, give the agent some more guidance, etc. This latency problem has actually been one of the main challenges for fully autonomous agents, which historically have taken longer to complete tasks than the human manually doing the work themselves; unless the autonomous agent hits a very high success rate, it would just not be used.
There are two reasons to call out latency explicitly. First, agent builders often add complex, slow tools to improve quality without thinking about the impact to user experience and thinking through that tradeoff. Second, improving latency is a very hard problem at every part of the stack - model inference optimization? prompt construction to maximize caching? parallelizing work within a tool? It usually takes a whole different skill set of engineers to improve latency.
Question 4b: How does the user observe and guide the agent?
This is the big benefit of a collaborative agent over an autonomous one, but the execution is rarely trivial. For example, if a coding agent can make multiple edits across multiple files in the IDE, how can the developer effectively review these changes (much different than looking at a single autocomplete suggestion or reviewing the response in a chat panel)?
Similarly, people take time to build up context on best practices for doing particular tasks in a particular environment. What UX can you build that allows the human to guide the agent to these best practices? For example, Windsurf’s Cascade can take in user-defined rules or be guided to known context using a simple way to tag this context. Yes, the goal for any agent is to be capable of doing anything by itself, but if it is easy for the human to make the agent’s job easier, then the agent will be able to do higher quality work faster.
Question 4c: How is the agent integrated within the application? This all comes down to polish on how to invoke the agent and how to utilize its outputs. The popularity of ChatGPT has made a chat panel the default method of invoking any AI-based system. While this may be one way, it does not have to be the only one. For example, Windsurf’s Cascade can be invoked in other ways, such as a simple button to explain a block of code, and context can be passed to Cascade in many ways that don’t require copy-pasting text, such as Previews allowing for console logs and UI components to be passed to Cascade.
Question 4d: How is the agentic experience balanced with non-agentic experiences?
This one might be unexpected, but not everything needs to be agentic. For example, if a developer is just trying to make a localized refactor, they should use some combination of Command and Tab, both non-agentic “copilot-like” experiences that are fast and highly effective for these kinds of tasks. Agents are the new frontier, but just because we have a new hammer doesn’t mean that every problem is a nail! It is often useful to just ask “do we need to build an agent for this task?”
Again, we are only scratching the surface here, but this checklist should help you have conversations about agents, ask questions that get to the heart of what is important, and inject some realism into ideas.
The Bitter Lesson
But, one last thing. I’ve separated this because if there is just one question you end up utilizing from this post, it would be this one: “Are we violating the Bitter Lesson?”
The Bitter Lesson is derived from the eponymous article by Richard Sutton, and the main (rephrased) takeaway is that more compute, more data, and generally more scale of technology will always eventually lead to systems that will outperform any system that relies on human-defined structure or rules. We saw it with CNNs outperforming hand-crafted rules for edge and shape detection in computer vision. We saw deep search and then deep neural networks outperform any rule-based computer systems on chess, go, and more complex games. Even LLMs are an example of this trend, outperforming any “traditional” NLP methods.
With agents, we again have the potential to forget the Bitter Lesson. We might think that we know more about a particular use case, so we would need to spend a lot of time crafting the right prompts or make sure we smartly choose which subset of tools are valuable or try any other litany of approaches to inject “our knowledge.” At the end of the day, these models will continue to improve, compute will continue to get cheaper and more powerful, and all of these efforts will be naught.
Don’t fall into the trap of the Bitter Lesson.
Conclusion
That’s all! You’ve now learned the 101s of an agentic system. If you want to learn this more in video format and see software development agents in action, you can check out this course that we made in partnership with the team at DeepLearning.ai.
As mentioned at the top, this was not meant to be a sales pitch, but if you did find this useful and have a better understanding on the world of “agentic” AI, then maybe it is worthwhile to consider trying Windsurf for yourself, even if you are not a developer.
If you're curious about how Cascade could transform your team's development workflow and drive tangible business value, the ROI one-pager below provides key insights into productivity gains, cost savings, and strategic advantages that teams are experiencing with our agentic assistant.