How we scaled the size of Pinterest’s ad corpus by 60x
Nishant Roy | Tech Lead, Ads Serving Platform
In May 2020, Pinterest launched a partnership with Shopify that allowed merchants to easily upload their catalogs to the Pinterest platform and create Product Pins and shopping ads. This vastly increased the number of shopping ads in our corpus available for our recommendation engine to choose from, when serving an ad on Pinterest. In order to continue to support this rapid growth, we leveraged a key-value (KV) store and some memory optimizations in Go to scale the size of our ad corpus by 60x. We had three main goals:
- Simplify scaling our ads business without a linear increase in infrastructure costs
- Improve system performance
- Minimize maintenance costs to boost developer productivity
This blog explains how we scaled a business-critical, high traffic recommendation engine and the benefits we saw from it.
Background
In 2018, here’s what the ads-serving architecture looked like:
Fig 1: Ads-Serving Architecture in 2018
- An offline workflow would run every few hours to publish the index of active ads to the system. The candidate funnel service would load this index in memory. Due to memory constraints, the funnel service had nine shards.
- Downstream clients would then call the ads mixer service, which would perform feature expansion
- Next, the candidate retrieval service would return a list of the best candidates for the given user and context features
- Then, the candidate funnel would enrich the candidates with index data, call the ranking service for scoring, and trim the candidates based on various rules (e.g. relevance, price, budget, etc.)
- Finally, the mixer service would run the auction to select the best candidates, assign prices, and return the ads to show to the user
This system served us well for a few years, but we soon started to run into a few challenges that were preventing us from scaling our ads business.
Challenges
As our ads corpus started to grow, so did our index size, causing our candidate funnel service to start hitting memory limits. A larger corpus is highly desirable; it improves the quality of ads that Pinners see, allows us to onboard more advertisers, and improves their ad delivery rates.
We considered a couple short-term solutions:
- Adding more shards: By growing the number of shards to be greater than nine, we could support a large ads index. However, this is an expensive and complex process. Adding more clusters would increase our infrastructure and maintenance costs, and it is not entirely future-proof (i.e., we may have to reshard again in the future).
- Vertical scaling: We experimented with EC2 instances that were twice as large and cut the cluster size in half to keep cost constant. However, we found that our service was concurrency bound, so the smaller fleet couldn’t handle the same amount of traffic. This would be a harder problem to solve and is also not future-proof.
Solution: Deprecate In-Memory Index
Rather than horizontally or vertically scaling the existing service, we decided to move the in-memory index to an external data store. This removed the need for shards entirely, allowing us to merge all nine shards into a single, stateless, ads-mixer service. This vastly simplified the system as well, bringing us down from 10 clusters to just one.
Fig 2: Ads-Serving Architecture now
Another benefit of removing the in-memory index was that it significantly reduced startup time from 10 minutes to <2 minutes (since we no longer needed to parse and load this index into memory). This allowed us to move from time-based cluster auto scaling to CPU-based cluster auto scaling, which makes our infra cost more reflective of actual traffic as opposed to dependent on hard coded capacity numbers that are not tuned frequently enough. It also makes our cluster more resilient to growth in traffic, since a larger cluster is automatically provisioned, without the need for manual intervention.
Garbage Collection CPU Pressure
The Go Garbage Collector (GC) is heavily optimized and provides good performance for most use cases. However, for systems with a high rate of allocation, Go GC starts to steal CPU resources from the main program to ensure the rate of allocation is not greater than the rate of collection (which would cause an OOM crash). As a result, Go GC becomes more expensive as the number of heap objects grows, since it needs to scan every object on the heap to identify what is collectible.
We found that our system was subject to this phenomenon, causing intermittent spikes of nearly 10% in CPU usage. This caused large latency spikes and drops in success rate, which meant we were losing potential ad impressions.
Solution: Heap Optimizations
We were able to reduce the number of objects on the heap from ~280 million to ~60 million, which significantly improved our system performance — almost a 10% reduction in tail latency and a 1% improvement in success rate. We achieved this by cleaning up unused data fields, reducing the number of long-living objects in favor of creating objects on demand, and pooling objects to reduce large allocation bursts.
Fig 3: Number of Objects on Heap for Ads-Serving
After entirely deprecating the in-memory forward index, we also saw the intermittent CPU spikes smooth out, making our system more stable and reliable.
Fig 4: CPU usage before and after GC optimizations
For more detailed information on how Go GC works, how it may cause performance regressions, and how to optimize your system’s performance, you may refer to this blog post or talk on Heap Optimization for Go Systems.
Scale & Latency
Now that the index data is in an external KV store, we need to introduce another RPC to fetch the data. Since we can’t process the ad candidates without this index data, we are blocked till we get the response back. Waiting for this response would increase our end-to-end latency by ~12%. This would impact our success rate, resulting in fewer ad impressions and degraded Pinner experience due to slower responses. We are also requesting data for millions of candidates per second, resulting in high infrastructure cost for the KV store cluster.
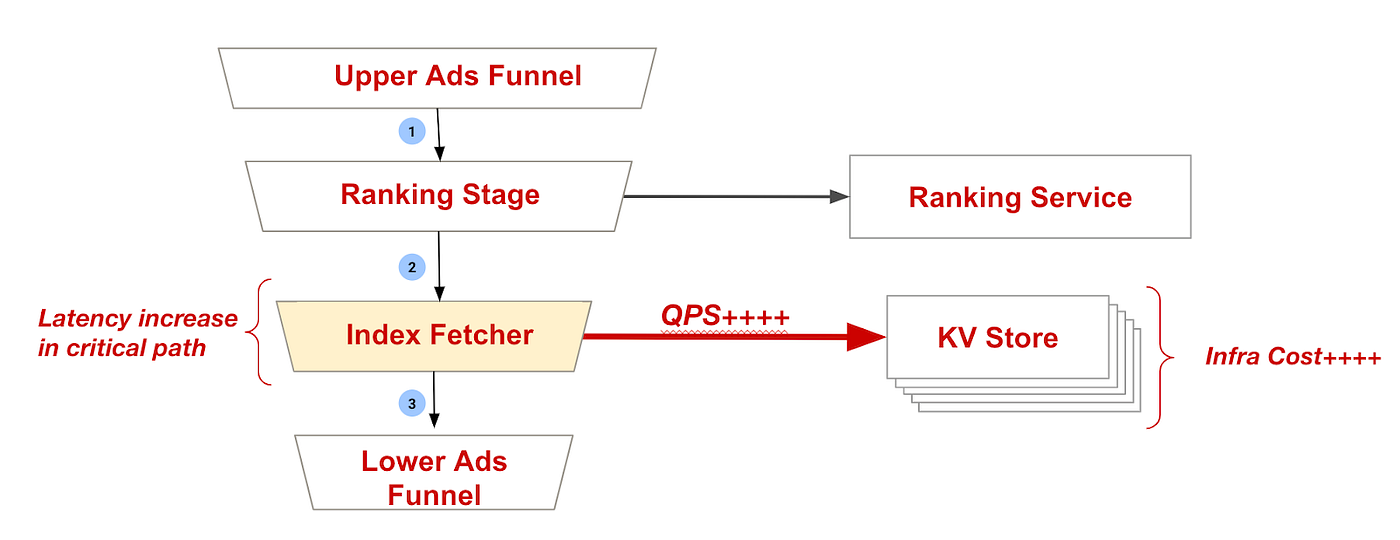
Fig 5: Increased ads-serving latency and infra cost to fetch index data from external KV Store
Solution: Parallelization and Caching
By running the index fetcher in parallel with the ranking stage, we were able to minimize the latency impact. Looking at Figure 5 above, we see that both the ranking stage and index fetcher are primarily blocked on RPCs. The ranking stage is the slowest stage in the funnel, so its latency typically dominates.
Fig 6: Parallelizing candidate ranking and index retrieval to minimize latency
Next, by implementing a local cache in the ads-serving funnel, we were able to reduce traffic to the KV store by ~94%. We set a low Time to live (TTL), on the order of minutes, to maintain a balance between high traffic and data freshness.
Fig 7: Adding a local cache to lower the QPS to the KV Store cluster, and minimize infra cost
Fig 8: Reduction in QPS to KV Store cluster due to local cache. 6% and 10% traffic refers to how much experimental traffic was being served by the new architecture.
Data Delay
Due to delays in the KV Store update pipeline relative to candidate retrieval, newly created ads were frequently missing from the KV Store index, preventing them from being served to the user. This delay was due to the fact that the batch workflows for updating the KV Store were run every few hours, while the candidate retrieval index was updated in real time.
Even for ads that were not missing, the data could be stale. Since this data includes ad budgets, we could potentially be serving ads that have already exhausted their budget, resulting in “overdelivery” (i.e. ad impressions that are not billable).
Solution: Real-Time Data Updates
By enabling real-time updates for the KV Store, we were able to reduce the number of missing candidates and improve data freshness from a few hours to a few minutes. Our KV store follows a lambda architecture pattern, which allows us to push real-time updates through Kafka in addition to pushing batch workflow updates.
Fig 8: Lambda Architecture with Batch + Real-time Data Updates
Fig 9: Drop in missing keys due to real-time index data updates
Conclusion
We redesigned our ads-serving architecture to address our memory and performance bottlenecks and prepare for future growth of the ads corpus. In fact, we were able to quadruple our ads index size in 2020, just a few months after launching this new system, with no adverse impact except for a slightly lower cache hit rate. We also greatly reduced the maintenance costs and on-call burden by vastly simplifying the system.
We were able to improve our system performance, reduce latency, and improve reliability, which resulted in an increase in ad revenue, ad impressions, and ad clicks. Our performance improvements also resulted in a large reduction in our infrastructure costs, since we were able to run at a much higher CPU utilization without any degradation in quality.
Acknowledgements
A huge shout out to everyone who helped make this multi-year endeavor a success. I would like to thank Shu Zhang, Joey Wang, Zack Drach, Liang He, Mingsi Liu, Sreshta Vijayaraghavan, Di An, Shawn Nguyen, Ang Xu, Pihui Wei, Danyal Raza, Caijie Zhang, Chengcheng Hu, Jessica Chan, Rajath Prasad, Indy Prentice, Keyi Chen, Sergei Radutnuy, Chen Hu, Siping Ji, Hari Venkatesan, and Javier Llaca Ojinaga for their help in the design and execution of this project.
To learn more about engineering at Pinterest, check out the rest of our Engineering Blog, and visit our Pinterest Labs site. To view and apply to open opportunities, visit our Careers page.