Eval-driven development: 更快构建更好的AI
A look at Vercel's philosophy and techniques in AI-native development.
看看 Vercel 在 AI 原生开发中的理念和技术。
AI changes how we build software. In combination with developers, it creates a positive feedback loop where we can achieve better results faster.
AI 改变了我们构建软件的方式。与开发人员结合,它创造了一个正反馈循环,使我们能够更快地取得更好的结果。
However, traditional testing methods don't work well with AI's unpredictable nature. As we've been building AI products at Vercel, including v0, we've needed a new approach: eval-driven development.
然而,传统的测试方法并不适用于 AI 的不可预测性。在 Vercel 构建 AI 产品的过程中,包括 v0,我们需要一种新的方法:评估驱动开发。
This article explores the ins and outs of evals and their positive impact on AI-native development.
本文探讨了评估的方方面面及其对AI原生开发的积极影响。
Evals: The new testing paradigm
评估:新的测试范式
Evaluations (evals) are like end-to-end tests for AI and other probabilistic systems. They assess output quality against defined criteria using automated checks, human judgment, and AI-assisted grading. This approach recognizes inherent variability and measures overall performance—not individual code paths.
评估(evals)就像是针对AI和其他概率系统的端到端测试。它们通过自动检查、人工判断和AI辅助评分来评估输出质量,依据定义的标准。这种方法认识到固有的变异性,并衡量整体性能,而不是单个代码路径。

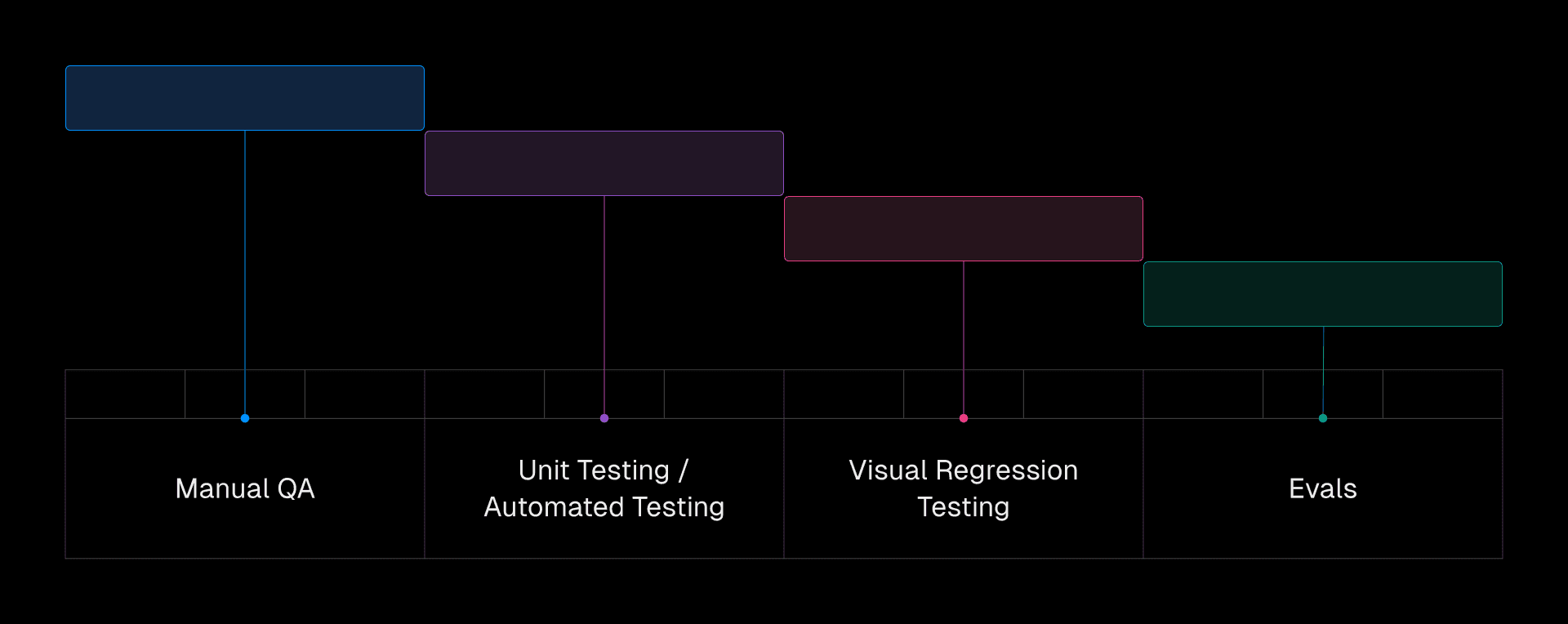
Evals complement your existing test suite.
评估补充了您现有的测试套件。
There are three primary types of evals:
评估主要有三种类型:
-
Code-based grading: Automated checks that use code are ideal for objective criteria and fast feedback. For example, you can check if AI output contains a specific keyword or matches a regular expression. Unfortunately, you can’t code every type of eval
基于代码的评分:使用代码的自动检查非常适合客观标准和快速反馈。例如,您可以检查AI输出是否包含特定关键字或匹配正则表达式。不幸的是,您无法为每种类型的评估编写代码
-
Human grading: Leveraging human judgment for subjective evaluations is essential for nuanced assessments of quality and creativity. This is particularly useful for evaluating the clarity, coherence, and overall effectiveness of generated text
人工评分:利用人类判断进行主观评估对于质量和创造力的细致评估至关重要。这对于评估生成文本的清晰度、连贯性和整体效果特别有用
-
LLM-based grading: Using other AI models to assess the output offers scalability for complex judgments. While potentially less reliable than human grad...