The Hugo evolution: Engineering Grab's unified, one-click data ingestion platform with Apache Flink
Introduction
Data drives every decision we make at Grab. As our operations scale, so does our need for robust, real-time data ingestion and processing frameworks. Enter Hugo: our self-service data platform that has long empowered teams to seamlessly route data into our Data Lake. Today, Hugo is evolving. We have taken previously siloed onboarding workflows and transformed them into one seamless, unified journey to truly democratize data ingestion and maximize efficiency.
In this blog, we’ll share how Hugo turns complex engineering hurdles into a frictionless, self-service reality. By moving away from siloed workflows, we’ve achieved a unified pipeline experience where one-click RDS CDC and self-service Kafka ingestion are the new standard.
Background
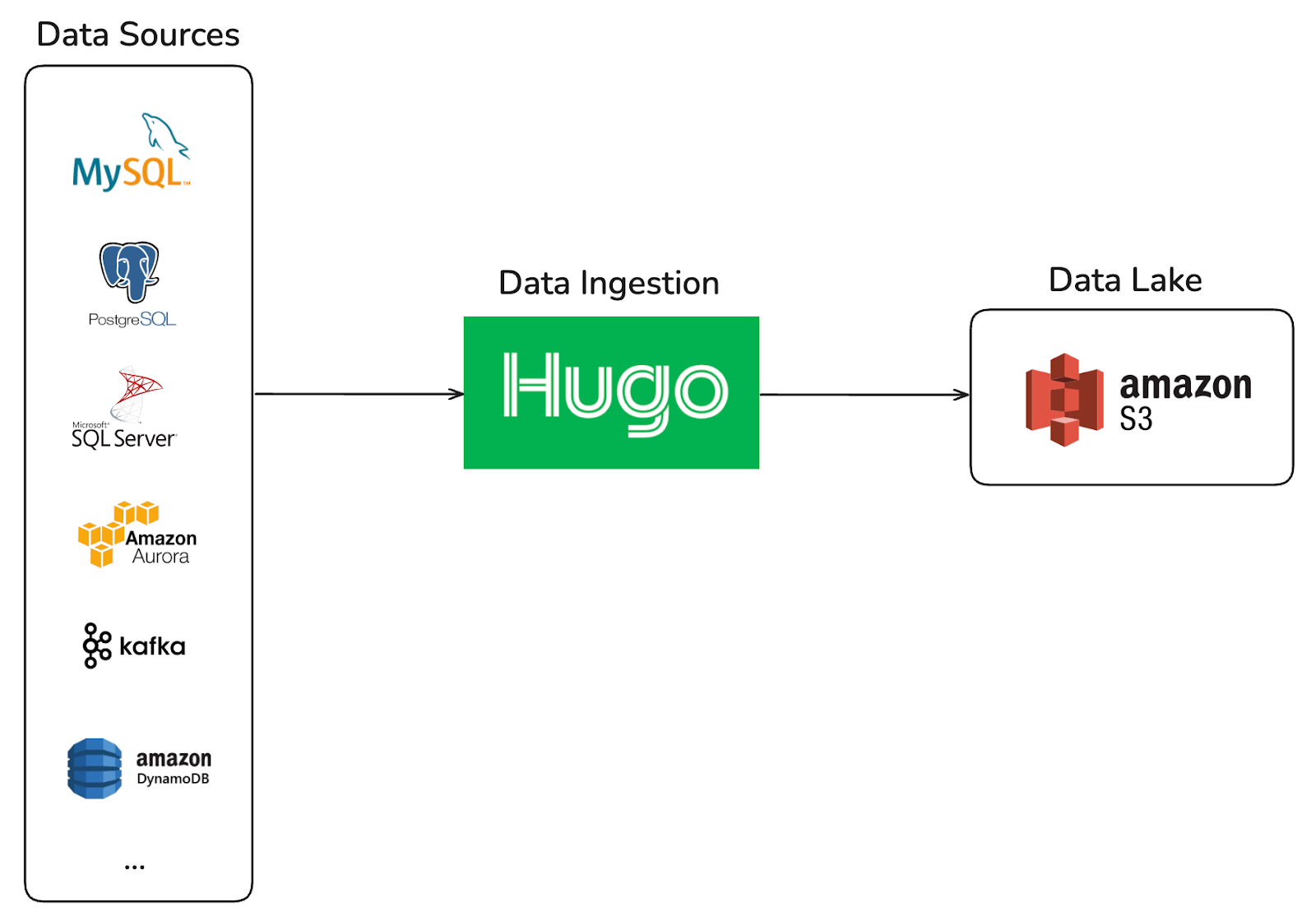
Figure 1. Hugo - Ingests data from every source into Grab's data lake.
Hugo was originally designed as a self-service platform for batch-oriented data ingestion into the Data Lake, built on a single computation engine, Spark. It provided a centralized and streamlined onboarding experience for data sources such as MySQL, Aurora, PostgreSQL, and DynamoDB.
As the organization’s data platform evolved toward near real-time ingestion, Hugo expanded to support streaming pipelines from Kafka and MySQL binlog. This evolution introduced a more distributed architecture, where ingestion workflows spanned multiple systems, including Kafka Connect, Sprinkler (an in-house Go-based S3 writer), and Hugo.
The siloed past: A multi-platform hurdle
While powerful, the expanded architecture introduced significant onboarding friction. Creating a single data pipeline now requires users to coordinate across multiple platforms, each with its own configuration model and operational semantics. As a result, the onboarding journey became fragmented and difficult to navigate, especially for new users.
The common challenge during onboarding was helping users understand how configurations mapped across systems.
For MySQL CDC pipelines, users often asked, “I’ve already configured Kafka Connect, what values do I need to provide in Hugo?” after setting up a Kafka Connect job. This revealed a gap in abstraction between systems, requiring users to manually translate concepts and configurations across different platforms.
For Kafka pipelines, users frequently struggled with schema evolution in the data lake. Common questions included: “How should I update the data lake schema?” and “I’ve already updated the Protobuf schema for this Kafka topic, why isn’t the latest schema reflected in the data lake?” These issues highlighted unclear expectations around schema propagation and synchronization across the pipeline.
This multi-step, cross-system dependency increased cognitive load, slowed down onboarding, and created coordination overhead between platform teams and users.
The Hugo evolution: A unified ingestion platform
Hugo’s new, deeply automated ingestion framework, built with a custom automation layer and Apache Flink, has unified workflows and retired Sprinkler and Kafka Connect. This evolution converted manual, artisanal work into a streamlined, self-service experience, with custom automation serving as the “intelligent chassis” for the entire user journey.
The Hugo ingestion architecture: Engineering a unified flow
One-click MySQL CDC pipelines
The transition to a unified modernized pipeline powered by Flink CDC shifts the data ingestion architecture from a fragmented, high-maintenance toolchain into a single, end-to-end orchestrated platform. By reading the database binlog directly and embedding the lifecycle within a centralized control plane, the modernized approach drastically reduces operational overhead, eliminates data mismatch risks, and cuts onboarding times from days to minutes. Below are the core advantages of adopting Flink:
- Minimal operational overhead: It reduces the footprint from 4 disparate components (Kafka Connect, topics, Sprinkler app, and Spark) to just 2 core components managed via a single control plane.
- Eliminated schema risk: It replaces brittle, manually coded Go DTOs, which caused frequent schema deviations, with automated schema detection and dynamic validation.
- Streamlined architecture: It eliminates the intermediary Kafka hop. Flink reads the MySQL binlog directly and pushes straight to a queryable Hive table via an integrated Spark compaction process.
- Instant onboarding: It shifts deployment from a multi-team, ticket-heavy process taking days to a single-engineer, self-service setup completed in minutes.
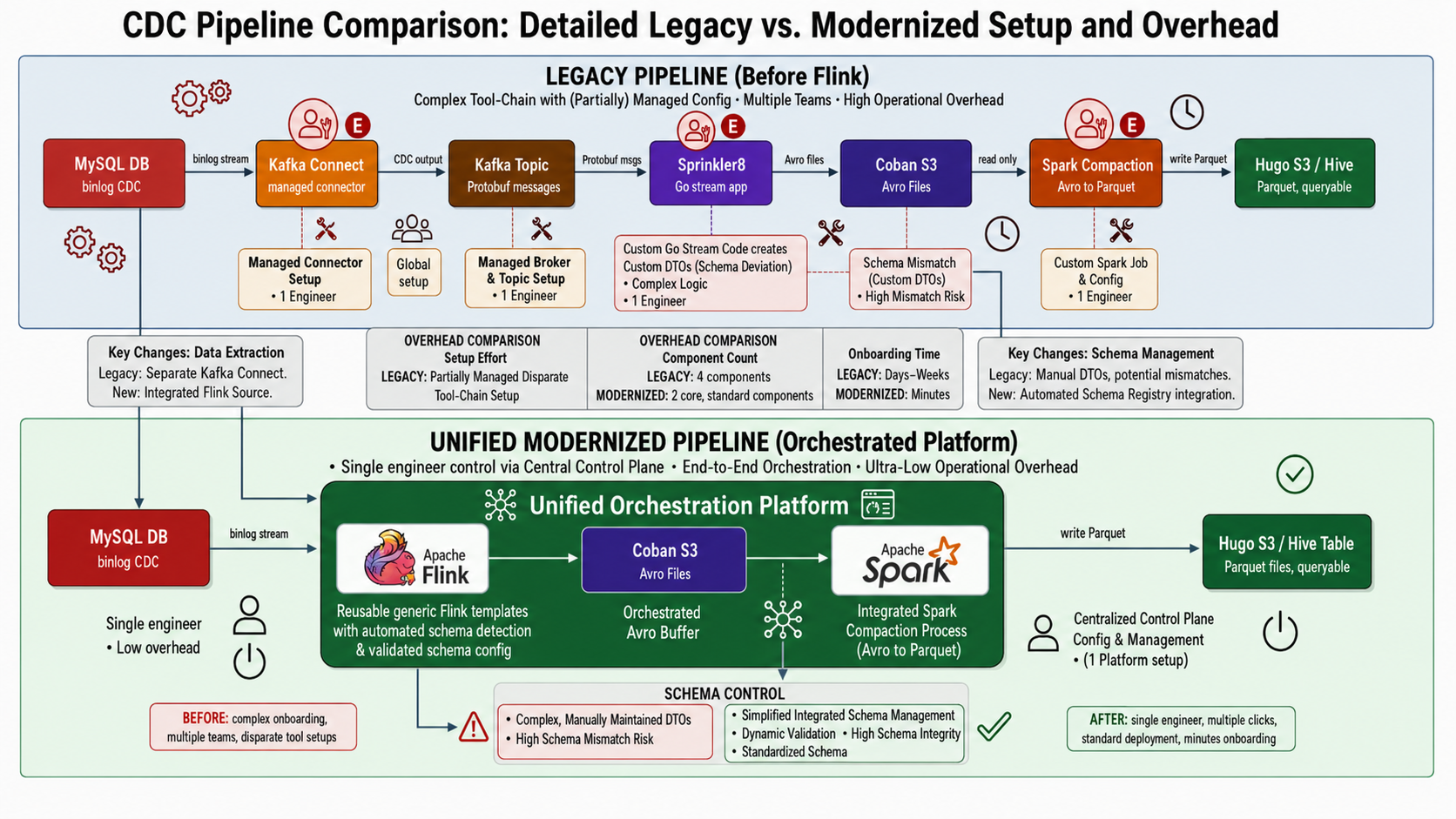
Figure 2. Data ingestion with MySQL CDC to data lake
Self-service Kafka ingestion
The most significant architectural shift in the self-service Kafka ingestion pipeline is the move from manual, fragile schema handling to an automated, resilient system. This comparison highlights the operational pain points eliminated by adopting Flink’s approach.
Legacy Sprinkler approach (manual and static)
- Static registration and hardcoding: It required manual registration of streams within the Go monorepo and relied on hardcoded mappings in
entities.goto convert Protobuf to Avro. - Custom dependencies: Avro schema was generated indirectly from custom DTO structs, not directly from the Protobuf definition.
- Manual schema evolution: Any field change required a multi-step manual process: updating
.pb.goand entity files, followed by a manual pipeline rebuild.
New Flink approach (automated and dynamic)
- Dynamic runtime fetching: Flink pipelines dynamically retrieve the Protobuf schema from Confluent Schema Registry on startup, removing the need for hardcoding and manual stream registration.
- Reduced operational overhead for schema changes: Schema updates are propagated through the CI pipeline to the Schema Registry, removing the need for hardcoded mapping changes. The Flink pipeline can detect updated schemas and resume from the latest checkpoint after restart, though manual restart intervention is still required.
- Click-to-query: Engineers can now ingest streaming data from Kafka topics into queryable Hive tables through a few clicks in the Hugo UI. Hugo automatically orchestrates the multi-stage background work, from Flink consumption and S3 writing to Spark compaction, ensuring data is query-optimized and ready for immediate use.
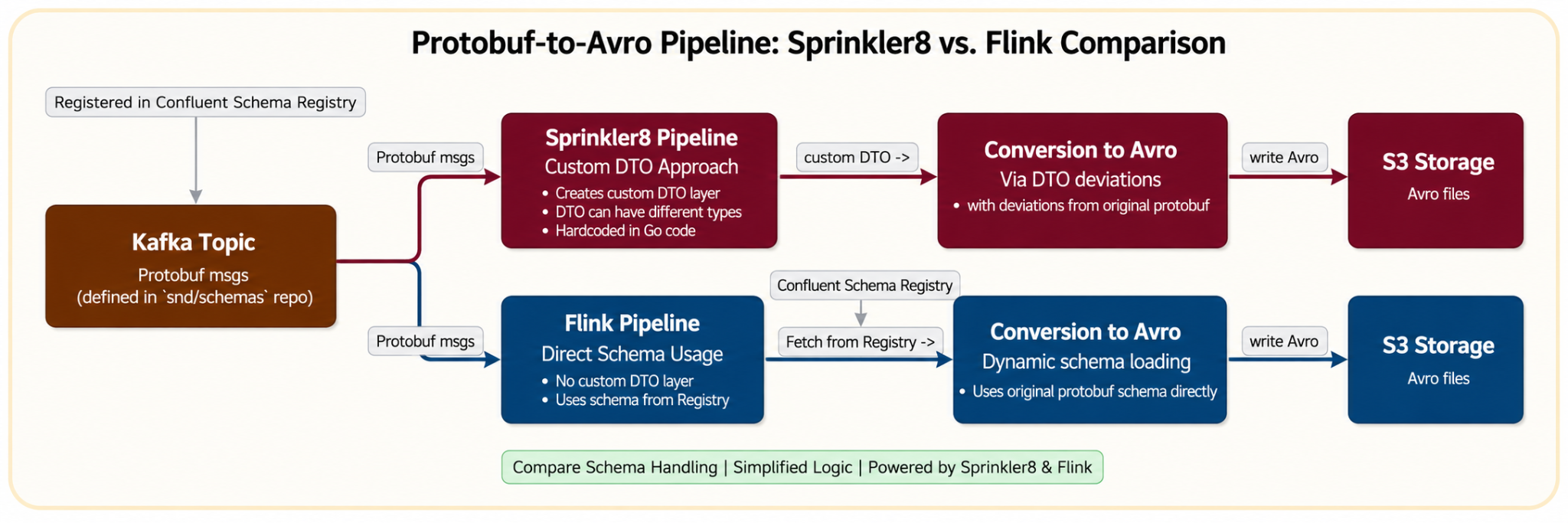
Figure 3. Data ingestion with Kafka to Datalake.
Impact
The platform’s new onboarding workflow has significantly reduced a previously multi-day process to mere minutes, enabling faster iteration and improving overall onboarding efficiency. This dramatic change has fundamentally altered how our teams interact with data.

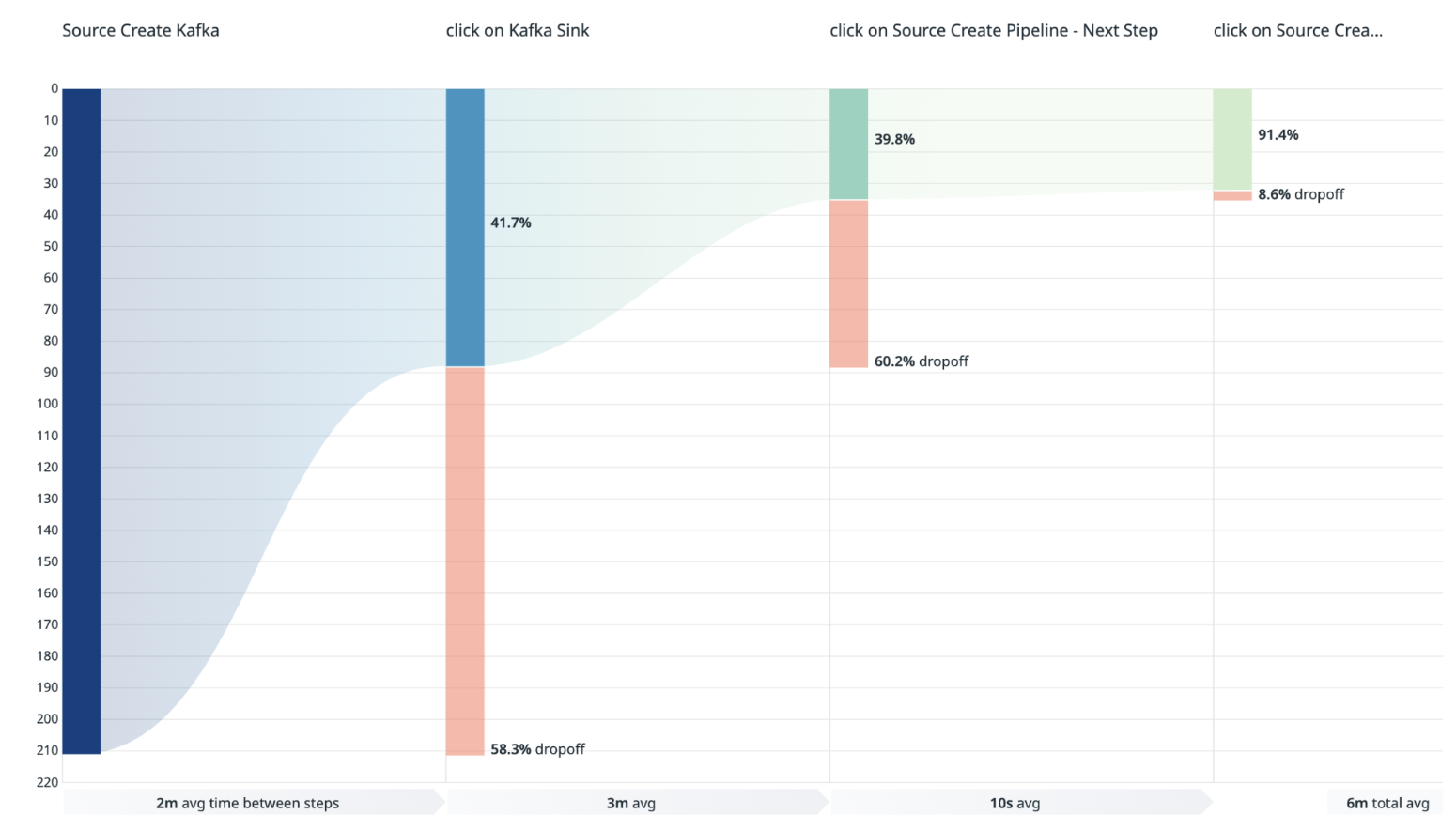
Figure 4. Kafka Flink.
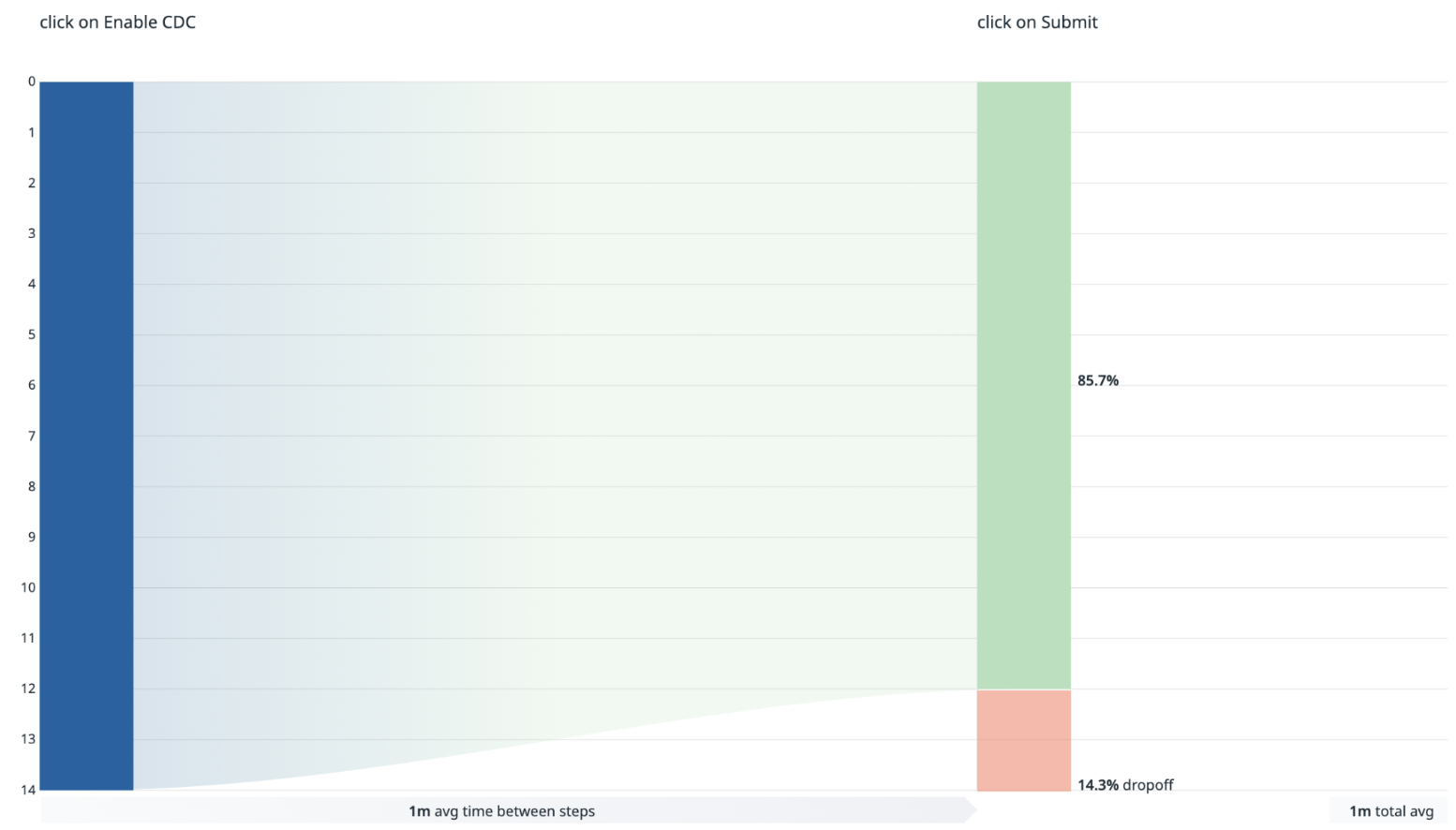
Figure 5. CDC Flink.
The onboarding workflow is intentionally designed with early validation guardrails to proactively surface prerequisite and governance-related issues before pipeline creation proceeds.
- For Kafka sources, user drop-offs between the “Create Kafka Source” and “Kafka Sink” stages are primarily driven by validation checks such as topic ownership verification and topic activity requirements, for example topics with zero message volume. Additional drop-offs between the “Kafka Sink” and “Create Source Pipeline” stages typically occur when the proposed output table name already exists in the data lake, preventing duplicate table creation.
- For MySQL sources, drop-offs are mainly associated with unmet database onboarding prerequisites, including credential setup, binlog user configuration, binlog format requirements, and binlog expiration settings.
In addition, the streamlined self-service experience encourages exploratory usage, allowing teams to familiarize themselves with the onboarding workflow and platform capabilities before fully committing to pipeline creation.
Summary
The new architecture engineered a custom automation layer that successfully retired the reliance on Kafka Connect and Sprinkler for the data lake, turning artisanal work into a streamlined, one-click experience. This transformation provides a direct boost to developer productivity.
The key impact metrics are:
- Onboarding time reduction: The time required to set up data pipelines has been dramatically reduced and is now measured in minutes.
- Kafka pipelines: approximately 6 minutes.
- MySQL CDC pipelines: approximately 3 minutes.
- Kafka pipelines: approximately 6 minutes.
- Adoption: Since the release, the number of new Kafka and CDC pipelines onboarded in the last year is more than the total number of pipelines onboarded in the previous five years.
What’s next
These enhancements are just one step in our broader vision for optimized and self-service data ingestion. Currently, Flink is the default only for Kafka source pipelines. Flink onboarding for MySQL CDC pipelines is impact- and cost-driven. Our strategic roadmap includes:
- Next-generation formats: We are investigating the adoption of Apache Iceberg as the data lake table format to further improve pipeline SLA and costs, and improve performance.
- Seamless schema evolution: Schema changes still require some manual effort from pipeline owners, including manually restarting Flink pipelines. In Hugo, we aim to make schema evolution a zero-touch experience by automatically detecting changes, validating compatibility, and updating tables without disruption.
Join us
Grab is Southeast Asia’s leading superapp, serving over 900 cities across eight countries (Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam). Through a single platform, millions of users access mobility, delivery, and digital financial services, including ride-hailing, food delivery, payments, lending, and digital banking via GXS Bank and GXBank. Founded in 2012, Grab’s mission is to drive Southeast Asia forward by creating economic empowerment for everyone while delivering sustainable financial performance and positive social impact.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!