Migrating Kafka transparently between Zookeeper clusters
Learn more about how to migrate your Kafka cluster from one Zookeeper cluster to another without any user impact.
By: Edmund Mok

Introduction
Kafka is an open-source distributed event-streaming platform. It depends on Zookeeper, another open-source distributed coordination system, to store cluster metadata. At Airbnb, Kafka forms the backbone of our data infrastructure, powering use cases such as event logging and change data capture that help us better understand our guests and hosts, and make decisions that improve our product.
We run several production Kafka clusters, the largest of which being our oldest cluster consisting of hundreds of brokers and supporting over 1GB/s of incoming traffic. Prior to our migration, this Kafka cluster relied on a legacy Zookeeper setup — a multi-tenant Zookeeper cluster shared between many different production use cases, which means that any incident on the cluster would affect all dependent services, including Kafka. Moreover, this Zookeeper cluster also lacks a clear owner. We wanted to migrate Kafka out of this Zookeeper cluster into a separate, dedicated Zookeeper cluster with clear ownership and better isolation from other use cases.
The goal was for the migration to be done transparently, without any data loss, downtime or impact to Kafka users, as well as other Zookeeper users.
The recently released Kafka 2.8.0 includes changes for KIP-500, the community’s proposal to remove Kafka’s Zookeeper dependency. Since this feature in Kafka 2.8.0 is neither complete nor production tested, it would take another few releases before we would have the confidence to try running Kafka without Zookeeper. Thus, we decided to migrate Kafka between Zookeeper clusters instead.
Our approach was largely inspired by Yelp’s original approach, but modified to use Zookeeper observers in the migration to minimize configuration changes to the source Zookeeper cluster. We were also migrating Kafka clusters running version 2.3.1 and Zookeeper clusters running version 3.5.8. If you are also attempting a migration, be sure to test carefully on your setup, especially if you are running a different Kafka or Zookeeper version!
High Level Strategy
We’ll use zk-source to refer to the original Zookeeper cluster that we are migrating Kafka out of, and zk-dest to refer to the new target Zookeeper cluster that we want to move the Kafka dependency to. Note that zk-dest must be a fresh cluster that does not contain any pre-existing data.
Our plan for the migration consisted of the following phases:
- First, add zk-dest hosts as observers of the zk-source cluster
- Next, switch the Kafka cluster’s Zookeeper connections from zk-source to zk-dest
- Finally, reconfigure zk-dest observers to form their own separate ensemble
Phase 1: Add zk-dest hosts as observers of zk-source

Phase 1: After adding zk-dest hosts as observers of zk-source, all zk-dest hosts will be connected to the leader of zk-source and begin replicating data from zk-source.
In the Zookeeper configuration of each zk-dest host, include all zk-source servers with their respective roles (participants or observers) and all zk-dest servers as observers in the server list. Starting Zookeeper in zk-dest hosts with such a configuration will configure them to join the zk-source cluster as observers and start replicating all Zookeeper data in the cluster.
One advantage of using observers here is that in Zookeeper, observers do not participate in the voting process for pending commits and only learn from the leader about committed proposals. Thus, observers can be added to the source cluster to replicate existing data without affecting the quorum.
Another benefit of using observers is that we do not have to modify anything within zk-source, such as the configuration files in zk-source hosts. Observers can join the zk-source cluster without being present in the server list of the zk-source cluster configuration. The leader does not reject such observers despite being aware that they are not listed in the original configuration. This was particularly important for us since we wanted to avoid making changes to (or worse, having to restart) the source cluster if possible.
Phase 2: Switch Kafka connections from zk-source to zk-dest
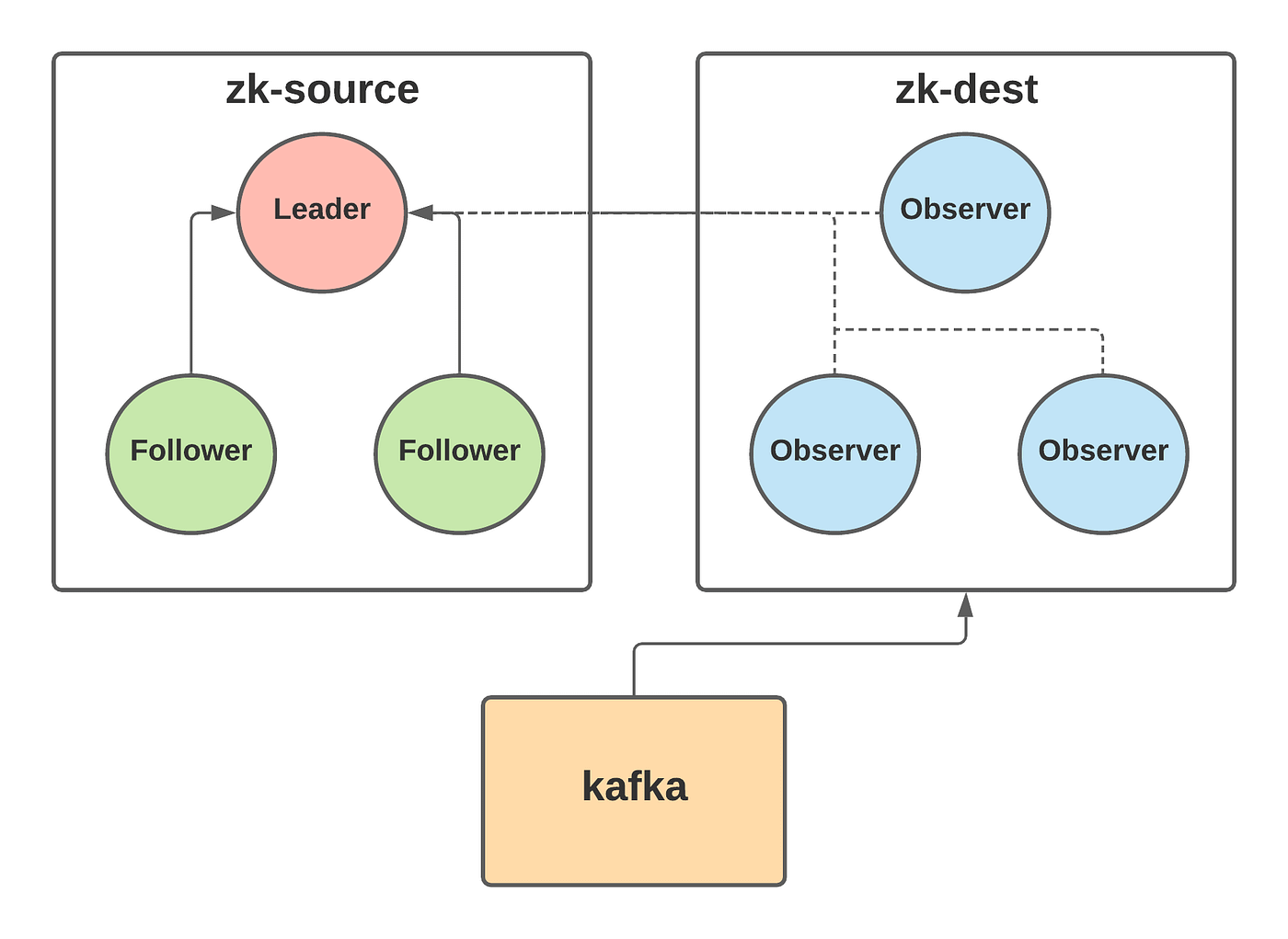
Phase 2: After switching Kafka’s Zookeeper connection over from zk-source to zk-dest, Kafka will still be operating on the original data in zk-source, but through zk-dest observers.
This phase involves updating the Kafka configuration on each broker to use Zookeeper connection strings that point only to zk-dest observers, followed by running a rolling restart of every Kafka broker to pick up this new configuration. Remember to confirm that the observers are correctly replicating data from the zk-source cluster before switching over. At the end of this phase, the Kafka cluster will continue to work with data in the original zk-source cluster, but now doing so through zk-dest observers.
Phase 3: Reconfigure zk-dest observers to form a separate ensemble
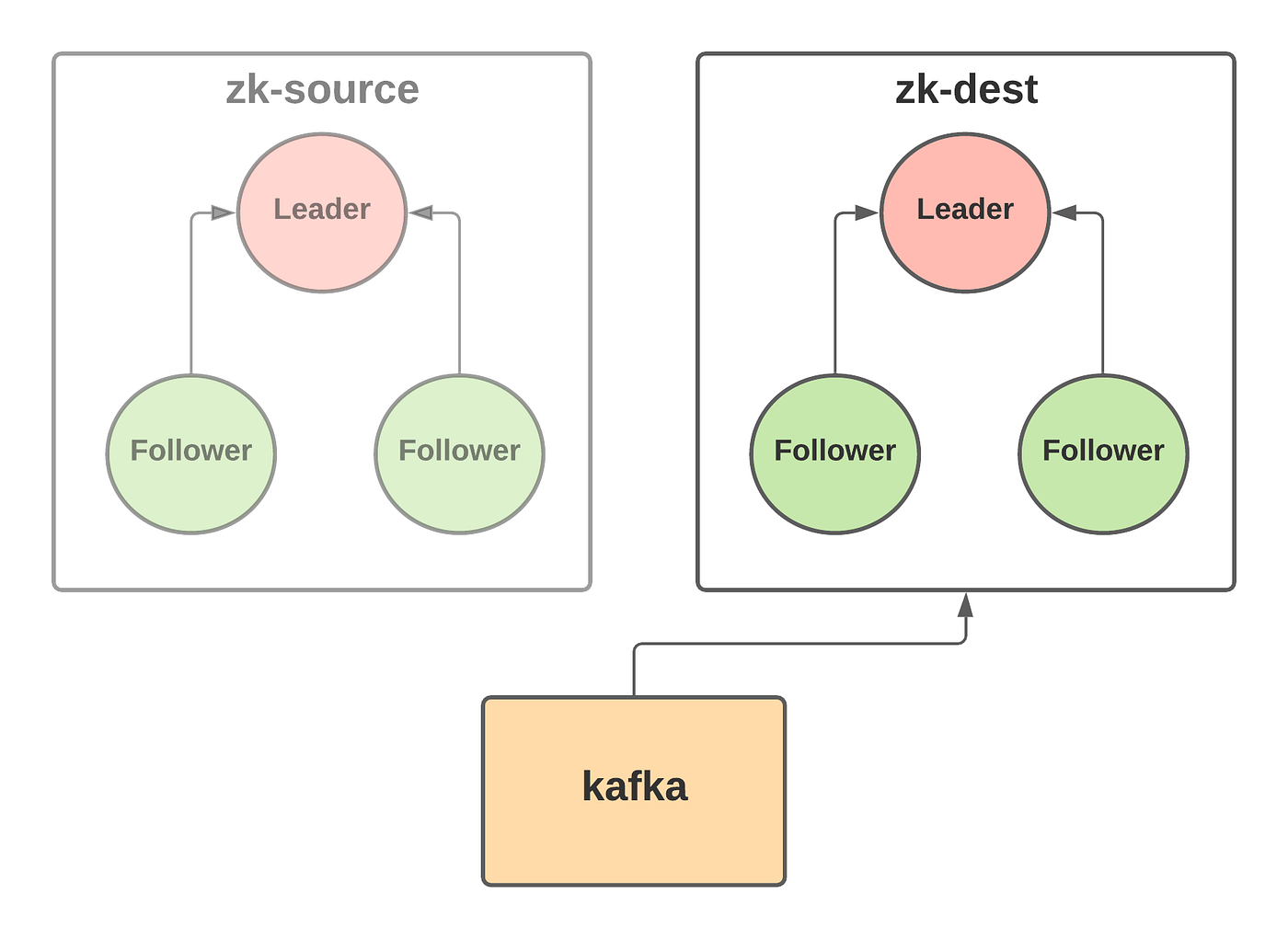
Phase 3: After restarting zk-dest observers into a separate ensemble, zk-dest hosts will form an isolated cluster with a copy of the original data from zk-source but independent from the original cluster.
Here, we perform the following actions:
- Block network communications between zk-source and zk-dest by inserting iptables rules in zk-dest hosts to reject any incoming and outgoing Zookeeper TCP packets to zk-source
- Check that zk-dest hosts have the latest data within the Kafka subtree
- Update zk-dest configurations to include only zk-dest hosts in the server list as participants
Zookeeper will be unavailable to Kafka after the first action, but availability will resume after the final action, and Kafka will eventually reconnect through retries. At the end, zk-dest hosts will pick up the new configuration and form a quorum consisting of only zk-dest hosts. Kafka will be working on a copy of zk-source’s data, but within the zk-dest cluster.
We first block network communications to prevent any further writes from Kafka to Zookeeper to minimize the chance of missing an update being replicated from zk-source to zk-dest as we do the migration, which can result in inconsistent data. This step is just an extra precaution since we have observed Kafka to have low transaction rates to Zookeeper, mostly used for topic creation and updates.
Alternatively, we can either shut down all zk-dest hosts, or block traffic directly from Kafka brokers to Zookeeper. One advantage of blocking traffic between zk-source and zk-dest is that we have found it faster to update iptables rules than to restart Zookeeper processes gracefully. If we want to restore zk-dest back as observers of the original cluster, we can do so more quickly to restore Zookeeper availability to Kafka. It can also help with preserving Zookeeper sessions in the zk-dest cluster, since the zk-source leader may propagate session expirations to zk-dest observers if traffic between them is not blocked. In a later section, we will explain more about why we would like to preserve these sessions during the migration.
Even though Zookeeper is considered unavailable to Kafka after the first action, producers and consumers can still interact with the Kafka cluster and do not experience any disruptions, as long as all brokers are healthy.
In the second action, we can confirm the data within the Kafka subtree is up-to-date by checking whether the zxid (the Zookeeper transaction id used to guarantee total ordering of proposals) for the latest transaction in zk-dest is greater than or equal to the largest czxid, mzxid or pzxid of all ZNodes in the Kafka subtree. These zxids correspond to the zxids of: the change that created a particular ZNode, the change that last modified a particular ZNode, and the change that last modified children of a particular ZNode. If this condition holds true, then any transaction that modified the Kafka subtree of zk-source would have been captured in the transaction logs of zk-dest and we are confident that the data in zk-dest is up-to-date.
In order to perform this check quickly during our migration, we modified the transaction log dump tool bundled with Zookeeper to print only the latest transactions instead of the entire log. In our case, the average log was about 500MB. Dumping the whole log would take around 20 seconds, even though we were only concerned about the latest transactions. We also found that using memory-mapped file I/O instead of standard file I/O further improved performance slightly. These changes reduced the time to extract the latest transactions from the log to around 1 second.
Since Zookeeper will be unavailable to Kafka during the migration, the controller will be unable to detect any brokers that go down during this time. If a broker fails, the controller will not elect new leaders for any partitions that have leader replicas on the failed broker. Since consumers and producers can only read from and write to leader replicas, and the replicas are offline on the failed broker, these partitions will become unavailable to consumers and producers. Depending on your producer retry policy, the offline leader replicas may cause new incoming messages to be dropped and lost forever. Thus, it is important to monitor the broker metrics in order to be aware if any brokers do fail. If this happens during the migration, we can either proceed with the migration and allow the controller to handle the failure once it resumes connectivity with the zk-dest at the end of the migration, or we can revert zk-dest hosts back as observers of zk-source and unblock network communications between zk-source and zk-dest to bring back Zookeeper availability to Kafka and allow the controller to handle the failure.
Preserving Zookeeper sessions during migration
Zookeeper clients (such as Kafka brokers) connect to a Zookeeper cluster through sessions. Ephemeral nodes are associated with these sessions — for example in Kafka, they include the controller and broker ID ZNodes. Ephemeral nodes are removed when sessions expire, and sessions are kept alive through client heartbeats. The Zookeeper leader is responsible for tracking all sessions and determining if they have expired.
Ideally, we want to preserve Zookeeper sessions across the migration because of how Kafka depends on these sessions and the associated ephemeral nodes. Specifically, we would like to preserve the ephemeral broker ID ZNodes (under path /brokers/ids) throughout the migration. During the migration, Zookeeper will only be unavailable to Kafka for a short period of time, but if the migration takes long enough, the Zookeeper leader may expire the session.
The Kafka controller checks for offline leader replicas by monitoring the ephemeral broker ZNodes and identifying which brokers are offline. If a Kafka broker’s Zookeeper session expires, its ephemeral broker ID ZNode will be removed. At the end of the migration, when Zookeeper becomes available again, if the broker does not reconnect to Zookeeper fast enough, the controller will detect the missing broker ZNode and assume the broker has failed. The controller will attempt to relocate leader replicas to other brokers to maintain partition availability, and once more back to the original broker when it reconnects. During this time, Kafka consumers and producers may experience disruption as they switch between the brokers holding the leader replicas.
For our migration, we had to work with the existing session timeout of 40 seconds in the zk-source cluster to avoid making any changes to the cluster. Since the leader determines session expiry, by blocking traffic between zk-source and zk-dest, we prevent the possibility of any existing sessions expiring in zk-dest (though they might still expire in zk-source) and avoid the aforementioned race condition.
Conclusion
Migrations can be tricky to execute, especially when trying to ensure no disruptions to users and no data loss on complex distributed systems like Kafka and Zookeeper, but through careful planning and testing, we were able to migrate with no downtime. This approach can be used on other systems that depend on Zookeeper, not just Kafka — ideally, such systems have low transaction rates to Zookeeper and are able to gracefully handle Zookeeper unavailability. Once again, we would like to acknowledge Yelp’s original blog post for the inspiration and proving that such a migration can be done without user impact.
Acknowledgements
Huge thanks to Xu Zhang, Tong Wei, Xuting Zhao, Meng Guo, and Mocheng Guo for collaborating closely and contributing invaluable feedback to ensure a successful migration. Also special thanks to Abhishek Parmar, Chandramouli Rangarajan, Chiyoung Seo, Jingwei Lu, Liuyang Li, Liyin Tang, and Zheng Liu for their help in reviewing the migration strategy. Finally, thanks to Brett Bukowski and Dylan Hurd for reviewing and improving this blog post.
Check out these related roles:
Senior Software Engineer, Storage & Database
Senior Staff Software Engineer, Backend Data Platform
Staff Software Engineer, Cloud Infrastructure
Senior/Staff Software Engineer, Analytics Infrastructure
Staff Software Engineer, Service Platform
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.