500X Scalability of Experiment Metric Computing with Unified Dynamic Framework
[

Xinyue Cao | Software Engineer Tech Lead; Bojun Lin | Software Engineer
Overview
Experimentation is a cornerstone of data-driven decision making at Pinterest. Every day, thousands of experiments run on our platform, generating insights that drive product decisions and business strategies. By the end of 2024, over 1,500 metrics — created by experiment users — are computed daily on our Experimentation Platform to meet diverse analytical needs.
But as the scale of experimentation grew, so did the challenges. Delays in upstream data ingestion, difficulties in backfilling skipped metrics, and frequent scalability issues began to hinder our ability to deliver timely and reliable results.
Enter the Unified Dynamic Framework (UDF) — a scalable, resilient solution that has transformed how we compute experiment metrics. With UDF, our pipelines now support 100X metrics and are designed to scale up to 500X in the coming years. This framework has not only ditched all upstream dependencies and accelerated metric delivery but also reduced engineering effort from months to days to build data pipelines, enabling faster experimentation and innovation. Essentially, it achieves standardization of metric processing for Pinterest experimentation. Engineers are able to focus solely on innovation of metric computation because the majority of the infrastructure challenges and pipeline creation complexities are offloaded to the unified dynamic framework.
In this post, we’ll dive into how UDF addresses these challenges and the impact it has had on our experimentation platform.
Experiment Metric Computing at Pinterest
Experiment analysis at Pinterest is powered by Helium, our in-house experimentation platform. Helium supports end-to-end experiment analysis, from setup to metric evaluation. Users can define custom action types (e.g., distinguishing between long and short clickthroughs) and analyze aggregated metrics across user groups, including lift values, p-values, and more.
Metric Computing Workflow
- Data Ingestion: Metrics are ingested into a standard source table from various data jobs created by experiment users.
- Metric Computation: Once all ingestions are complete, the metric computing pipelines calculate the metrics and store the results in Druid tables for visualization on Helium dashboards.

While this design offers flexibility for users to incorporate custom actions, it also introduces several challenges:
- Dependency on Upstream Jobs: Metric computation relies heavily on the readiness of upstream data insertion jobs, which are built and maintained by experiment users. Delays in one upstream job can stall the entire pipeline.
- Backfill Complexity: Skipped metrics due to upstream delays are difficult to backfill, and tracking these skipped actions is cumbersome.
- Scalability Issues: As the number of metrics and data volume grow, the pipelines frequently face scalability challenges, such as out-of-memory (OOM) errors.
These pain points highlighted the need for a more scalable, resilient, and unified solution.
UDF Approach: Dynamic Processing
To resolve bottlenecks caused by inconsistent SLAs across upstream data insertion jobs, we leveraged Apache Airflow Dynamic DAG, which supports creation of DAGs that have a structure generated dynamically. Pipeline structures are generated dynamically based on the readiness of input data. The framework checks for available input data every few hours and processes metrics in parallel batches to balance workloads. Batch sizes are dynamically adjusted based on the traffic and resource utilization of the DAG run, ensuring efficient resource allocation. So instead of waiting for all upstream jobs to complete, the framework processes metrics in small, parallel batches using a first-come, first-served approach: ready inputs are prioritized and processed immediately, while delayed upstreams are handled incrementally. This approach ensures that even if some upstream jobs are delayed, others can proceed without blocking the entire pipeline.
• Avoiding Duplicate Computation
To prevent redundant processing or metrics being double counted, we introduced a mechanism to persist the list of metrics being computed. Each DAG execution checks this list to exclude metrics already in progress, eliminating duplicate computations and ensuring data integrity.
• Automatic Backfill for Skipped Metrics
Metrics are refreshed daily, but upstream delays can cause some metrics to be skipped. To address this, the framework looks back N days to identify and backfill skipped metrics automatically. As long as the upstream delay is within the backfill window, metrics are computed and delivered to dashboards within hours.
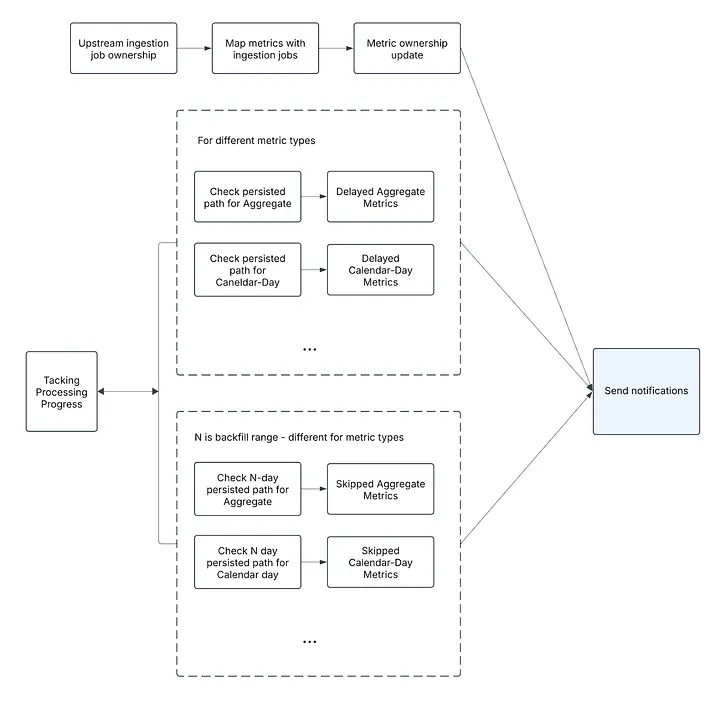
• Notifications
Metric owners receive email notifications if their metrics are delayed or skipped (when the delay is out of the backfill window). A separate pipeline tracks metric ownership, checks for delays, and sends notifications to the respective metric owners.
• Metrics Processing Tracking
To ensure transparency and reliability in metric processing, we’ve built a unified tracking within the framework. It monitors the end-to-end lifecycle of every metric, including delays in source or computation, processing status actively or queues for next executions, skipped due to SLA violations or queued for backfills.
They enable robust governance by providing visibility into pipeline health and drive automation for automatic backfills, as well as prevention of partial data or duplicate computation. By centralizing this logic, the framework ensures metrics are processed accurately, efficiently, and cost-effectively — even at scale.
UDF Approach: Unified Framework for All Experiment Pipelines
The UDF encapsulates all dynamic features above, enabling experiment data pipelines to handle delays in various data sources, automatically backfill skipped metrics within a customizable window, and send notifications for delayed or skipped metrics.
• Simplified Pipeline Creation
Creating a new dynamic metric processing pipeline with UDF is as simple as:

You only need to specify:
- metric_type: Supported types include aggregated, calendar day, daysin, and any new metric types with user-defined computation logic (queries or Spark functions).
- dag_creation_args: Dynamic schedules, parallel batch allocation, and execution configurations.
• Separations of Metric Computation and Pipeline Creation
UDF separates metric computation logic from pipeline creation and is structured into two layers:
- Metric Computing Layer: Handles computation logic for different metric types.
- Dynamic DAG Creation Layer: Generates the DAG layout and provides built-in dynamic features, such as:
- Backfilling metrics from the past N days.
- Balancing workload with dynamically allocated batches.
- Tracking metric processing progress and history.
- Extended plugins for full experiment range backfills and on-demand metrics for specific experiments.
• Experiment Metrics Metadata
All metrics processed by UDF are sourced from the Experiment Metrics Metadata system, a centralized storage designed to streamline user interaction and metrics management. This system enables users to define metrics or segments, configure metric types, and select metrics for experiments, among other tasks.
UDF Architecture Diagram
Based on the principles outlined earlier, this section demonstrates how the UDF integrates its core components shared as above. The diagram below illustrates the architecture in practice, showcasing how dynamic adaptability and unified framework with centralized governance work synergistically to deliver scalable, reliable metric computation.

Results and Conclusions
The launch of the Unified Dynamic Framework has revolutionized experiment metric computing at Pinterest. We successfully onboarded all organic experiment pipelines to UDF in just two weeks, achieving standardization across the platform — a testament to the framework’s simplicity, efficiency, and ease of use.
It improved developer velocity (from months to days to build data pipelines end to end). Developers now spend zero time on pipeline design and implementation and only focus on innovation of metric computation rather than infrastructure challenges.
For each pipeline using UDF, we achieved:
- Flexibility: enable users to bring any customized metrics effortlessly by self-serve without concern of upstream dependencies or metrics left behind.
- Scalability: UDF supports 100X more metrics today and is designed to scale to 500X in the future. It accommodates growing data volumes and metric complexity with minimal maintenance.
- Speed: metrics are delivered 4X faster at least. This is measured against the duration between source data ready and final metric results available with pipeline completion.
- Reliability: 90% of partial data issues are resolved through automatic backfills, and 100% of maintenance effort for upstream failures is eliminated.
The standardization of metric computing across the experimentation platform led to immense improvements on driving innovation and business outcomes. We’re excited to see how this framework will continue to empower experimentation and deliver value to our Pinners!
Acknowledgement
I want to sincerely thank the individuals and teams whose outstanding work made this project possible. Your contributions were invaluable.
- Lu Liu, Lu Yang, Bryant Xiao, and Chunyan Wang who established the prototypes of Pinterest experiment metric pipelines
- Yulei Li and workflow team who integrated Dynamic Airflow into Pinterest workflow platform
- Yi Yang and Druid team who supported Druid partitions during the workflow redesign