使用 harness engineering 改进 Deep Agents
TLDR: Our coding agent went from Top 30 to Top 5 on Terminal Bench 2.0. We only changed the harness. Here’s our approach to harness engineering (teaser: self-verification & tracing help a lot).
TLDR:我们的编码代理在Terminal Bench 2.0上从 Top 30 提升到 Top 5。我们只改变了 harness。这是我们对 harness engineering 的方法(预告:self-verification & tracing 帮助很大)。
The Goal of Harness Engineering
Harness Engineering 的目标
The goal of a harness is to mold the inherently spiky intelligence of a model for tasks we care about. Harness Engineering is about systems, you’re building tooling around the model to optimize goals like task performance, token efficiency, latency, etc. Design decisions include the system prompt, tool choice, and execution flow.
harness 的目标是将模型固有的不均衡智能塑造成我们关心的任务。Harness Engineering 是关于系统的,你在模型周围构建工具,以优化任务性能、token 效率、延迟等目标。设计决策包括系统提示、工具选择和执行流程。
But how should you change the harness to improve your agent?
但是,您应该如何更改 harness 来改进您的 agent?
At LangChain, we use Traces to understand agent failure modes at scale. Models today are largely black-boxes, their inner mechanisms are hard to interpret. But we can see their inputs and outputs in text space which we then use in our improvement loops.
在 LangChain,我们使用 Traces 来大规模理解代理的失败模式。如今的模型主要是黑盒子,它们的内部机制很难解释。但我们可以在文本空间中看到它们的输入和输出,然后在我们的改进循环中使用它们。
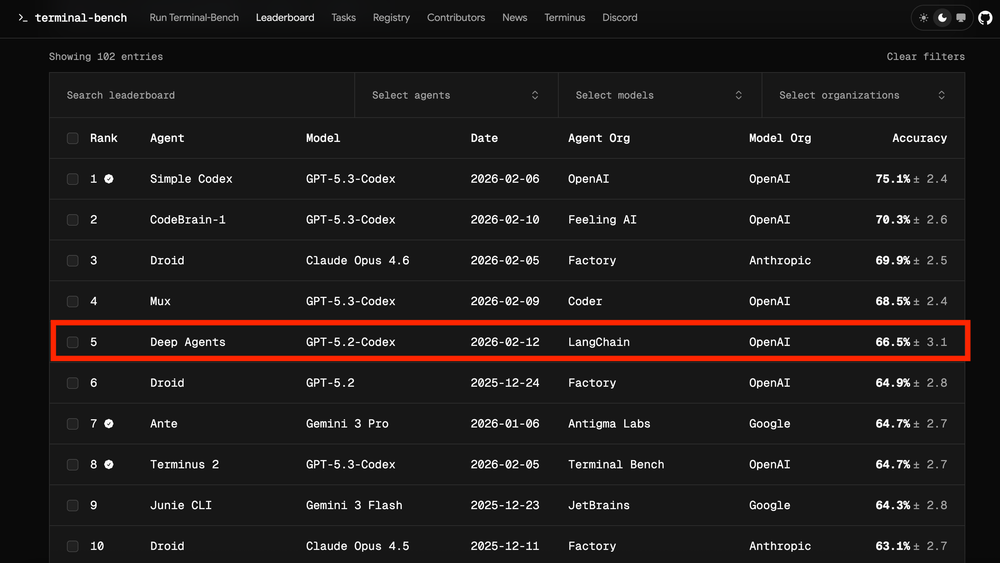
We used a simple recipe to iteratively improve deepagents-cli (our coding agent) 13.7 points from 52.8 to 66.5 on Terminal Bench 2.0. We only tweaked the harness and kept the model fixed, gpt-5.2-codex.
我们使用一个简单的配方来迭代改进 deepagents-cli(我们的编码代理),在 Terminal Bench 2.0 上从 52.8 提高 13.7 points 到 66.5。我们只调整了 harness,并保持模型固定为 gpt-5.2-codex。
Experiment Setup & The Knobs on a Harness
实验设置 & The Knobs on a Harness
We used Terminal Bench 2.0, a now standard benchmark to evaluate agentic coding. It has 89 tasks across domains like machine learning, debugging, and biology. We use Harbor to orchestrate the runs. It spins up sandboxes (Daytona), interacts with our agent loop, and runs verification + scoring.
我们使用了 Terminal Bench 2.0,这是一个现在标准的评估代理式编码的基准。它包含 89 个跨机器学习、调试和生物学等领域的...