Handling Network Throttling with AWS EC2 at Pinterest
[

·
Jia Zhan, Senior Staff Software Engineer, Pinterest
Sachin Holla, Principal Solution Architect, AWS

Summary
Pinterest is a visual search engine and powers over 550¹ million monthly active users globally. Pinterest’s infrastructure runs on AWS and leverages Amazon EC2 instances for its compute fleet. In recent years, while managing Pinterest’s EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2’s network performance and its direct impact on our applications’ reliability and performance. In this blog post, we’ll discuss our experiences in identifying the challenges associated with EC2 network throttling. We’ll also delve into how we developed network performance monitoring for the Pinterest EC2 fleet and discuss various techniques we implemented to manage network bursts, ensuring dependable network performance for our critical online serving workloads.
Motivation
To illustrate why we are committed to conducting network performance analysis for our online workloads, we’ll share some recent examples from our production environment at Pinterest.
User Sequence Serving
Real time user sequence became very popular at Pinterest since its launch and drove significant user engagement wins. With the continuous addition of user events and features to the platform, there’s an increasing network throughput on the underlying KVStore, which is responsible for storing and serving all machine learning features. Consequently, we started observing an increase in serving latency within the KVStore. This often resulted in application timeouts and, occasionally, cascading failures like retries or connection churns that eventually caused entire KVStore clusters to go down. As a result, we frequently encountered high-severity incidents that significantly decreased Homefeed engagement every time they occurred.
EC2 Instance Migration
In 2024, Pinterest conducted a fleet-wide EC2 instance type evaluation and migration. As part of this journey, we were moving to the AWS Nitro-based instance family, including upgrading our storage fleet from the old i3 family to i4i. However, as we were migrating our widecolumn database, we saw significant performance degradation across many clusters, especially for our bulk-updated workloads. For these use cases, typically datasets are generated offline in batch jobs and get bulk uploaded from S3 to the database running on EC2. We observed a substantial increase in online read latency during these uploads, leading to application timeouts. Consequently, the migration of instances (amounting to over 20,000) was put on hold.
In both cases we suffered from latency increase in our storage services, despite the system running without obvious traffic pattern changes. This prompted us to engage with AWS and dive deep into the network performance of our clusters. In the remainder of this blog post, we’ll share how we root cause and mitigate the above issues.
EC2 Network Bandwidth
Some EC2 instances with “up to” a specified bandwidth, such as c6i.4xl with “up to 12.5 Gbps”, have a baseline bandwidth and the ability to burst above that baseline for limited periods. It’s important to understand both the baseline and burst capabilities when planning workloads. According to AWS documentation, typically, instances with 16 vCPUs or fewer (size 4xlarge and smaller) have “up to” a specified bandwidth. In other words, while the burst bandwidth is 12.5 Gbps, the baseline bandwidth can be half of that at 6.25 Gbps. This can vary depending on the EC2 instance families, so we should always look up the EC2 spec.
It’s important to note that the burst bandwidth is only best-effort: It uses a network I/O credit mechanism, which is designed to provide a baseline level of bandwidth with the ability to burst when additional network bandwidth is available. This allows for flexibility in handling varying network loads while maintaining fair allocation of resources across instances.
What happens when the network allowance exceeds the limit? Packets may be queued or dropped. As a result, from an application perspective, requests may experience unusual delay and even timeouts. Typically we also see TCP retransmits spike during this time.

In the previously mentioned incidents concerning user sequence serving, we discovered that the peak traffic had significantly exceeded the baseline bandwidth on those EC2 instances. This resulted in unpredictable network latency caused by traffic throttling.
In the case during the instance migration, even though the measured network throughput was well below the baseline bandwidth, we still see TCP retransmits to spike during bulk data ingestion into EC2. Since our internal metrics systems measure network usage at a per-minute interval, we suspect there may be throughput bursts that weren’t captured in the one-minute average. To confirm that, we ran various Linux network analysis tools (e.g. iftop, ifstat, nload, sar, iptraf-ng) to measure the network throughput in real time at per second or sub-second level, and surprisingly we didn’t observe any throughput spike.
We had many deep investigations with AWS network engineers and eventually confirmed that those EC2 instances were experiencing network throttling due to microbursts that exceeded the network allowance. Microbursts typically last only for seconds, milliseconds, or even microseconds. Neither standard Cloudwatch or Pinterest’s internal metrics (based on ifstat) can provide such visibility. This experience served as a wake-up call, revealing that the underlying networking systems may rigorously manage bandwidth limits to ensure fair resource allocation.
In conclusion, AWS network throttling happens at EC2 level when the network allowances are exceeded. This may occur when the network usage exceeds the baseline network bandwidth. In addition, due to microbursts, this condition of exceeding network allowance may not be obvious with conventional observability metrics.
Network Performance Monitoring via ENA Metrics
We aim to make EC2 network throttling behavior more transparent to developers at Pinterest. By upgrading our instances to the latest Amazon Machine Image (AMI), we can access the raw counters on an EC2 instance using tools like ethtool.
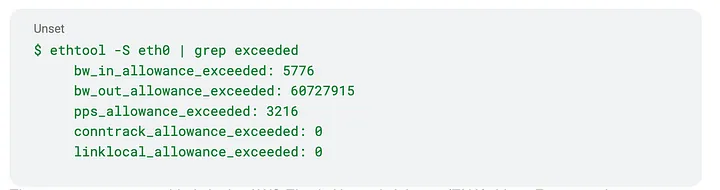
These counters are provided via the AWS Elastic Network Adapter (ENA) driver. For example, bw_in_allowance_exceeded shows the number of packets queued or dropped because the inbound aggregate bandwidth exceeded the maximum for the instance, and bw_out_allowance_exceeded similarly shows that for the outbound side. Refer to AWS documentation for the up-to-date ENA stats.
With these counters available on EC2, we modify Pinterest’s internal metrics collection agent to scrape those counters on each host and ingest them into our metrics storage so that they can be queried in Pinterest’s dashboards. For example, here is a snapshot of the graphs we built based on bw_in_allowance_exceeded and bw_out_allowance_exceeded counters.

This shows in real-time the number of packets that are throttled (queued) due to inbound or outbound network bandwidth exceeded.
By rolling out the above ENA metrics to the entire Pinterest EC2 fleet, we are gaining unprecedented visibility into AWS traffic shaping. This insight enhances our ability to monitor network performance and guides us in implementing various optimizations to mitigate network throttling.
It’s worth noting that, when it comes to monitoring network performance, AWS recommends a multi-layered approach. While the ENA metrics provide invaluable insights, they’re most effective when used in conjunction with other AWS monitoring tools. CloudWatch metrics offer a big-picture view of network utilization trends, while VPC Flow Logs dive deeper into traffic patterns. For containerized applications, CloudWatch Container Insights can provide container-specific network data. And when real-time troubleshooting is needed, AWS Systems Manager Session Manager allows for secure, auditable instance access.
Handling Network Bursts
Now that we have a good visibility into how network throttling can happen due to network bursts, we’ll discuss a few techniques we explored to mitigate this issue.
Fine-Grained S3 Rate Limiting
For the database degradation issue, our analysis below leads us to conclude that network bursts happen during bulk data ingestion. In the database service, the application reads data (e.g. user activities) from the database continuously via online RPCs, while the database itself may periodically do a bulk ingestion of data from Amazon S3 into its local SSDs. Petabytes of data are downloaded into the database service on a daily basis. As a result, both online reads and offline bulk ingestion share the network bandwidth, and bursts in offline ingestion may cause online traffic to be throttled.

We leverage AWS SDK (C++) when downloading data from S3. It exposes an interface for conducting rate limiting when interacting with S3. At Pinterest, we have an in-house rate limiter implementation: it maintains a budget (number of credits) based on the configured rate (bytes per second) and the time elapsed in between requests. Upon each request, it applies the cost and calculates the remaining credits, and it sleeps to replenish the credits when the budget has been exhausted.
In the initial implementation, we had applied rate limits on a per-second level, which turned out to be prone to network microbursts as observed from our ENA metrics. After that, we reimplemented a new fine-grained rate limiter to efficiently track credits on per-millisecond buckets, leveraging folly::ThreadWheelTimekeeper to overcome the stuckness issue we saw when relying on thread sleep. This significantly reduced network throttling.

Data Backup Tuning
Beside serving derived data (ML features) through bulk ingestion, the widecolumn database also supports a mutable mode to serve source-of-truth data via online writes and reads. In this scenario, it suffered from a similar network problem: the database periodically dumped data into S3 for backup purposes, which consumed significant network bandwidth. This ended up impacting online traffic.
Similarly, the fine-grained S3 rate delimiter was applied to the S3 backup client which mitigated the issue to a large extent. However, all the mutable database clusters took daily backup at roughly UTC-0, which magnified the network burst issue. To address this, we applied a few techniques:
- Pace the backup jobs by introducing random jitters into dataset backup jobs in the span of multiple hours. We also limited the concurrency of jobs to minimize the chance of multiple backup jobs overlapping.
- Decouple the offline backup rate limits from what’s used for the online snapshot transfer during replica bootstrap, so that we can flexibly tune the offline backup speed without impacting online data rebalance speed.
- Support Linux socket option SO_MAX_PACING_RATE in the S3 client to ensure the socket doesn’t exceed a data transfer limit (measured in bytes per second).
With above optimizations, we were able to largely smooth out the network bursts and minimize the performance impact when backups are running, cutting the p99 read latency from 100 milliseconds to less than 20 milliseconds. We also suspect that there may be link-level network congestion issues, although we haven’t completed the troubleshooting and analysis with our AWS partners yet.
Network Compression
Separately from the network throttling we see due to S3 download or upload jobs, we also observed significant packet throttling when serving requests with large payload (particularly larger than one megabyte). This caused tail latency (e.g. measured in p999) to increase when serving some of the ML use cases.
We worked with the clients to reduce the payload size which oftentimes involved purging unnecessary ML features. This mitigated the issues and reduced infra cost overall. In the meantime, we leveraged network compression to reduce the payload size over the wire. For example, by leveraging ZSTD compression in our fbthrift client library, we were able to reduce the network throughput by up to 60% in many cases.

However, there are always tradeoffs with compression and in some cases may cause noticeable CPU impact or even latency increase. This is a whole another topic and we may cover it in a future post.
Conclusions and Takeaways
We uncovered the AWS EC2 network throttling issues when serving critical ML workloads in our database systems at Pinterest. This became prevalent when migrating to the Nitro-based instances. Since then, we have rolled out the ENA metrics to the entire EC2 fleet at Pinterest for network performance monitoring and applied various techniques to smooth out network bursts in order to minimize throttling. In the future, we will continue to apply these techniques to more services at Pinterest for reliability and performance improvements.
To wrap up, we want to share a few high-level takeaways for the broader AWS EC2 users:
- Be aware of baseline and burst bandwidth of EC2 when planning your workloads, and set up alerts for network usage.
- Monitor your network performance through ENA metrics with recent AMIs (2.2.10 or later).
- Right-size your EC2 instance based on ENA metrics.
- Minimize traffic bursts to avoid throttling. Common techniques include rate limiting, request/packet pacing, compression, etc.
As we wrap up our journey through the intricacies of EC2 network performance at Pinterest, it’s clear that leveraging AWS support and documentation is crucial. Throughout our process of discovery and optimization, we found AWS Support to be an invaluable partner, offering insights that helped us navigate complex networking challenges.
Our journey highlighted the importance of proactive network performance management. Establishing baselines, implementing automated alerting based on ENA metrics, and regularly reviewing our system resource usage became cornerstone practices. We also learned to balance cost and performance carefully, considering both average and burst network requirements when sizing instances. Perhaps most importantly, we recognized that maintaining network performance is an ongoing process and our journey is far from being complete. Regular performance testing, keeping EC2 instances and AMIs current, and periodically reviewing our network architecture became part of our operational DNA.
Acknowledgement
We would like to thank our trusted AWS partners for their support and collaboration, and for reviewing this blog post. We also thank the following people at Pinterest who had significantly contributed to this project: Rakesh Kalidindi, Mahmoud Meariby, Rajath Prasad, Zhanyong Wan, Yutong Xie, Neil Enriquez, Ambud Sharma, Se Won Jang, Anton Arboleda.
¹Pinterest internal data; Global analysis; Q4 2024