Scaling Localization with AI at Lyft

Written by Stefan Zier
For years, Lyft’s localization infrastructure relied exclusively on human translation. While this model usually ensured excellent quality, it was bound by multi-day turnarounds and costs that scaled linearly with every new language. For the few languages Lyft initially supported (Spanish, Portuguese, and French), these limits were acceptable.
However, Lyft’s expansion goals quickly outpaced what traditional workflows could support. Lyft’s recent Québec launch required compliance with Bill 96 (legislation mandating French-first user experiences) which demanded faster turnaround than multi-day cycles allowed. Simultaneously, the Lyft Urban Solutions (“LUS”: Bikes & Scooters) division sought to expand into European markets, requiring six new languages. The business need had changed as we now needed to move faster without sacrificing quality.
This post explores how we re-architected Lyft’s Translation Pipeline to leverage AI alongside linguist oversight and ultimately unlock new market launches. We will walk through context injection, decoupling content generation from evaluation, implementing guardrails, and treating prompts as version-controlled production code. The new pipeline reduces translation latency from days to minutes while maintaining the fidelity required for legal compliance and brand integrity.
Note: We will walk through our batch translation pipeline — used for 99% of app and web content — which targets a 30-minute SLA for 95% of translations. We also support real-time translation (e.g., ride chat) which uses a different architecture.*
How Translations Reach Hundreds of Services
Before diving into the LLM pipeline, it helps to understand how translations flow through Lyft’s infrastructure. This 2020 post explains the internationalization architecture initially built to move beyond one language/currency/country. Since then, the platform has grown to serve 11 locales across 150+ services.
At its core, the pipeline does two things in parallel: it uploads source strings to Smartling, our Translation Management System (TMS), for human oversight, and submits them to LLM workers for rapid draft generation. This dual-path architecture lets us accelerate turnaround while keeping the TMS as the system of record for quality control. The AI-translated strings ship immediately to unblock launches and linguists review them asynchronously. Once approved, the linguist-reviewed version replaces the early release.
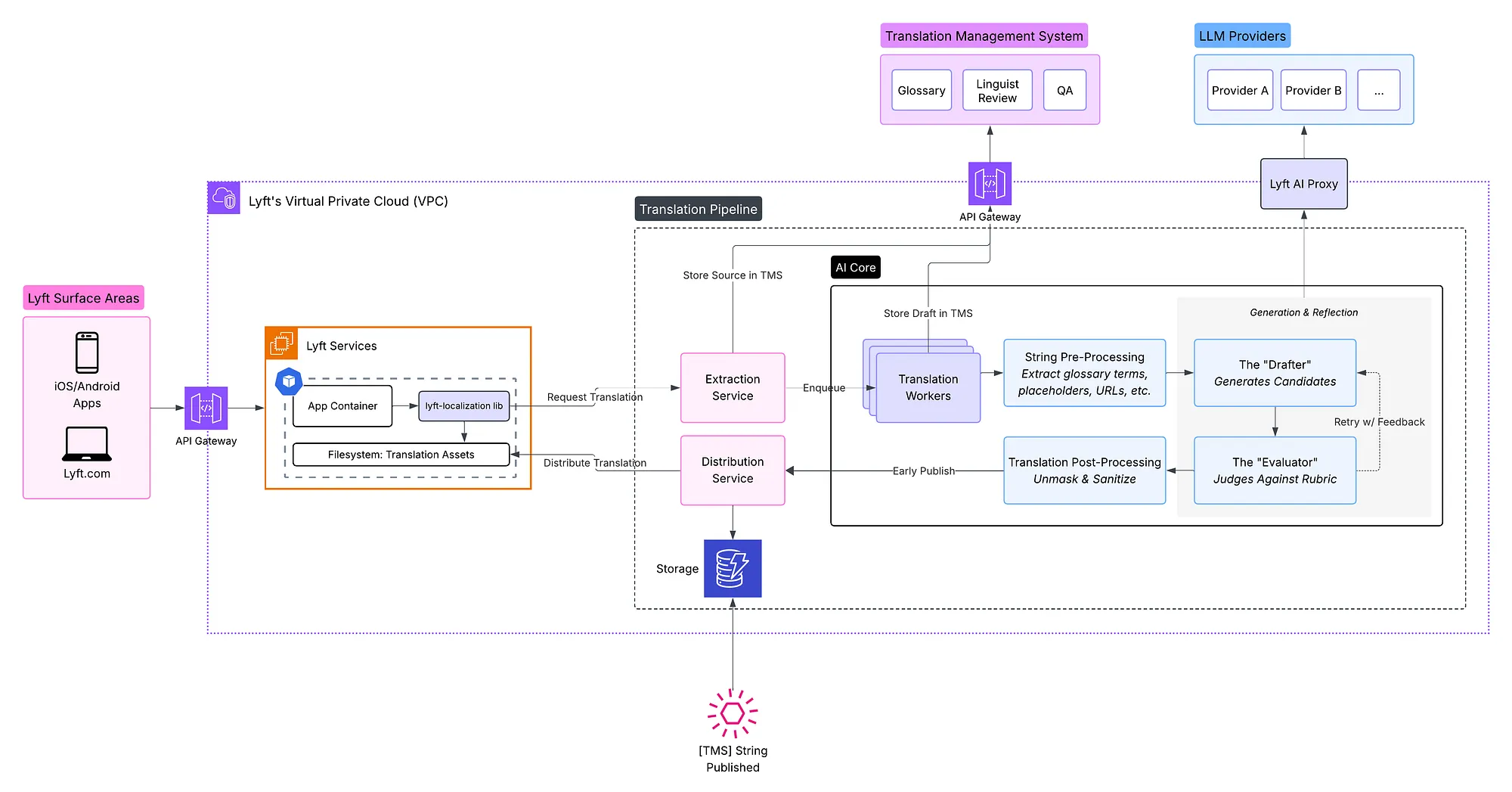
Figure 1: Batch Translation Pipeline Components
Lyft’s localization pipeline operates in three phases:
- Drafting (Ingest): Requesters submit source strings along with context — where the text appears in the UI and the intended tone. The Drafter uses this context to generate translation candidates.
- Unblocking Launches (Early Release): The “Evaluator” runs various quality checks to select the optimal translation candidate. This version is distributed in minutes, unblocking product launches while linguist review takes place in parallel.
- Finalization (Review): Professional linguists review the drafts within the TMS. Approved translations replace the early-release versions and are established as the definitive system of record. Flagged translations are corrected before being distributed.
Why LLMs?
We started with an evaluation of traditional Neural Machine Translation (NMT) providers. We found NMT was fast but translations often did not preserve Lyft-specific terminology or context. This pointed us toward LLMs, and recent research validated that direction.
LLMs have reached human-level translation quality for resource-rich languages. A 2024 study found GPT-4 produced error rates comparable to junior translators for major language pairs, though performance weakens for lower-resource languages. Industry adoption reflects this shift with over 70% of translations now machine-assisted and an overall growing trust in AI-provided translation.
Context handling is the key differentiator. Traditional NMT services process each string in isolation with no awareness of where or how it will be used. In our system, requesters provide context about each string — where it appears, its purpose, any relevant UI constraints. LLMs can incorporate this metadata directly to often produce more accurate translations.
LLMs can evaluate, not just translate. Multiple valid translations can exist for the same source string. Research established that LLMs are state-of-the-art evaluators of translation quality, with WMT25 confirming that large LLMs show strong system-level evaluation performance. This enabled the following architecture where one LLM translates, another evaluates and provides feedback, and the translator again refines based on the critique.
Building the Iterative Pipeline
A naive approach to machine translation is a single API call: send English text, receive translated text. This fails at scale for several reasons:
- No nuance. Single-shot translations are often “correct enough” but rarely optimal for brand voice or regional idioms.
- No quality signal. Without evaluation, there’s no way to know if a translation is acceptable before shipping it to users.
- No recovery path. When a translation fails validation, the system has no mechanism to try again with corrective feedback.
We needed a system that could generate options, critique them, and iterate, a workflow that mirrors how human translators actually work. This led us to an architecture where multiple specialized processes translate and evaluate through structured handoffs.
The “Drafter” — Translation Generation
The job of the Drafter is primarily creative as it aims to produce diverse, high-quality translation candidates. We configure it to generate three distinct candidates for every source string.
Why three? We find a single translation often converges on the most likely phrasing, which may not be optimal for Lyft’s brand voice or the specific UI context. Multiple candidates increase the probability that at least one captures the right tone, handles edge cases correctly, and uses terminology naturally.
Model selection: For the Drafter, we use a fast, non-reasoning model here as translation is primarily a generative task where standard models already perform very well. Additionally, a faster model comes with lower cost and allows us to iterate.
Sample Prompt
DRAFTER_PROMPT = """
You are a professional translator for Lyft.
Translate into {language} for {country}.
Give {num_translations} translations of the following text.
GLOSSARY: {glossary}
PLACEHOLDERS (preserve exactly): {placeholders}
Text: {source_text}
"""
Sample Input/Output
Note: The LLM interactions return structured data via Pydantic schemas rather than free-form text. This ensures type safety, reliable parsing, and clear contracts between Drafter and Evaluator.
# Input
source_text = "Your {vehicle_type} is arriving in {eta_minutes} minutes"
language = "French"
country = "Canada"
# Output (parsed)
DrafterOutput(
candidates=[
TranslationCandidate(text="Votre {vehicle_type} arrive dans {eta_minutes} minutes"),
TranslationCandidate(text="Votre {vehicle_type} sera là dans {eta_minutes} minutes"),
TranslationCandidate(text="Votre {vehicle_type} arrivera d'ici {eta_minutes} minutes"),
]
)
The “Evaluator” — Translation Evaluation
The Evaluator acts as a strict quality gate. It receives all candidates from the Drafter and scores each against a rubric, ultimately selecting the best one or rejecting them all.
Model selection: We use a reasoning-focused model for evaluation. Unlike generation, evaluation requires analytical comparison: checking source versus target for semantic drift, verifying terminology compliance, catching subtle tone mismatches. The deliberate reasoning process helps surface errors that a faster model might miss.
The Evaluator grades each candidate on four dimensions:
- Accuracy & Clarity: Does the translation preserve the full meaning of the source? Is it unambiguous?
- Fluency & Adaptation: Does it read naturally to a native speaker? Is it culturally appropriate for the target region?
- Brand Alignment: Does it use official Lyft terminology? Are proper nouns, airport codes, and brand names preserved in English?
- Technical Correctness: Is it free of spelling and grammar errors? Are all Lyft terms/phrases applied correctly?
Each candidate receives a grade: pass or revise. If any candidate passes, we ask the Evaluator to select the best one. If all fail, the Evaluator provides a detailed critique explaining why each failed.
Sample Output
EvaluatorOutput(
evaluations=[
CandidateEvaluation(candidate_index=0, grade=Grade.PASS,
explanation="Accurate, natural phrasing."),
CandidateEvaluation(candidate_index=1, grade=Grade.PASS,
explanation="Natural and conversational."),
CandidateEvaluation(candidate_index=2, grade=Grade.REVISE,
explanation="'d'ici' implies uncertainty, inappropriate for ETA."),
],
best_candidate_index=0,
)
Why separate Drafter and Evaluator?
Now that we’ve seen both components, it’s worth explaining why we separate them. The critique-and-refine pattern has several benefits:
- Easier Evaluation: Spotting errors is simpler than perfect generation, so the Evaluator doesn’t need to be a flawless translator.
- Context Preservation: The original translator retains the reasoning for its choices when refining based on feedback.
- Bias Avoidance: Separating roles prevents the self-approval bias of a single model translating and evaluating its own work.
- Flexibility/Cost: Different models can be used for each role (e.g., a fast drafting model and a more capable evaluator).
Retry, Reflection, and Self-Correction
The feedback loop between Drafter and Evaluator is a continuous mechanism to ensure if all candidates fail evaluation, the system doesn’t give up. It learns from the failure and tries again, up to three times.
Get Stefan Zier’s stories in your inbox
Join Medium for free to get updates from this writer.
We find this iterative refinement yields the largest gains in the first 1–2 cycles, so the three-attempt limit balances quality improvement against latency and cost.
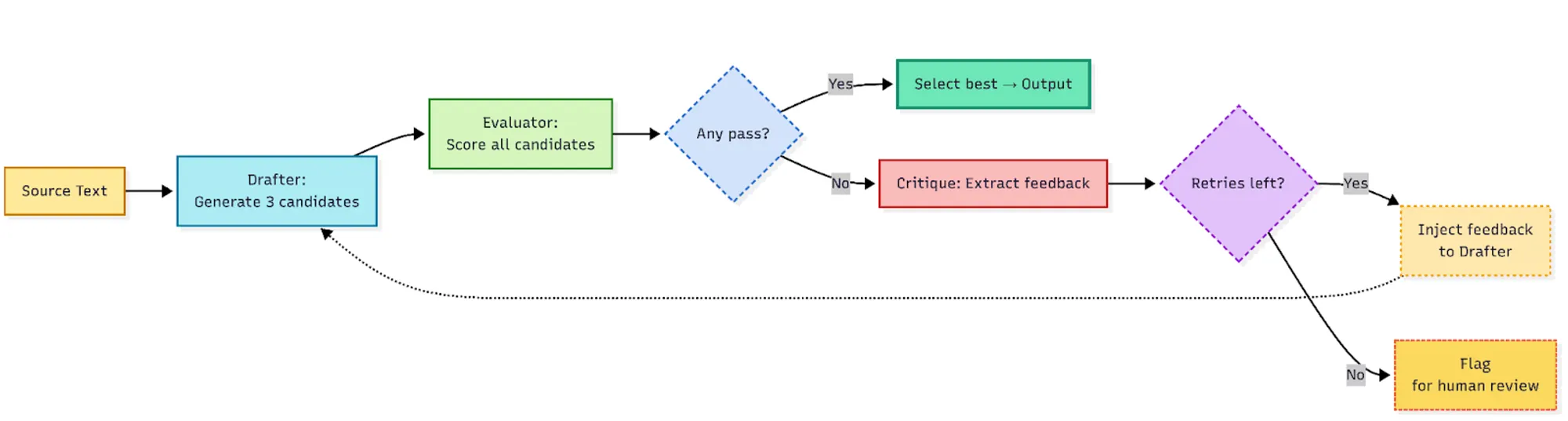
Figure 2: The Translation Feedback Loop
When the Evaluator rejects all candidates, its critique is captured and injected into the Drafter’s next attempt. The prompt explicitly instructs the Drafter to address previous failures:
# This critique is prepended to the next Drafter prompt
critique_for_retry = """
All candidates failed glossary compliance. Key issues:
- "Ride" must be translated as "trajet" per Lyft Quebec glossary
- Do not use "course" which is European French
"""
The retry prompt explicitly instructs the Drafter to address previous failures: correct glossary usage, fix placeholders, adjust tone. We find this iterative refinement process results in a success rate of over 95% across most languages.
In cases of persistent disagreement between the Drafter and Evaluator, we limit retries to three attempts. If no acceptable translation emerges, product teams must wait for a linguist in our TMS to handle the string, or they can internally request an expedited translation for urgent launches.
Context Injection
LLMs don’t have access to Lyft’s terminology guidelines or know, for example, that {driver_name} is a variable in code that must be preserved. We inject this context through careful prompt engineering.
Terminology and reference data aim to reduce the chances of LLM hallucination, a common failure mode. For example, “Driver” might become “Conducteur” in French when Lyft’s official term is “Chauffeur.” To solve this, we maintain data sources of Lyft terms and phrases that the Drafter and Evaluator reference when completing their tasks:
- Glossary terms: Individual words and even phrases with their official translations (e.g., “Driver” → “Chauffeur” in French)
- Do-not-translate lists: Brand names, product names, and proper nouns that should remain in English
All of these assets are maintained in the TMS where linguists routinely review them and update the datasets. The Translation Pipeline then pulls them in periodically for use at translation time to augment prompts to the Drafter and Evaluator:
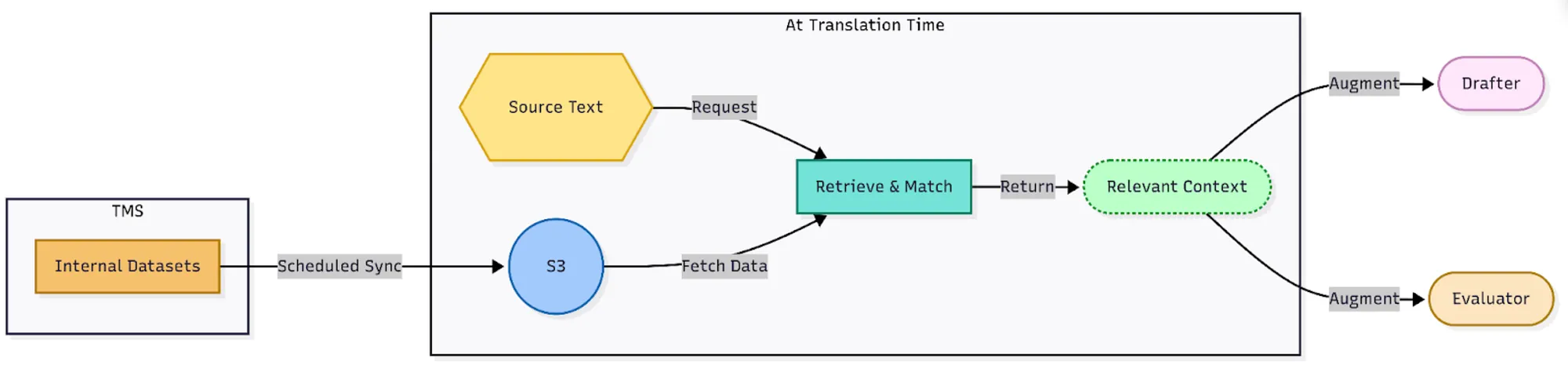
Figure 3: Injecting Terminology and Reference Data
Deterministic Guardrails
LLMs are probabilistic as they may hallucinate variable placeholders, mangle URLs, or strip formatting. For production translation, we need deterministic validation. Without guardrails, we observed consistent hallucination patterns: placeholder translation was the most common failure mode (e.g., {driver_name} becoming {nom_du_conducteur}), followed by placeholder omission and format string corruption.
Our guardrail system operates in two phases: pre-translation extraction and post-translation validation. This layered approach ensures protected elements survive the LLM round-trip intact.
Pre-Translation: Extract and Tokenize
Before any content reaches the LLM, we extract elements that must be preserved exactly. This includes:
- Variables and format strings: Curly-brace variables like
{driver_name}and{eta}, printf-style placeholders (%s,%1$s,%@) - URLs and identifiers: Links, email addresses, and region codes requiring exact preservation
- Structural elements: HTML tags (with balance checking), escape sequences (ex.
\n,\t,\r)
We use regex pattern matching to identify these elements and replace them with numbered tokens (__PH_0__, __PH_1__, etc.) that the LLM is less likely to accidentally mangle. The numbering also handles reordering as different languages have different grammatical structures, so {vehicle_type} might appear before {eta_minutes} in English but after it in German. The numbered tokens maintain the correct mapping regardless of where they end up in the translated string.
Sample Transformation
Original: "Hey {first_name}! Your Lyft arrives at {eta}.\nTrack: https://lyft.com/r/abc"
Masked: "Hey __PH_0__! Your Lyft arrives at __PH_1__.__PH_2__Track: __PH_3__"
Mapping:
__PH_0__ → {first_name}
__PH_1__ → {eta}
__PH_2__ → \n
__PH_3__ → https://lyft.com/r/abc
The mapping is injected into the prompt as human-readable context, giving the LLM explicit instructions about what to preserve.
Post-Translation: Validate and Restore
After the LLM returns a translation, we run deterministic validation before accepting it. Validation checks three conditions:
- Presence: Every expected token appears exactly once
- No hallucination: No unexpected tokens were introduced
- Structure: Structured content, like HTML tags, are balanced (i.e. open tags have corresponding close tags)
When validation fails, we inject the specific errors into a retry prompt rather than giving up. The LLM knows exactly what went wrong (e.g., “Missing placeholder: *__PH_2__* (*\n*)”) and can correct it on the next attempt. This creates a deterministic feedback loop that catches mistakes prompt instructions alone would miss.
Once validation passes, restoration is a simple token-for-original swap:
Translated: "Salut __PH_0__! Votre Lyft arrive à __PH_1__.__PH_2__Suivre: __PH_3__"
Restored: "Salut {first_name}! Votre Lyft arrive à {eta}.\nSuivre: https://lyft.com/r/abc"
Experimentation & Configuration
Initially in development, we treated prompts as configuration, tweaking ad hoc, testing manually, deploying with little review. We found, for example, a small wording change in the Evaluator’s prompt can cause a rise in false rejections. We had no way to identify the regression or roll back.
Now, prompts are version-controlled production code. Every prompt template lives in our Translation Pipeline alongside the code, subject to the same review process. Each prompt version includes a changelog documenting what changed and why. Prompt changes require testing to demonstrate the change improves (or at least doesn’t regress) translation quality on our evaluation suite.
To do this, we evaluate changes against ground truth translations in our TMS, flagging divergences from linguist-approved versions. These differences are reviewed before any prompt or model change receives production traffic.

Figure 4: Prompt Rollouts
Multi-Model Experimentation
We don’t commit to a single model provider. The pipeline abstracts the LLM layer, but experimentation happens through Lyft’s configuration infrastructure. This gives us:
- Traffic splitting: Roll out new models to 5%, 20%, 50% of requests
- Shadow mode: Run new models in parallel without affecting production
- Per-locale overrides: Different models/prompts for different markets
Instant rollback: Revert to previous configuration without a deploy
# Example config schema
drafter:
model: <fast-generation-model>
fallback: <fallback-model>
prompt: <prompt-id>
shadow:
model: <candidate-model>
prompt: <prompt-id>
traffic_percent: 10
evaluator:
model: <reasoning-model>
fallback: <fallback-model>
prompt: <prompt-id>
reasoning_effort: medium
locale_overrides:
<locale_code>:
evaluator:
reasoning_effort: high
We run experiments comparing model combinations across major model providers. This is how we determined that faster, cheaper models (GPT’s mini models, Claude Haiku) perform comparably to frontier models for initial generation while reasoning-focused models significantly outperform on catching subtle errors.
Locale-Specific Tuning
Not all locales need the same prompt. We discovered this when expanding to English variants (en-GB and en-CA). These locales require only orthographic changes like spelling (“color” → “colour”), punctuation, and occasional vocabulary swaps (“trunk” → “boot”).
Without locale-specific guidance, the LLM interprets “translate to British English” as license for entire rewrites. A simple “Try again” button became “Have another go” — technically valid British English, but a jarring tone shift that didn’t match our UI voice.
As shown in the config above, we use locale overrides that constrain the transformation scope. For example:
LOCALE_OVERRIDE_EN_GB = """
You are adapting American English text for British English speakers.
IMPORTANT: This is an ORTHOGRAPHIC adaptation, not a full translation.
Only change:
- Spelling (color → colour, center → centre, organize → organise)
- Punctuation conventions where required
DO NOT change:
- Tone or voice
- Sentence structure
- Casual vs. formal register
- Idioms or expressions (unless they are specifically American and would confuse UK readers)
The goal is that a British reader sees familiar spelling, not that the text "sounds British."
"""
This constraint dramatically reduced over-adaptation errors for English variants while maintaining consistent brand voice across locales. We now apply similar scoping constraints for other closely-related language pairs where full translation would be overkill.
Conclusion
Through careful oversight, we see 95% of translations need no significant changes after linguists review. The remaining 5% usually represent genuinely difficult cases (regional idioms, legal disclaimers, brand voice decisions) where human oversight adds real value.
Re-architecting Lyft’s translation pipeline taught us that LLMs excel at translation when you design for their limitations. The iterative Drafter/Evaluator pattern mirrors how human translators actually work: generate options, critique them, refine. Deterministic guardrails catch what prompts alone cannot enforce. And treating prompts as production code (versioned, tested, reviewed) prevents the silent regressions that plague ad hoc LLM deployments.
Acknowledgements
Thank you to the following team members for making this possible: Janani Sundarrajan, Sebastiano Bea, Jiachen Jiang, Alex Hartwell, Yousra Saidani, Adriana Deneault, Yuantao Ji, Miles Krell, Alex Atencio.
Lyft is hiring! If you’re passionate about leveraging AI to enhance millions of user experiences, visit Lyft Careers to see our openings.
*The Lyft Terms of Service and other product-specific terms and conditions remain strictly human translated.