Automating Data Protection at Scale, Part 3
Part three of a series on how we provide powerful, automated, and scalable data privacy and security engineering capabilities at Airbnb
Elizabeth Nammour, Pinyao Guo, Jamie Chong, Wendy Jin

Introduction
In Part 1 and Part 2 of our blog series, we gave an overview of the Data Protection Platform (DPP). We focused on how we built a global understanding of Airbnb’s data and its associated security and privacy risks. In this blog post, we will describe how we use this understanding to provide powerful and automated security and privacy engineering capabilities and empower data governance. In order to reduce risk across the entire Airbnb organization, we sought to address the following concerns:
- Accountability: Security and privacy compliance are not solely the responsibilities of security and privacy teams, but should be enabled across the Airbnb platform, development experience, product life cycles, and enterprise vendor solutions. As the volume of data grows and services become more complex, we need to hold the teams who control that data within Airbnb (“service owners”) accountable for the security and privacy of that data
- Minimal overhead: While service owners share the responsibility of reducing risks, we want to ensure we can automate the bulk of the work and minimize their operational load
- Global alignment: Not everyone has exactly the same understanding of data classification and protection strategies. We aim to reach a consensus among security, privacy, legal, and service owners and provide a single source of truth for privacy and security annotations and actions
In the following sections, we’ll first share a deep dive into the Data Protection Service, which integrates all components of our DPP and enables us to define custom data protection jobs based on our findings. Then, we will demonstrate concrete use cases of how the DPP reduces security and privacy risks.
Data Protection Service
We built the Data Protection Service (DPS) to integrate all components of the DPP and automate security and privacy actions for stakeholders.
The DPS provides API endpoints to stakeholders or services outside the DPP, which allows them to query for privacy and security metadata stored in Madoka. For example, we have an API endpoint that allows services to query for a list of data assets that contain any type of personal data. This enables downstream data services or pipelines to build their integrations.
The DPS also enables us to easily define custom “jobs” to automate specific steps, such as:
- Creating JIRA notifications: In order to create JIRA tickets, the DPS uses an internal ticket generator that abstracts away the ticketing mechanisms and easily allows us to filter out any duplicate tickets. We just have to define a unique identifier for the findings so that no two tickets are filed for the same findings. JIRA is one of many ways to notify data owners. Slackbots, email notifications, and other internal vendor tools would also be feasible options.
- Generating pull requests (PRs): In order to create PRs in GitHub Enterprise (GHE), we created a wrapper around GHE’s APIs to easily clone a repo, create a PR, and get the status of a PR. Within each job, we implement the logic of how to modify the repo’s target files and add them to a PR.
Data Protection Annotation Validation
To help us comply effectively and efficiently with data privacy laws, we need to know where personal data lives along with its lifecycle. We also need to protect data as it propagates across different data stores and services. To help achieve this goal, we define three levels of data classification annotations — critical, personal, public — and tag the data with the annotations.
At Airbnb, engineers and data scientists can define database-export pipelines to export online MySQL table snapshots to offline Hive tables for data analysis. We require owners to tag each table column with data classification annotations. Using these tags, we are able to segregate and further protect the most sensitive data categories with appropriate access controls and retention limits.
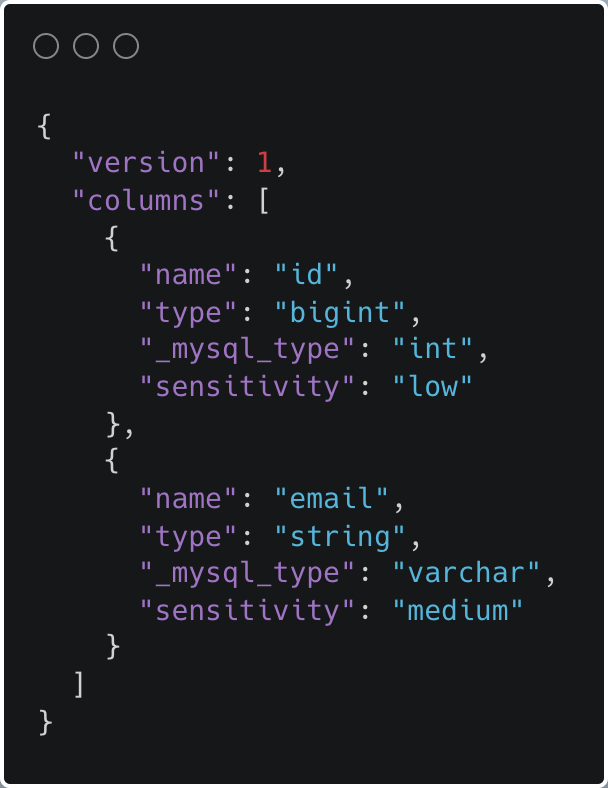
Example of database exports definition
Service owners use an extension of Thrift Interface Description Language (IDL) to define data interfaces for inter-service communication. We require each field within an endpoint to be tagged with a data classification annotation, which is used to restrict service API access from high risk locations. Annotations are also used to help evaluate the security and privacy risks of a service. Below is an example of a Thrift IDL API definition.
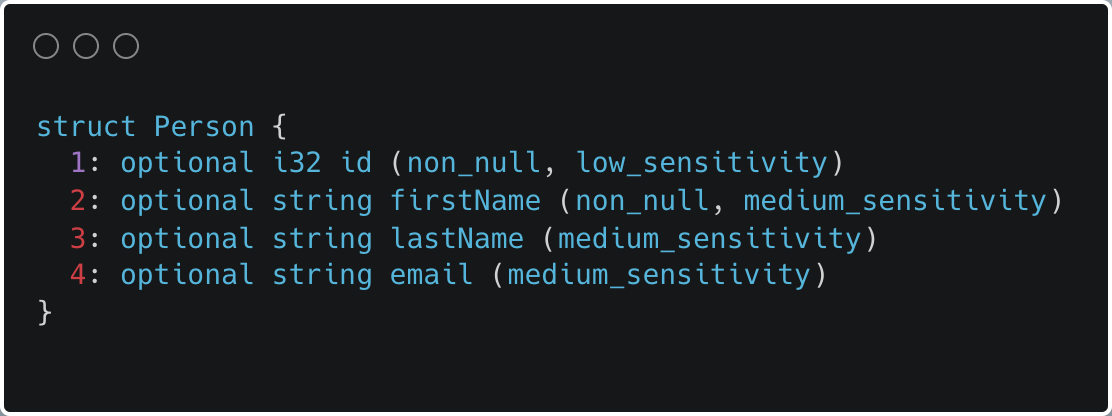
Example Service IDL API definition
However, annotations relying on human judgment are prone to errors. Service owners might misjudge or be unaware of the fields within their API or data column and annotate the data incorrectly. For this reason, we validate the correctness of data classification annotations.
Database Exports Validation
Figure 1: Database Exports Data Classification Validation CI Check
To validate database-exports annotations, we created a CI check that leverages the DPS and runs whenever someone creates a database-exports PR.
For every column specified in the PR, the CI check does the following:
- Queries the DPS to determine what the privacy classification should be for that column. If the classification and the PR annotation don’t match, the CI check will fail.
- Otherwise, we run an additional set of regexes to determine what the data classification annotation of that column should be set to. This is mainly useful for tables that don’t contain any data, or in the case of false negatives.
- If both of these checks pass, then the CI check passes.
The data warehouse also uses data classification results to validate annotations on already-checked-in database-export files. A daily job queries the DPS to fetch data classifications for all Hive tables. The job notifies service owners if the classifications and annotations don’t match. These incorrectly annotated tables will be automatically dropped if service owners do not take any actions.
IDL Validation
Figure 2: Service API Interface Data Language Validation
We leverage the traffic-capturing feature from Airbnb services to get request and response pairs for IDL APIs. Inspekt periodically sends requests to each service to obtain traffic samples. Inspekt then scans and classifies the traffic samples into data elements. Madoka then collects the scanning results from Inspekt and determines if there is any discrepancy between them and the annotation tags. The scanning result classification is determined by the highest sensitivity of all detected data elements. For instance, if the scanning result contains a bank account number (high) and a mailing address (medium), the final classification will be high. The discrepancy will be pinpointed to the specific field(s) within the IDL definition.
When a discrepancy is found, the DPS creates a JIRA ticket and opens a PR for the service owner to fix the IDL annotations. The DPS locates the inconsistent field within the IDL annotation file and uses the GHE client to find the relevant contributor of the code. Then, it opens a PR with suggested changes and links to the PR within the created JIRA ticket.
Privacy Data Subject Rights Orchestration
With the evolution of privacy laws such as with the General Data Protection Regulation and California Consumer Privacy Act, individuals are able to exert more choice and control over how their personal data is collected, stored, and used. Certain data protection laws grant individuals specific data subject rights in relation to their personal data. These include “the right to be forgotten,” which gives a user the right to ask to have their personal data erased, and the right of access, which gives a user the right to know and obtain certain information about the data that an organization holds about them.
Obliviate
To help us comply effectively with these regulations, we built a Data Subjects Rights (DSR) orchestration service, called Obliviate, that helps coordinate and track DSR requests for erasure, access or portability from our users.
Figure 3: Obliviate Workflow
When a consumer submits a DSR Erasure or Access and Portability request to Airbnb, that request gets forwarded to Obliviate. Obliviate propagates that request to downstream services by publishing it to a Kafka queue. Services that store and ‘own’ data at Airbnb are responsible for executing the DSR request by either deleting or fetching all of the personal data stored within their tables.
In order to streamline and simplify how data services interact with Obliviate, we built Obliviate clients to support all data services. The clients provide services with empty Thrift IDL schemas that need to be filled in, one for each DSR request — erasure, access, and portability. The service owner fills in each schema with all columns that the service ‘owns’ that contain personal data.
The clients also provide services with a common interface to implement, which contains several methods responsible for executing each DSR request given a user id. The client is responsible for abstracting away the rest of the logic (e.g initializing Kafka consumers and producers).
For each DSR request, the Obliviate service monitors and waits for a response from each data service integrated with the client and notifies compliance upon completion. If a data service hasn’t responded, the service allows for multiple retries until it completes.
Automating Obliviate Integrations
Even with abstracting away a lot of the logic with the client code, integrating with Obliviate still took a lot of engineering effort. Service owners had to manually sift through their data to determine the exact columns that store personal data, which is very time consuming. They also had to integrate the client code and its dependencies within their service, which can take some time to test and debug. In addition to being time consuming, relying on service owners to determine all personal data in their data stores could be subject to error, since they might overlook a column or not be sure what that column contains.
We decided to use the DPS to automate these integrations as much as possible. The automated integration runs as a daily job with the following steps:
- The DPS sends requests to Madoka and fetches the list of columns that contain personal data but have not been integrated with Obliviate yet, along with the service that owns each column.
- The DPS creates a PR for each service in that mapping that both integrates the service with the Obliviate client code, along with its dependencies, if it hasn’t been integrated already and appends each column associated with that service to the Thrift structs.
- The DPS creates a JIRA ticket that links to the PR and assigns it to the service owner.
All the service owner has to do is implement the three methods in the interface described above by deleting or returning all rows associated with that user from the columns included in the Thrift structures.
Eliminating Accidental Secret Leakage
In our previous blog post, we described how we built Angmar to detect business and infrastructure “secrets” in code and how Inspekt detects personal data and business or infrastructure secrets in data stores and service logs. The DPS enables automated notifications and actions based on these findings and metadata from other upstream services in the Data Protection Platform. Next, we’ll take a look at a few examples of how the DPS eliminates such potential leakages at Airbnb.
“Secrets” in Data Stores and Logs
Once an area of potential leakage is located, DPS automatically creates a security vulnerability ticket specifying the exact leakage point and assigns the ticket to the owner. Each ticket is filed with a tag that allows security operators to track the resolution of the ticket and collect metrics. After a detection of secrets in data stores and service logs, it is mandatory to find the proper service owner accountable for the detected records.
In the ownership section of part 1 of our blog post, we described how Madoka service collects the service ownership property for our data assets. Once records are found, the DPS makes an API call to Madoka with the data asset metadata included within the detected record. For instance, for MySQL, the DPS sends a request to Madoka with the database cluster name and the table name within the call; for service logs, the DPS calls Madoka with the service name within the call. Madoka then responds with the corresponding team or individual “owner” of the assets.
To avoid further data leakage, tickets only contain data asset metadata instead of the detected data content. For instance, for detected records in service logs, we only record the service log code template that introduces the vulnerability and the secret type found during the scan in the ticket, but not the actual content. Once received by the owner, they are expected to discover the secret within their data stores and service logs.
A bottleneck we observed after rolling out the DPS is that generated ticket resolution still needs manual verification. That is, when a ticket is resolved by the owner, the security team needs to verify that either the leaked secrets are removed from the data stores and service logs or the logging template leading to the leakage is removed from source code. To further reduce the operational cost, we plan to create an automated verification solution in future that triggers a regression scan when owners resolve a secret leakage ticket. For instance, for a resolved secret logging ticket, the DPS can trigger a scan over affected source code and see if the previous logging template is removed. The DPS can also trigger a scan over the affected logging cluster and search for the leaked secret to ensure that the secret is safely removed.
Secrets in Code
After a secret is detected within a CI check job, the CI job executes `git blame` to find the most recent contributor of the secret. In cases when the recent contributor has left the company, we trace back to the contributor’s management chain until we find a person that is active. After owner identification, the DPS performs a few operations:
- It de-duplicates secret findings: To avoid duplicate tickets and notifications for the same secret within the same file, we calculate a hash of the secret and the path name of the target file. When the hash value appears to be an existing value, we ignore the finding in DPS.
- It sends a notification: Alerts are sent to a dedicated Slack channel and Datadog for metrics collecting. When security operators are contacted, these notifications can serve as referees to provide contexts for proper guidance.
The DPS automates the secret data protection in the Airbnb codebase and minimizes operational load for security operations. In comparison with a pentesting program where pentesters manually triage secret leakages and operate the resolution process, Angmar incurs far fewer operations.
Conclusion
This post concludes our three-part series on how we are automating data protection at scale at Airbnb. We explained how understanding the data, by storing privacy and security metadata in a central service and by automatically classifying what type of data is stored where, is a necessary building block to protecting the data. In this blog post, we focused on use cases where the data protection platform helped us to reduce security and privacy risk.
If this type of work interests you, see careers.airbnb.com for current openings.
Acknowledgments
The Data Protection Platform was made possible by all team members of the data security team: Shengpu Liu, Zi Liu, Jesse Rosenbloom, Serhi Pichkurov, and Julia Cline. Thanks to our leadership, Marc Blanchou, Joy Zhang, Brendon Lynch, Paul Nikhinson, and Vijaya Kaza, for supporting our work. Thanks to Christopher Barcellos for reviewing our blog post. Thanks to the Trust Privacy team for the great partnership: Jujhaar Singh, Ansuman Acharya, Zoya Sultana, Steve Hill, Liam McInerney, Mamman Fan, Gustavo Alza, Shazad Sahak, Alice Park, Eliott Behar etc. Thanks to the vulnerability management team for building out the ticketing mechanism: Kadia Mashal, Keziah Plattner. Thanks to the data governance team for partnering and supporting our work: Andrew Luo, Shawn Chen, and Liyin Tang. Thank you Tina Nguyen and Cristy Schaan for helping drive and make this blog post possible. Thank you to previous members of the team who contributed greatly to the work: Lifeng Sang, Bin Zeng, Prasad Kethana, Alex Leishman, and Julie Trias.
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.