How Mozilla’s Rust dramatically improved our server-side performance
Like building state-of-the-art web apps? Come work at Figma!
At Figma, performance is one of our most important features. We strive to enable teams to work at the speed of thought, and our multiplayer syncing engine is a critical part of this vision. Everyone should see each change made to a Figma document in real time.
The multiplayer server we launched with two years ago is written in TypeScript and has served us surprisingly well, but Figma is rapidly growing more popular and that server isn’t going to be able to keep up. We decided to fix this by rewriting it in Rust.
Rust is a new programming language from Mozilla, the company that makes Firefox. They’re using it to build a next-generation browser prototype called Servo which demonstrates that browsers can be way faster than they are today. Rust is similar to C++ in performance and low-level ability but has a type system which automatically prevents whole classes of nasty bugs that are common in C++ programs.
We chose Rust for this rewrite because it combines best-in-class speed with low resource usage while still offering the safety of standard server languages. Low resource usage was particularly important to us because some of the performance issues with the old server were caused by the garbage collector.
We think this is an interesting case study of using Rust in production and want to share the issues we encountered and the benefits we achieved in the hope that it will be useful to others considering a similar rewrite.
Scaling our service with Rust
Our multiplayer service is run on a fixed number of machines, each with a fixed number of workers, and each document lives exclusively on one specific worker. That means each worker is responsible for some fraction of currently open Figma documents. It looks something like this:
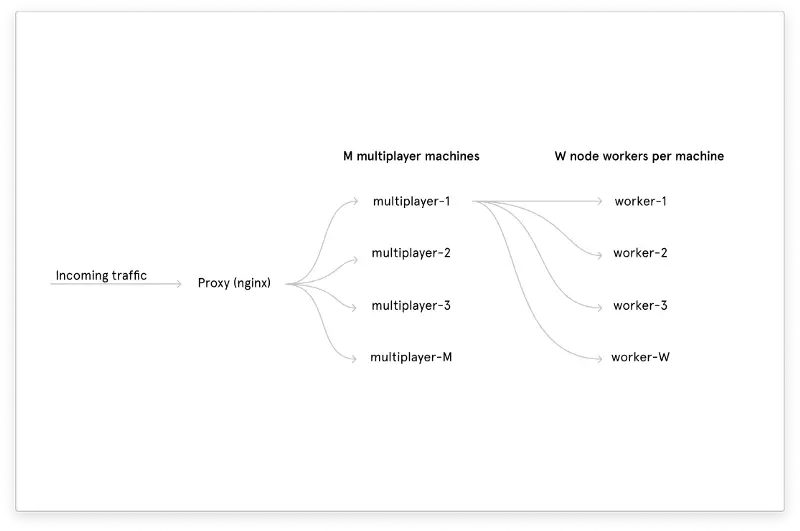
The main problem with the old server was the unpredictable latency spikes during syncing. The server was written in TypeScript and, being single-threaded, couldn’t process operations in parallel. That meant a single slow operation would lock up the entire worker until it was complete. A common operation is to encode the document and Figma documents can get very large, so operations would take an arbitrarily-long amount of time. Users connected to that worker would be unable to sync their changes in the meantime.
Throwing more hardware at the problem wouldn’t have solved this issue because a single slow operation would still lock up the worker for all files associated with that worker. And we couldn’t just create a separate node.js process for every document because the memory overhead of the JavaScript VM would have been too high. Really only a handful of documents were ever big enough to cause problems, but they were affecting the quality of service for everyone. Our temporary solution was to isolate the crazy documents to a completely separate pool of “heavy” workers:
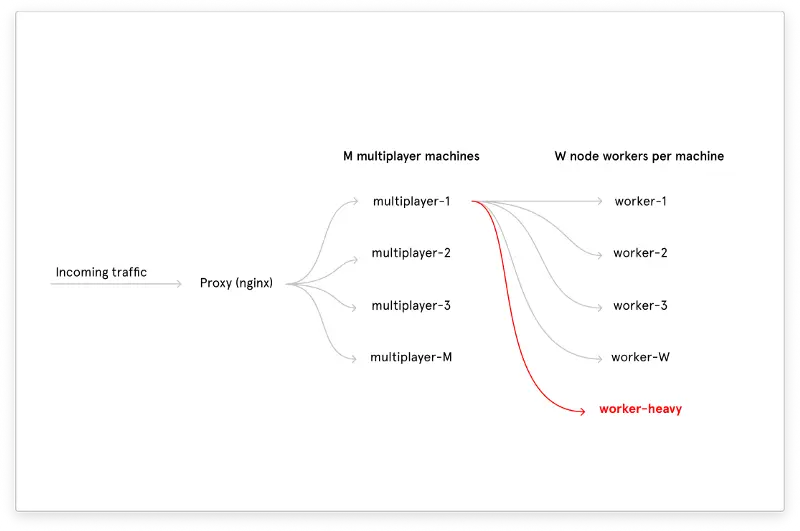
This kept the service up but meant we had to continually look out for crazy documents and move them over to the heavy worker pool by hand. It bought us enough time to solve these problems for real, which we did by moving the performance-sensitive parts of the multiplayer server into a separate child process. That child process is written in Rust and communicates with its host process using stdin and stdout. It uses so little memory compared to the old system that we can afford to fully parallelize all documents by just using a separate child process per document. And serialization time is now over 10x faster so the service is now acceptably fast even in the worst case. The new architecture looks like this:
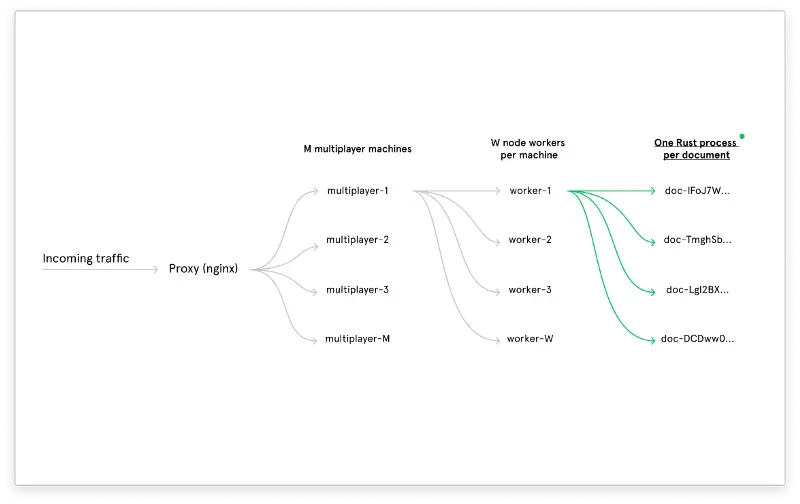
The performance improvements are incredible. The following graphs show various metrics for the week before, during, and after the progressive rollout. The huge drop in the middle is where the progressive rollout hit 100%. Keep in mind that these improvements are in server-side performance, not client-side performance, so they mainly just mean that the service will continue to run smoothly for everyone without any hiccups.





Here are the numeric changes in peak metrics as compared to the old server:

The benefits and drawbacks of Rust
While Rust helped us write a high performance server, it turns out the language wasn’t as ready as we thought. It’s much newer than standard server-side languages and still has a lot of rough edges (described below).
As a result, we dropped our initial plan to rewrite our whole server in Rust and chose to focus solely on the performance-sensitive part instead. Here are the pros and cons we encountered in that rewrite:
Pros
Rust combines fine-grained control over memory layout with the lack of a GC and has a very minimal standard library. It used so little memory that it was actually practical to just start a separate Rust process for every document.
Rust definitely delivered on its promise of optimal performance, both because it can take advantage of all of LLVM’s optimizations and because the language itself is designed with performance in mind. Rust’s slices make passing raw pointers around easy, ergonomic, and safe, and we used that a lot to avoid copying data during parsing. The HashMap API is implemented with linear probing and Robin Hood hashing, so unlike C++’s unordered_map API the contents can be stored inline in a single allocation and are much more cache-efficient.
Rust comes with cargo built-in, which is a build tool, package manager, test runner, and documentation generator. This is a standard addition for most modern languages but is a very welcome improvement coming from the outdated world of C++, the other language we had considered using for the rewrite. Cargo was well-documented and easy to use, and it had helpful defaults.
Rust is more complex than other languages because it has an additional piece, the borrow checker, with its own unique rules that need to be learned. People have put a lot of effort into making the error messages readable and it really shows. They make learning Rust much nicer.
Cons
In Rust, storing a pointer in a variable can prevent you from mutating the thing it points to as long as that variable is in scope. This guarantees safety but is overly restrictive since the variable may not be needed anymore by the time the mutation happens. Even as someone who has been following Rust from the start, who writes compilers for fun, and who knows how to think like the borrow checker, it’s still frustrating to have to pause your work to solve the little unnecessary borrow checker puzzles that can come up regularly as you work. There are good examples of the problems this creates in this blog post.
What we did about it: We simplified our program to a single event loop that reads data from stdin and writes data to stdout (stderr is used for logging). Data either lives forever or only lives for the duration of the event loop. This eliminated pretty much all borrow checker complexities.
How this is being fixed: The Rust community is planning to address this with non-lexical lifetimes. This feature shrinks the lifetime of a variable such that it stops after the last time it’s used. Then a pointer will no longer prevent the mutation of the thing it points to for the rest of the scope, which will eliminate many borrow checker false-positives.
Error-handling in Rust is intended to be done by returning a value called “Result” that can represent either success or failure. Unlike with exceptions, creating an error value in Rust does not capture a stack trace so any stack traces you get are for the code that reported the error instead of the code that caused the error.
What we did about it: We ended up converting all errors to strings immediately and then using a macro that includes the line and column of the failure in the string. This was verbose but got the job done.
How this is being fixed: The Rust community has apparently come up with several workarounds for this issue. One of them is called error-chain and another one is called failure. We didn’t realize these existed and we aren’t sure if there’s a standard approach.
- Many libraries are still early
Figma’s document format is compressed so our server needed to be able to handle compressed data. We tried using two separate Rust compression libraries that were both used by Servo, Mozilla’s next-generation browser prototype, but both had subtle correctness issues that would have resulted in data loss.
What we did about it: We ended up just using a tried-and-true C library instead. Rust is built on LLVM so it’s pretty trivial to call C code from Rust. Everything is just LLVM bitcode in the end!
How this is being fixed: The bugs in the affected libraries were reported and have since been fixed.
- Asynchronous Rust is difficult
Our multiplayer server talks over WebSockets and makes HTTP requests every so often. We tried writing these request handlers in Rust but hit some concerning ergonomic issues around the futures API (Rust’s answer for asynchronous programming). The futures API is very efficient but somewhat complex as a result.
For example, chaining operations together is done by constructing a giant nested type that represents the whole operation chain. This means everything for that chain can be allocated in a single allocation, but it means that error messages generate long unreadable errors reminiscent of template errors in C++ (an example is here). That combined with other issues such as needing to adapt between different error types and having to solve complex lifetime issues made us decide to abandon this approach.
What we did about it: Instead of going all-in on Rust, we decided to keep the network handling in node.js for now. The node.js process creates a separate Rust child process per document and communicates with it using a message-based protocol over stdin and stdout. All network traffic is passed between processes using these messages.
How this is being fixed: The Rust team is hard at work on adding async/await to Rust, which should solve many of these issues by hiding the complexity of futures underneath the language itself. This will allow the “?” error-handling operator that currently only works with synchronous code to also work with asynchronous code, which will cut down on boilerplate.
Rust and the future
While we hit some speed bumps, I want to emphasize that our experience with Rust was very positive overall. It’s an incredibly promising project with a solid core and a healthy community. I’m confident these issues will end up being solved over time.
Our multiplayer server is a small amount of performance-critical code with minimal dependencies, so rewriting it in Rust even with the issues that came up was a good tradeoff for us. It enabled us to improve server-side multiplayer editing performance by an order of magnitude and set Figma’s multiplayer server up to scale long into the future.