The Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink
Introduction
Introduction
Data drives every decision we make at Grab. As our operations scale, so does our need for robust, real-time data ingestion and processing frameworks. Enter Hugo: our self-service data platform that has long empowered teams to seamlessly route data into our Data Lake. Today, Hugo is evolving. We have taken previously siloed onboarding workflows and transformed them into one seamless, unified journey to truly democratize data ingestion and maximize efficiency.
Data drives every decision we make at Grab. As our operations scale, so does our need for robust, real-time data ingestion and processing frameworks. Enter Hugo: our self-service data platform that has long empowered teams to seamlessly route data into our Data Lake. Today, Hugo is evolving. We have taken previously siloed onboarding workflows and transformed them into one seamless, unified journey to truly democratize data ingestion and maximize efficiency.
In this blog, we’ll share how Hugo turns complex engineering hurdles into a frictionless, self-service reality. By moving away from siloed workflows, we’ve achieved a unified pipeline experience where one-click RDS CDC and self-service Kafka ingestion are the new standard.
In this blog, we’ll share how Hugo turns complex engineering hurdles into a frictionless, self-service reality. By moving away from siloed workflows, we’ve achieved a unified pipeline experience where one-click RDS CDC and self-service Kafka ingestion are the new standard.
Background
Background
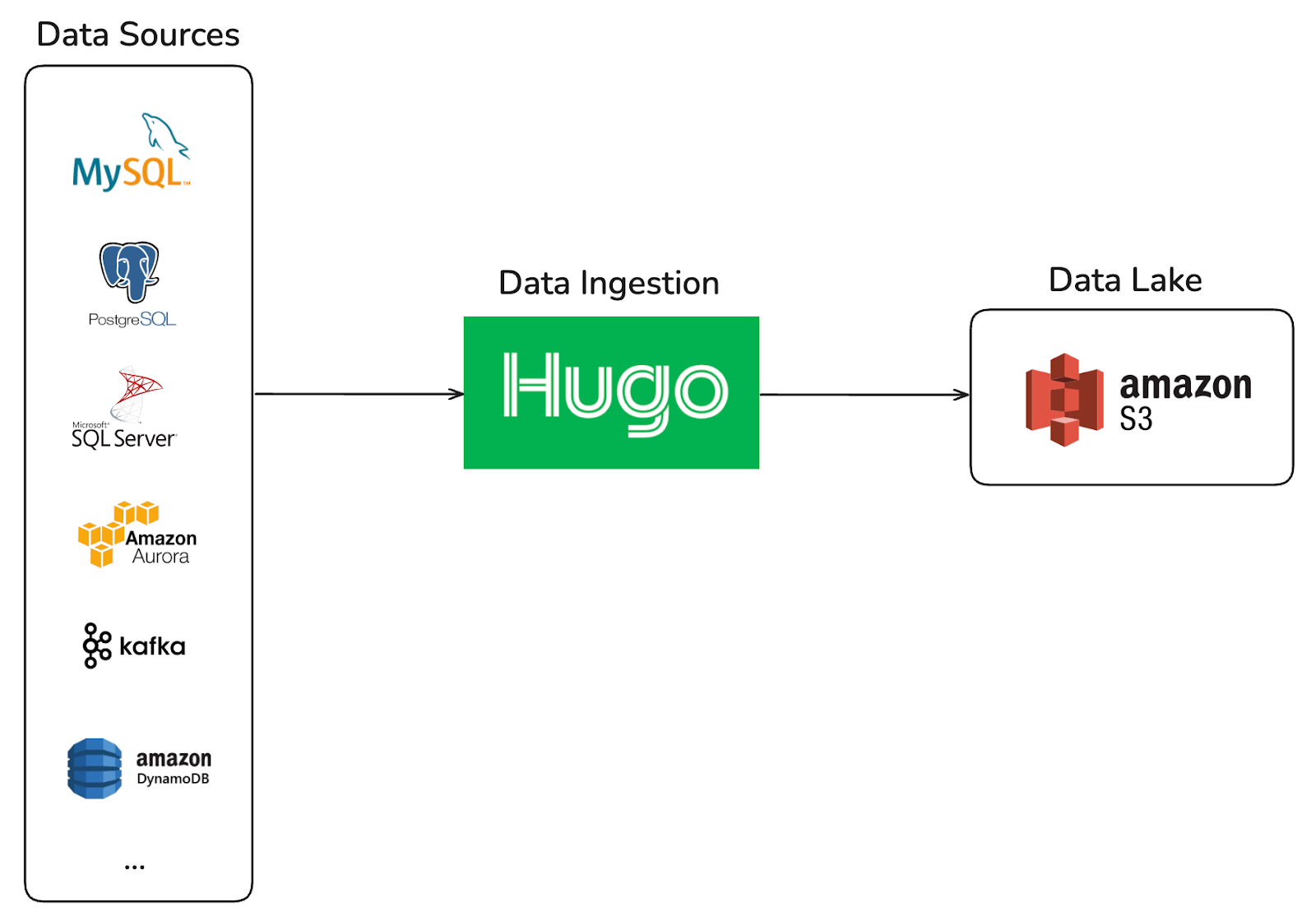
Figure 1. Hugo - Ingests data from every source into Grab's data lake.
Figure 1. Hugo - Ingests data from every source into Grab's data lake.
Hugo was originally designed as a self-service platform for batch-oriented data ingestion into the Data Lake, built on a single computation engine, Spark. It provided a centralized and streamlined onboarding experience for data sources such as MySQL, Aurora, PostgreSQL, and DynamoDB.
Hugo was originally designed as a self-service platform for batch-oriented data ingestion into the D...