eBay's Notification Streaming Platform: How eBay Handles Real-Time Push Notifications at Scale

Company Information

Streaming systems in event-driven microservice architecture are often compared with distributed data processing frameworks, such as Flink and Spark etc., in terms of technical design choices. At eBay, we have built a high-throughput event streaming platform in microservices architecture where eBay’s partners can subscribe to eBay's business events such as product feeds updates, bid status changes and item shipment information, and receive push notifications in real time. Here’s a high-level illustration of the data flow:
 Figure 1: The high level data flow of the business event streaming
Figure 1: The high level data flow of the business event streaming
- The external event subscriber creates the notification subscription through the eBay Notification Public API.
- The subscription is saved as part of the notification configuration metadata.
- The event producer publishes the event through RESTful API or message queue.
- The raw event is delivered to the event streaming platform.
- The event streaming platform resolves the subscriptions from the metadata store and performs complex event processing.
- The event is delivered to the event subscriber via HTTP push.
Broadcast notification was a significant, though not the only, challenge during this project. The domain team requires our event streaming platform to push broadcast notifications to 20,000 subscribers in real time. For unicast notification, we can fetch the subscription from the database, process the notification and dispatch it to the recipient. However, for broadcast notification, loading all 20,000 subscriptions from the database and processing them is a time-consuming task which also blocks the event processing thread until it finishes, thus increasing the overall latency. This approach is not nearly optimal, so we decided to rethink it.
One option we considered is to offload the long-running task to a distributed stream/batch processing system such as Flink or Spark. There are a couple of considerations in this option:
- The kind of event processing we’re handling is not stateful computation; it mainly involves enriching the raw event with several blocking-service calls.
- The microservice architecture ecosystem in eBay is mature and comprehensive. It covers everything from integration with internal services to development lifecycle management (a mature CI/CD pipeline, managed application framework upgrade, reliable alerting and monitoring platform, etc.).
Adopting such streaming systems is suboptimal and unconvincing for this case, though we do use Flink in our analytics, and also means giving up all the conveniences brought by the ecosystem. Furthermore, the problem we’re facing now is not microservice architecture specific: Even if we adopted another streaming system, the scale of the problem would not change — we still need to think about the decomposition and optimization of a long-running task.
Reconstructable Data Partitioning Strategy
Instead of trying to fetch the subscriptions all at once, let’s consider breaking down this long-running task into subtasks. Each task can only fetch a subset of the subscriptions, with all the subtasks together encompassing the entire subscription dataset. Various strategies exist for the dataset partitioning, such as by the hashing of some data fields, or by pagination. But these options are not efficient for reconstruction. For example, to reconstruct the data at page index 200, we need to sort the entire dataset and iterate until the 200th page is reached. (This is the behavior for our database, though it may vary across database implementations.) We’re seeking a way to partition the dataset that can efficiently reconstruct the partition for the purpose of task distribution and reprocessing (more about this in later sections).
The subscription is created with an UTC timestamp, which is chronologically ordered and indexed (time series data). It is a good candidate for the partition criteria, because it does not change once created. Supposing the subscription dataset S has n subscriptions in total, each is created at timestamp ti, where i is the i-th subscription created for this topic. If we sort all the subscriptions in chronological order and group the subscription at a window size of m, we can get a matrix of subscriptions where each row is a subscription group:

We can also derive an immutable time windowWk composed by the first timestamp and last timestamp from the subscription group:
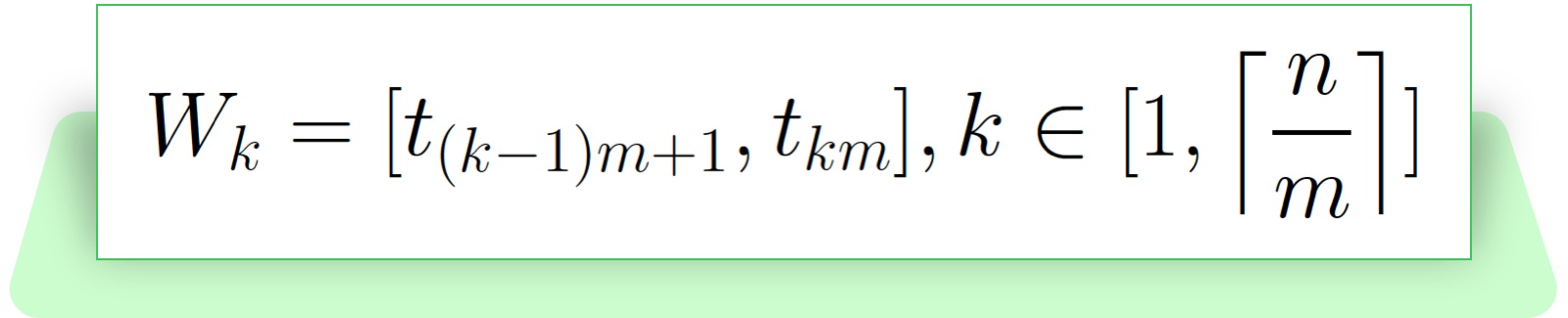
Based on this partition strategy, the process of sending a broadcast notification at scale can be broken down into two phases:
- Splitting the broadcast task into subtasks which each contains a corresponding time window.
- Processing the subtasks concurrently.
This seems to be a step forward: Fetching the time window is a much more lightweight task than fetching all the subscriptions, and the subtasks can now be processed concurrently.
Boost Query Performance via Materialized View
Even though the query for generating the time window is faster than fetching all the data, it still takes linear time proportional to the number of the subscriptions. Generating all the time windows for 20,000 subscriptions is still quite time-consuming. If we have an even larger number of subscriptions, it will take more iterations from application to the database to obtain the complete list of time windows, and eventually this will become the next slow query. Given the property of the createdAt timestamp is immutable and monotonically increasing, then with a constant window size, the historical time windows should always be the same. We only need to care about updating the last time window when new subscriptions are created. We can create a materialized view containing all the time windows which is refreshed on new subscription creation. So instead of generating the time windows on demand, we can directly fetch the already-generated time windows from the view and this takes a constant time.
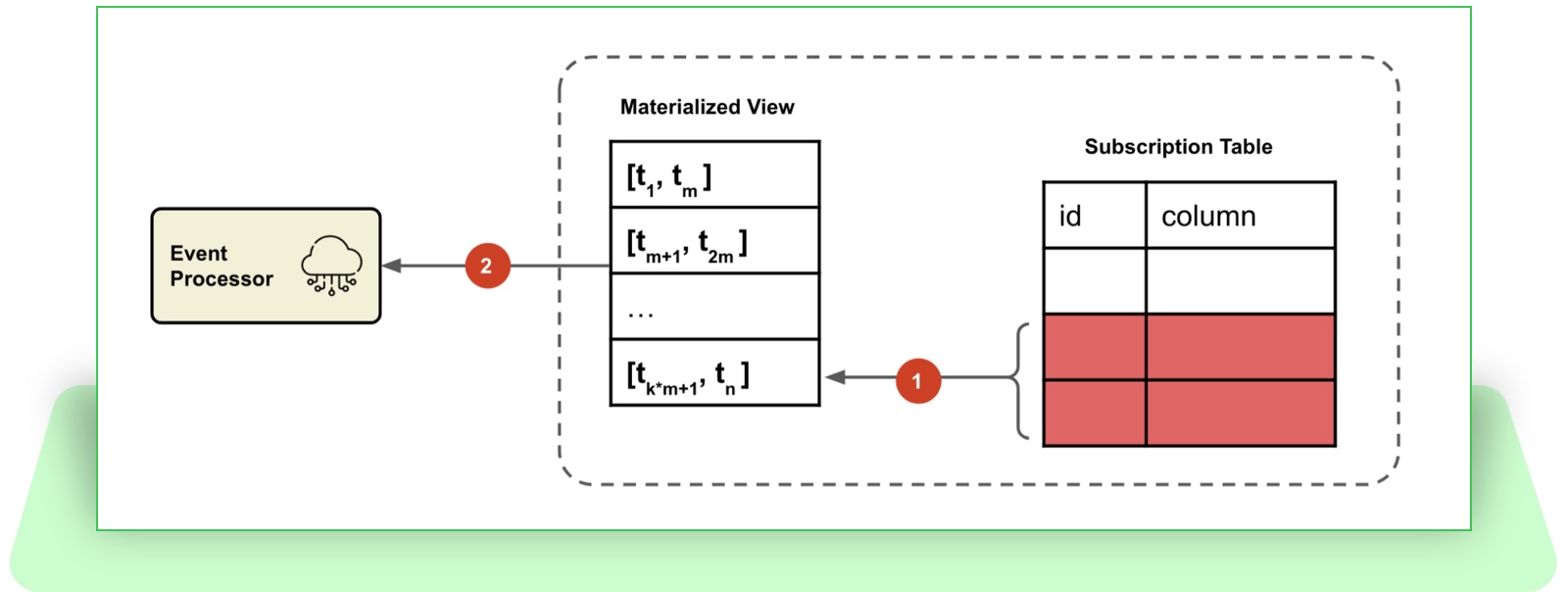
Figure 2: Fetching time windows from a materialized view.
In the above illustration:
- The subscription table insertions will trigger a refresh on the materialized view. (You can actually only refresh the last row if you implement this through a table.)
- The event processor directly fetches the time windows from the view.
The materialized view we’re talking about here does not rely on a specific database implementation; if a given database does not support it, it can be simulated by using a database table or a distributed in-memory data grid. (In such cases, you need to handle the refresh on your own.)
Reactive Event Processing Pipeline
After breaking down the long-running broadcast task into many subtasks, we are able to process these subtasks in parallel. However, a typical event processing pipeline is usually composed of multiple processing stages. This usually involves orchestrating multiple processing units to form a DAG (Directed Acyclic Graph), and controlling concurrency levels in each processing unit. This is admittedly difficult and performance optimization is particularly tricky. We have tried to build the entire pipeline using Java Concurrency API and Reactive Streams API, and we chose Reactive Streams. The goal we’re trying to achieve here is to build an asynchronous, non-blocking event processing pipeline that can maximize the event processing performance. The Reactive Streams implementation offers a rich set of operators and supports operations such as asynchronous parallel transformation, stream fan-in and fan-out, grouping, windowing, buffering and more, which laid the foundation for our parallel processing pipelines. Combined with a reactive message queue client, we can build an end-to-end reactive pipeline with built-in flow control based on backpressure.
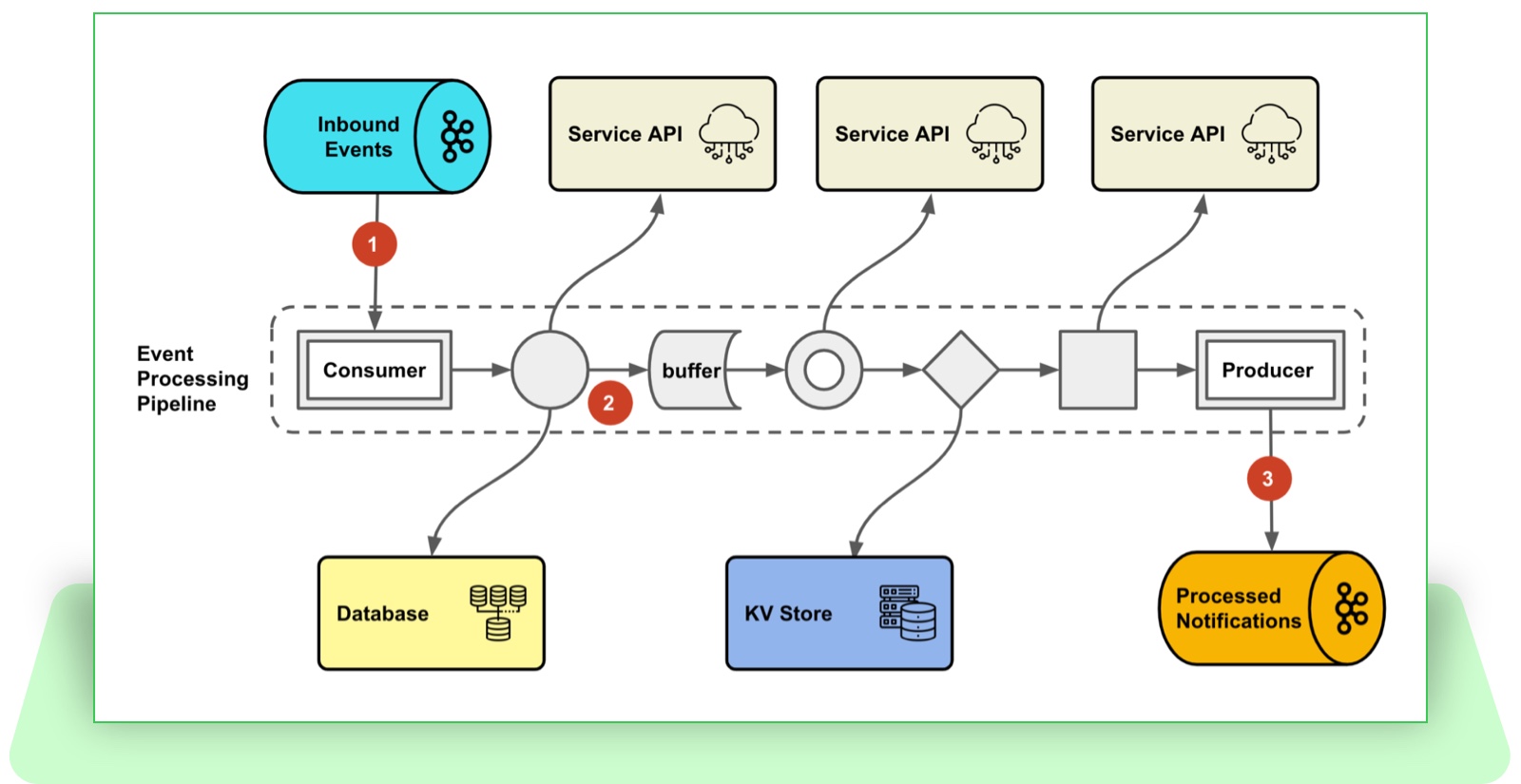
Figure 3: A end-to-end reactive event processing pipeline.
The above illustration depicts an end-to-end reactive pipeline:
- The pipeline ingests the inbound events through a reactive data connector with built-in backpressure.
- Inside the pipeline, parallel transformation, buffering, non-blocking service calls and more are composed together with Reactive Streams operators.
- The processed events flow into the downstream message queue using the same reactive data connector.
Distributed Event Processing
Now we have built a reactive event-processing pipeline which processes the broadcast notification subtasks in parallel. However, even with a window size of 200, 20,000 subscriptions can end up with 200 subtasks. The parallelism of a thread pool is limited by the number of CPU cores, and so an oversizing thread pool can diminish the marginal benefits. The ideal solution is to distribute these subtasks over to the cluster and utilize the cluster’s computing capabilities. The broadcast subtask is a simple fire-and-forget style processing, so we can leverage a message queue for the task distribution.
 Figure 4. Task distribution via message queue
Figure 4. Task distribution via message queue
The distributed event processing steps are as follows:
- An event processor instance receives raw events from the upstream message queue.
- The event processor instance queries the materialized view for all the subscriptions partitions (time windows).
- The event processor instance generates subtasks for each time window and sends them to the message queue transactionally.
- The instances of the cluster receive the tasks with partition information (time window) inside.
- The consumer of the subtask fetches the subscriptions within the time window.
- The consumer of the subtask fans out the notifications for each subscription.
After this optimization, when receiving a broadcast notification from upstream, the event processor only needs to:
- Split the task into subtasks.
- Submit the subtasks to the task queue.
- Acknowledge back to the message broker.
After this optimization, the message consumption timeout issue has gone. This optimization also confirms the value of a reconstructable partitioning strategy.
Caching with Task Affinity
The performance and reliability of our event processing pipeline can be severely negatively impacted by the latency of external service calls and database queries. The subscription data and most of the configuration metadata, once created, don't change often. Ideally, we can cache them as much as possible, to reduce the amount of external calls. The round-robin method of task assignment loses the data affinity; We can use a customized task assignment strategy to always bind a specific subtask (immutable time window) to a partition index. As a result, the event processor instance, which is also assigned to a specific partition, always processes the subscriptions from certain time windows. This creates the opportunity to cache the result of external calls inside the instance local memory, due to the limited data size, below is a illustration of task distribution:

Figure 5. Task distribution with partition affinity
- The event processor instance receives the broadcast task and splits it into a subtask list with indexes.
- Each task is sent to the partition with an index of task_index % partition_count.
- Each event processor instance is assigned to a specific partition, only receiving a certain list of subtasks.
In a parallelized event processing pipeline, operators running in parallel may access the cache at the same time, before the key-value mapping even exists and may direct all traffic from the read-through cache to the backend services – the cache stampede. There are various ways to solve this, such as prefilling the cache or locking at the application layer. We can implement this by ourselves or using Caffeine’s AsyncCache: the first request of a key builds a mapping with a CompletableFuture as the value, which will asynchronously block the read until the CompletableFuture completes.
After all of the above optimizations, we solved the challenge of broadcasting notifications. We also ended up with a scalable, near-optimal (most computations are cached) event streaming platform that still leverages eBay's microservices ecosystem.
Conclusion
In this article, we have walked through various optimizations applied to the event streaming platform to support large-scale, real-time broadcast push notification. The techniques we talked about in this article also apply to long-running task optimization in microservice architecture. Our experience demonstrated that building stream processing systems on top of a microservices architecture can benefit from the rich and mature ecosystem while achieving high performance.
References
- Wampler, Dean. n.d. “Fast Data Architectures for Streaming Applications,” 58.
- Kleppmann, Martin. n.d. “Making Sense of Stream Processing,” 183.
![]()
