A quick introduction to innodb_ruby
[This post refers to innodb_ruby version 0.8.8 as of February 3, 2014.]
In On learning InnoDB: A journey to the core I introduced a new library and command-line tool in the innodb_ruby project. Now I’ll show off a few of the things it can do. I won’t try to explain all of the InnoDB structures exposed, since that will get the demos here way off track. We’ll come back to those structures later on!
Installing innodb_ruby
If you’re familiar with Ruby and gems (or you just happen to have a well-configured Ruby installation), I regularly push innodb_ruby gems to RubyGems, so you should only need to:
gem install innodb_ruby
If that doesn’t work, you might want to check out The RubyGems manual to try and get your installation working. Or abandon all hope. :-D
When you have a working installation, you should have an innodb_space command in your path:
$ innodb_space Error: File must be provided with -f argument
Usage: innodb_space -f
[-p ] [-l ] [ , ...]
Generating some data
For these examples, I need more than a few rows to exist in order to properly examine different data structures. Make sure you’re running a new enough server (MySQL 5.5 is good) with Barrracuda tables and that you have innodb_file_per_table enabled. Create and populate a very simple table with a small bit of Ruby:
#!/usr/bin/env ruby
require "mysql"
m = Mysql.new("127.0.0.1", "root", "", "test")
m.query("DROP TABLE IF EXISTS t")
m.query("CREATE TABLE t (i INT UNSIGNED NOT NULL, PRIMARY KEY(i)) ENGINE=InnoDB")
(1..1000000).to_a.shuffle.each_with_index do |i, index| m.query("INSERT INTO t (i) VALUES (#{i})") puts "Inserted #{index} rows..." if index % 10000 == 0 end
This should generate a table of 1 million rows (inserted in random order to make things more interesting), of about 48MiB, or 3,071 16KiB pages.
(Note that if you’re trying this at home, you’ll want to watch SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_pages_dirty' to wait for all dirty pages to be flushed before proceeding, since the tools below will be accessing the tablespace file on disk, with no coordination with a running InnoDB instance.)
Examining a tablespace file
One of the most high-level overviews possible with innodb_space is space-page-type-regions, which prints one line per contiguous block of a given page type:
$ innodb_space -f test/t.ibd space-page-type-regions start end count type
0 0 1 FSP_HDR
1 1 1 IBUF_BITMAP
2 2 1 INODE
3 37 35 INDEX
38 63 26 FREE (ALLOCATED)
64 2188 2125 INDEX
2189 2239 51 FREE (ALLOCATED)
2240 2240 1 INDEX
2241 2303 63 FREE (ALLOCATED)
2304 2304 1 INDEX
2305 2367 63 FREE (ALLOCATED)
2368 2368 1 INDEX
2369 2431 63 FREE (ALLOCATED)
2432 2432 1 INDEX
2433 2495 63 FREE (ALLOCATED)
2496 2496 1 INDEX
2497 2687 191 FREE (ALLOCATED)
Without getting into too many of the InnoDB internal implementation details, you see some of InnoDB’s bookkeeping structures (FSP_HDR, IBUF_BITMAP, and INODE pages), actual table data (INDEX pages), and free space (FREE (ALLOCATED) pages).
A listing of space consumed, in pages, by each index (actually each “file segment”, or FSEG for each index) can be fairly interesting as well:
$ innodb_space -f test/t.ibd space-indexes id root fseg used allocated fill_factor 15 3 internal 3 3 100.00%
15 3 leaf 2162 2528 85.52%
Every index has an “internal” file segment, used for non-leaf pages, and a “leaf” file segment, used for leaf pages. Pages may be allocated to a file segment but currently unused (type FREE (ALLOCATED)), so “fill_factor” will show the ratio of used to unused. (Keep in mind this has no relation to how full the index pages are, that is another matter.)
Examining a single page
The page-dump mode dumps everything it knows about a single page. It currently leans heavily on the typical Ruby pretty-printer module pp to print the structures — that would be a great thing to clean up in the future. The innodb_ruby library initially parses pages using a minimal Innodb::Page class, and then using the type field present in the common header optionally hands off the different page types to specialized classes (such as Innodb::Page::Index for type INDEX) for further parsing.
A good page to start looking would be the first INDEX page, which is the root node of the index tree for the test table created above, and is located at page 3:
$ innodb_space -f test/t.ibd -p 3 page-dump
The initial line will tell you which class is handling this page:
The FIL header is printed next:
fil header: {:checksum=>621772966, :offset=>3, :prev=>nil, :next=>nil, :lsn=>102947976, :type=>:INDEX, :flush_lsn=>0, :space_id=>1}
The FIL header (and footer) is common to all page types and contains primarily information about the page itself.
Additional information follows depending on the page type; for INDEX pages the following information is dumped:
- the “page header”, information about the index page
- the “fseg header”, information related to space management for the file segments (groups of extents) used by this index
- a summary of sizes (in bytes) of different parts of the page: free space, data space, record size, etc.
- the system records, infimum and supremum
- the contents of the page directory, which is used to make record searches more efficient
- the user records, the actual data stored by the user (the fields of which will not be parsed unless a record “describer” has been loaded)
Looking at index space consumption
It’s possible to see some of the most useful space-consumption related data for all index pages by using the space-index-pages-summary mode:
$ innodb_space -f test/t.ibd space-index-pages-summary | head -n 10 page index level data free records 3 15 2 26 16226 2
4 15 0 9812 6286 446
5 15 0 15158 860 689
6 15 0 10912 5170 496
7 15 0 10670 5412 485
8 15 0 12980 3066 590
9 15 0 11264 4808 512
10 15 0 4488 11690 204
11 15 0 9680 6418 440
This allows you to see the amount of data and free space, and a record count for the table with a minimal fuss.
If a working gnuplot is present and the Ruby gnuplot gem is installed, it’s also very easy to make an useful (although not very pretty) scatter plot of this information:
$ innodb_space -f test/t.ibd space-index-pages-free-plot Wrote t_free.png
The plots produced by space-index-pages-free-plot look like:
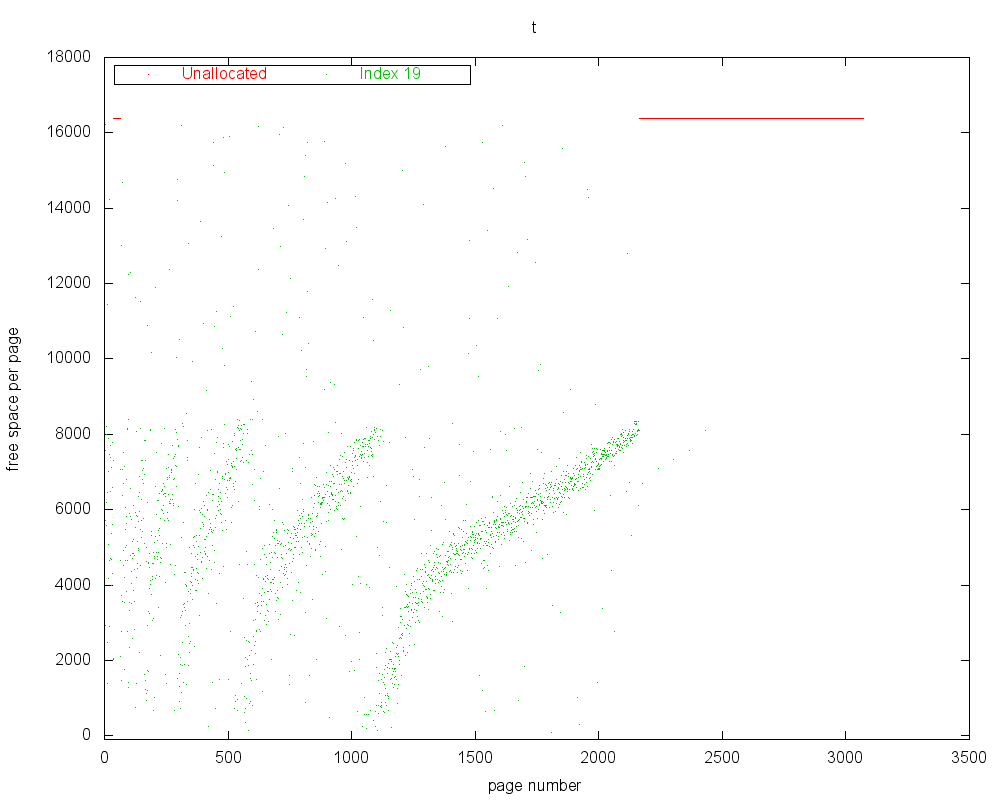
Free Space Plot – The Y axis indicates the amount of free space in each page, while the X axis is the page number, and represents file offset as well. Click for a full-size version.
Making sense of row data
In order to be really useful at examining real tables, innodb_ruby needs to be provided with some way to understand the table schema. This is done in the form of a “describer” class which can be loaded dynamically. This is one aspect of the innodb_ruby library that is not terribly well documented (or well designed, yet). A simple describer class for the above table (i INT UNSIGNED NOT NULL, PRIMARY KEY (i) and no other columns or indexes) would look like:
class SimpleTDescriber < Innodb::RecordDescriber type :clustered key "i", :INT, :UNSIGNED, :NOT_NULL end
If this class is saved in a file simple_t_describer.rb, it can be loaded (require‘ed) in innodb_space with -r
$ innodb_space -f test/t.ibd -r /path/to/simple_t_describer.rb -d SimpleTDescriber
Having a working record describer loaded does primarily two things:
- Enable record parsing and dumping in page-dump mode. This will cause :key and :row keys to be populated in the records dumped, as well as make the transaction ID and roll pointer keys available (they are stored in-between the key and non-key fields, so are not reachable without knowing how to parse at least the key fields).
- Allow use of all index recursion functions, including the index-recurse mode. The ability to parse records is required in order to parse InnoDB’s internal B+tree “node pointer records” which link the B+tree pages together.
Some sample page dumps with full records printed are available: test_t_page_3_page_dump.txt (the index root page) and test_t_page_4_page_dump.txt (an index leaf page).
Recursing an index
Once a record describer is available, indexes can be recursed using index-recurse:
$ innodb_space -f test/t.ibd -r /path/to/simple_t_describer.rb -d SimpleTDescriber -p 3 index-recurse ROOT NODE #3: 2 records, 26 bytes NODE POINTER RECORD >= (i=252) -> #36 INTERNAL NODE #36: 1117 records, 14521 bytes NODE POINTER RECORD >= (i=252) -> #4 LEAF NODE #4: 446 records, 9812 bytes RECORD: (i=1) -> () RECORD: (i=2) -> () RECORD: (i=3) -> () RECORD: (i=4) -> () RECORD: (i=5) -> ()
This will actually walk the B+tree in ascending order (basically a full-table scan) while printing out some information about each node (page) encountered and dumping user records on leaf pages. A larger sample (10k lines) of its output is available here: test_t_page_3_index_recurse.txt.
More to come in the future
I hope this has been a useful first introduction. There is a lot more to come in the future. Patches, comments, and advice are very welcome!
Update 1: Davi pointed out several typos and errors which have been corrected. ;) Make sure you’re using the newest code from examples above.