Is S3 faster than a file system?
One of the most interesting things that used to happen to me when I was working at AWS was hearing from customers who told me that they "preferred to use S3 because it was faster than EFS". This was really funny to me because it's untrue, but it's also the experience of so many developers. Why is this.
It's first important to define what we mean when we talk about "speed" of storage solutions. Storage solutions define their speed in two different axes: latency and throughput. "Latency" is the time that it takes for an individual operation to complete, and "throughput" is the number of operations (measured in either count or bytes transferred) that can complete on a system within a given second.
Users, however, measure speed a different, much simpler, way. They run <SOMETHING> (this will differ per user) and measure the wall-clock time of that thing to actually complete.
This is the truth of all products, you can work night and day on features and benchmarks, but your customers *do not care*. They just want the thing that they are trying to build to work well.
Last week, we talked about how S3 is [speculated] to be hard-drive based storage and EFS (now, S3 Files) is [speculated] to be SSD-based storage. As a result, the *cost* of EFS is much higher (>10x), but the raw latency to access data on EFS is much faster.
Now, I'm a storage engineer, so for me "speed" immediately translates to latency. Let's look at a latency diagram (and I'm sorry, but these will not be to scale today):
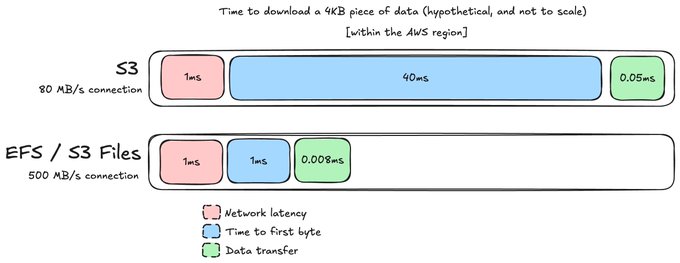
[aside: An interesting, but unimportant twist is that S3 throttles individual connections much more heavily than EFS does, so not only is it faster time-to-first-byte, but it's also faster transfer. Also consider this diagram simplified since, of course, there could be overlap.]
It's important to note that there are several components of latency that we should be thinking about that come together to make the final number. There is network latency (how far away your client is from the service), there is "time to first byte" (how long it takes the service to find and locate the data that you want to read, and then "transfer latency" (how long it takes the networking equipment to literally transfer the requested bytes to the user).
If you look at this, it seems obvious that users should think of EFS as the "faster" service, right? The latency is SO MUCH lower.
I've thought deeply about this paradox for many years. It didn't click until recently when I was having a discussion with @ovaistariq about how they handle global performance with Tigris Metal. We, at Archil, need to make sure that our service is available *in the same data centers* where our customers are running to get good performance, which is a big cost on our business. When I asked how he thought about managing this, he told me something surprising -- this wasn't a problem for them.
Tigris has the ability to rack-and-stack their own storage servers in centralized data centers around the world, and then let customers like Railway connect to centralized servers -- rather than needing to place them in the Railway data centers. This is a HUGE advantage. Let's talk about why this is possible.
Our graph above is for a 4 KB read from a file, but what happens if we run a different kind of workload?
[This is a bit tortured, so excuse me.] Let's say that rather than reading a 4KB file, we want to read a 1 MB file in 4KB chunks in some random order. Now, this turns into two different things in the S3 world and the file system world.
In the S3 world, you *probably* just store the entire 1MB file in RAM. This is because you, the application author, knows that you're going to read the entire file. In the file system world, each 4 KB read needs to go to the file system to be served because Linux does *not* know that you are going to read the whole file. Rather than one operation, this is 256 operations.
[aside: NFS and other protocols side-step this problem at small data sizes with "readahead" where they ask the server for a lot more bytes than requested by the user, so we're ignoring that here.]
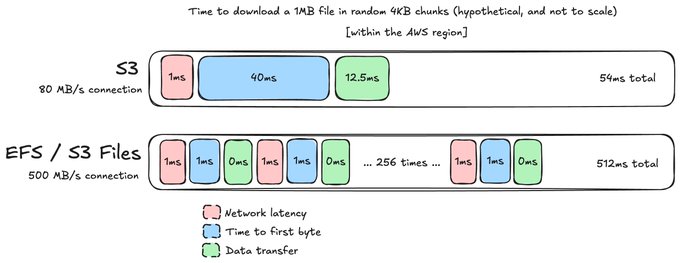
Woah! Suddenly, even though each individual file system operation is *much* faster than S3, you start to see how the "wall clock time" experienced by the user makes it look like a *slower* service.
The root cause here, as with all things, is the protocol. Linux doesn't have the semantic information to understand what your application is trying to accomplish from a high-level goal, so it translates it into the smallest pieces. Whereas when you use S3, you *architect* your application around the storage, and specifically design it to eliminate duplicate requests.
Now, here's the really weird part. Let's say that you're doing this computation in different geographic regions globally (or in AWS and a sandbox provider), but your data is sticking in the AWS region it was created in. This is going to increase the *network* latency of getting to the service. Or you're doing local development.
The cross-US latency of a network request from us-east-1 to us-west-2 is about 60ms from https://www.cloudping.co/. How does that affect things?
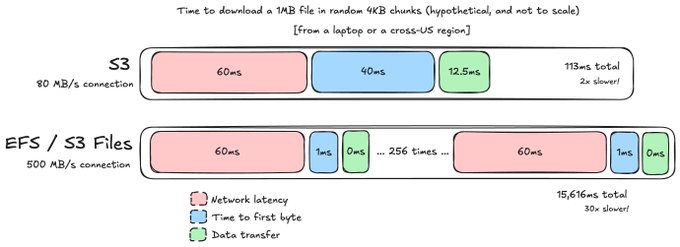
Obviously, you don't want your application talking cross-region because it's going to increase the latency -- by more than 2x for people using S3! This isn't good, but look at the file system.
Because the file system has *so many requests* for each higher-level operation, we actually see a much more significant slowdown -- 30x the expected latency!
This is why the *network latency* between your server and the file system is *absolutely critical* for getting the performance that vendors expect. It's also why we shipped `archil utils speed-test` in our CLI so that our customers can measure it for themselves. Latency has an exponentially degrading effect on these customers!
This is why Archil needs to be in the same data center as the customer, but object storage services do not.
Getting around this "law of physics" problem is one of the motivating factors behind our recent launch, Serverless execution -- which lets users send bash commands to our service to be executed on the same servers running the Archil disks.
If the program that we were running (read 4 KB chunks randomly from a 1 MB file) can be run on a Linux machine, then we can run it through Serverless execution instead. Let's see how that looks on the cross-region latency graph:
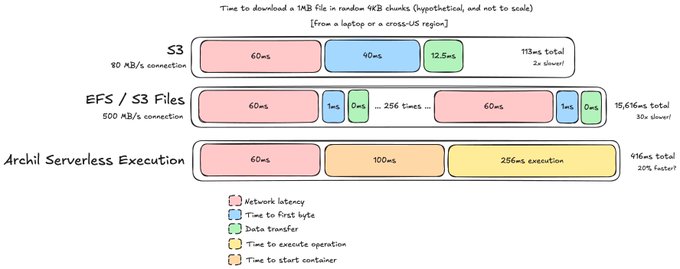
Listen, I promised these things weren't going to be to scale, and sure enough.
Rather than incurring the network latency for *every* operation, we only have it once -- as part of connecting to the server to send the instruction to run our program. Then, we start the container *inside of the Archil service* and run the program *locally* cutting down the network latency (for the program) to near-0.
This, oddly enough, lets the entire thing run (cross-region) faster than if you'd run the original program in the same AWS region as your EFS file system.
This is an unintuitive result that we are super excited about!
We have customers coming in every day who are trying to use Archil from locations where we don't have servers: their laptops, other regions, and other clouds -- because we make it simple. These people are usually (surprised) by the performance they get, primarily as a result of the network latency that they're experiencing.
We hope that Serverless execution is a better way to let anyone, around the world, connect to the same file system without having to think about things like latency.
The answer to the question at the top of the article is, of course, it depends. It's pretty simple to *accidentally* see file system performance that's slower than object storage, and it's our job at Archil to remove those footguns one by one, so that file systems can become a first class developer primitive for the AI age.