Improving data processing efficiency using partial deserialization of Thrift
Bhalchandra Pandit | Software Engineer
At Pinterest we’ve worked to greatly improve data processing efficiency. One quote that resonates with our unique approach is from writer Antoine de Saint-Exupéry: “Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.”
Ultimately, we process petabytes of Thrift encoded data at Pinterest. Most jobs that access this data need only a part of it. To meet our unique needs, we devised a way to efficiently deserialize only the desired subsets of Thrift structures in each job. Our solution enabled us to significantly decrease our data processing resource usage: about 20% reduction in vcore usage, 27% reduction in memory usage, and 36% reduction in intermediate data (mapper output).
Motivation
Pinterest is a data driven company. We use data for everything that matters to the businesses — including analytics, machine learning, experimentation.
We have many large datasets encoded in the Apache Thrift format, which is tens of Petabytes in size. We have a large number of offline data processing workflows that process those datasets every day. A significant portion of that processing involves deserializing Thrift structures from serialized bytes on disk. It costs us significant amounts of time and money to perform such deserialization. Any optimization that reduces this deserialization cost would yield considerable savings.
No suitable alternatives
Even though many data processing jobs require a subset of the fields of a Thrift structure, they must incur the cost of fully deserializing that structure before its fields can be accessed. That cost is significant considering that we have hundreds of such jobs, each processing terabytes of data every day.
One way to avoid the deserialization cost would be to use a format like FlatBuffers. Unfortunately, there are two issues with that approach:
- FlatBuffer encoding can take up about 20% more disk space than Thrift format. That matters when we are dealing with Petabytes of data.
- More importantly, a change of encoding requires code changes in all consumers of those datasets. That cost is significant when you have a large existing codebase.
Apache Thrift implementation provides rudimentary support for partial deserialization. However, there are two shortcomings that preclude its usefulness to us. First, it is limited to deserializing individual primitive fields. Second, there is no support that allows deserializing arbitrary subsets in a single pass.
We developed a novel solution to this problem by adding support for partial deserialization to Thrift.
Partial deserialization
We needed to solve three important problems:
- We must make it easy to define the set of fields to deserialize.
- We must deserialize the entire subset in a single pass over the serialized blob of bytes.
- We must keep the resulting implementation 100% interoperable with the standard deserializer. That way, one would not need any changes in the code that consumes the deserialized objects.
Defining the target subset
We needed to be able to select any arbitrary subset of the fields. Moreover, we wanted to express any complex nesting of fields without requiring a complicated constraint language or any additional code.
We came up with a simple scheme. We chose to define the fields to deserialize using a list of fully qualified field names.
For example, consider the following Thrift struct definition:

The following are valid definitions of fields to deserialize from OuterStruct.

The definition list can have any combination of such fully qualified names. The ability to use a simple list of strings allowed us to enable partial deserialization as a config-only change.
Figure 1 shows a fully deserialized OuterStruct versus the one partially deserialized OuterStruct for config structMap.value.stringValue.
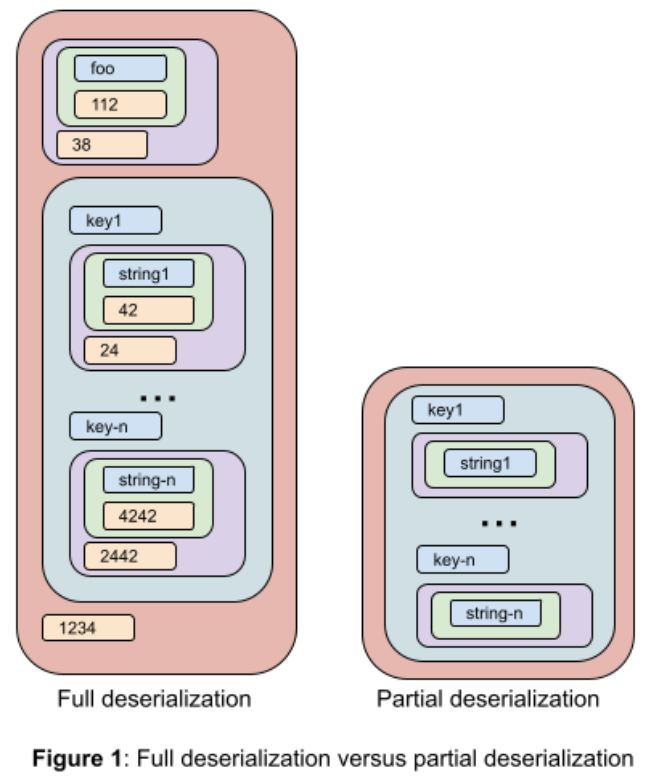
The list of fields is parsed and compiled into an efficient internal representation during initialization of the partial Thrift codec. The string form field list is not used after that.
Deserializing the target subset
Our implementation traverses serialized bytes in a single pass to selectively deserialize desired fields. Each time we encounter a field, we either deserialize it or skip without deserializing it. Fields are skipped efficiently by advancing internal offset within the serialized bytes buffer. Fields skipped in this way do not incur object allocation or garbage collection costs.
The deserialized fields retain their usual nesting under a single outer instance (for example, OuterStruct in the earlier example) just like full deserialization would. That way, the calling code does not need to change in any way in order to use the returned result.
Interoperability
Our implementation is 100% interoperable with the standard Thrift deserializer.
Results
So far we have used this solution in a variety of data processing stacks including Hadoop MapReduce jobs and Flink streaming jobs. We have found similar improvements in efficiency of those jobs. The following sections present results from a standalone benchmark and from various job runs. Note that the gains depend on the size and complexity of a Thrift object and the size of the partially deserialized subset. In general, the smaller the ratio of size of the deserialized subset to the size of all fields, the larger the overall efficiency gain.
Standalone benchmark
We wrote a standalone benchmark that repeatedly deserializes a set of 1,000 Thrift objects. We chose a Thrift object that is commonly used in many of our production jobs. This struct has 11 fields (nine primitive fields, one struct field, and one “list of structs” field). We compared the performance of fully deserializing this object versus partially deserializing only some of the fields in each object. We measured throughput and garbage collection metrics using the JMH framework. Figure 2 shows how they compared.
MapReduce job
We used this optimization in a large number of data processing jobs. We were able to obtain significant efficiency improvements as a result of its use. Figure 3 shows the resultant comparison.
There are two main categories of benefits:
Runtime resource usage reduction
- Lower CPU cycles are needed because we do not spend cycles deserializing fields that would never be used.
- Garbage collection pressure is reduced because we do not unnecessarily allocate unused fields.
Persistent storage reduction
- When the initial job uses partial deserialization and passes along the results to the next job in sequence, much less intermediate storage is used.
Future direction
Although we have already realized significant savings using this optimization, we are exploring additional enhancements:
- Contribute the enhancements back to the community: We’re looking into ways to bring these benefits to the larger community outside of Pinterest.
- Broaden the scope of applications: Currently we use this optimization in MapReduce-based jobs and Flink jobs. We are exploring broadening that scope to include Spark, Spark SQL, and some online services.
- Further improvements in deserialization efficiency: Additional efficiencies can be realized by modifying the scrooge generated Java/Scala code, which is friendlier to partial deserialization. We expect an additional 10~20% reduction in CPU usage as a result.
- Improved Thrift field access tracking: The current method we use for field access tracking has a number of limitations. We are considering a radical new approach that will not only make access tracking simpler but also much more efficient.
- On demand partial deserialization: Currently, one has to have prior knowledge of the fields to deserialize in order to initialize the partial deserializer. We are exploring some potential ways that do not require that prior knowledge. That is, the newer implementation will learn on the fly about the access pattern. It will make use of this knowledge to tune its deserialization efficiency.
To learn more about engineering at Pinterest, check out the rest of our Engineering Blog, and visit our Pinterest Labs site. To view and apply to open opportunities, visit our Careers page.