Bridging Affordability, Familiarity, and Novelty: DoorDash’s LLM-assisted personalization framework
A recap of our KDD 2025 PARIS Workshop talk: “Affordability, Familiarity, and Novelty: An LLM-assisted Personalization Framework for Multi-Vertical Retail Discovery.”
Imagine a world where every shopping moment, from a last-minute grocery run to a weekend gifting spree, feels effortless, personalized, and just right for you. At DoorDash, this is more than a vision; it’s our daily mission. As we expand beyond restaurants into new verticals like Grocery, Convenience, Alcohol, Retail, Flowers, and Gifting, we face a fascinating challenge: how do we help customers discover what they want, or what they didn’t know they wanted, across a catalog of hundreds of thousands of SKUs?
In August 2025 at KDD 2025’s PARIS Workshop in Toronto, DoorDash showcased its latest advances in personalization for multi-vertical retail. Sudeep Das, Head of New Verticals ML/AI, and Raghav Saboo, Staff Machine Learning Engineer, shared how we are reimagining discovery through a large language model-assisted personalization framework.
Our work blends traditional machine learning with large language models (LLMs) to dynamically balance three core value dimensions for consumers:
- Familiarity – surfacing the items you already love and trust
- Affordability – meeting you at your price preferences with the right deals
- Novelty – introducing you to new, complementary, and exciting products

Figure 1: Our Search and Personalization Framework is aimed at enhancing discovery by balancing three user value dimensions: familiarity, affordability, and novelty
We use this framing to decide what to retrieve, how to rank, and how to present across surfaces. The result is a paradigm shift. Personalization is no longer just about “what you might like” — it’s about what you might need right now, at the right price, and in the right context.
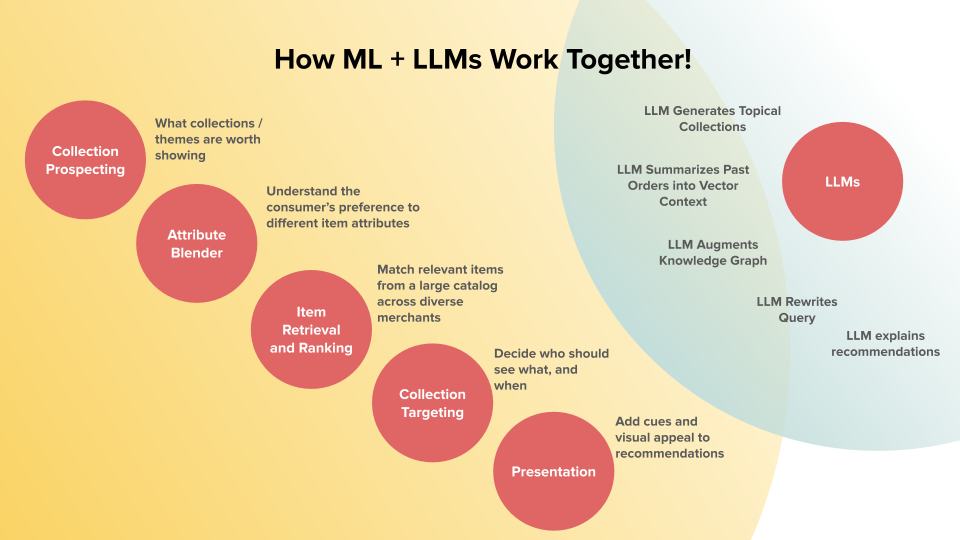
Figure 2: We utilize LLMs across the personalization stack from collection retrieval, ranking, to presentation
Our end-to-end pipeline organizes decisions into five repeatable steps—attribute blending, collection prospecting, item retrieval and ranking, collection targeting, and presentation with LLMs assisting throughout: generating topical collections, summarizing past orders into vector context, rewriting queries, explaining recommendations, and augmenting the product knowledge graph.
Think of it as a tight loop: classic recommender system does reliable retrieval/ranking at scale; LLMs inject semantic understanding and agility where text, concepts, cold start, and long-tail intent matter most.
Familiarity is about showing each customer what fits them right now — their favorites, their staples, and the items they’re most likely to need next.
We power this with a two-tower embedding model that learns both customer and item representations from sparse order histories, engagement sequences, numerical/context features, and pre-trained embeddings. At serving time, we score via dot product against an item-embedding index for efficient top-N recall — blending in recency, popularity, and reorder signals so results stay grounded and relevant.
Once we have a strong candidate set, we apply multi-task rankers with a mixture-of-experts design to optimize for multiple outcomes simultaneously — click-through, add-to-cart, in-session conversion, and delayed conversion. These models share a common representation but specialize per surface, balancing relevance with exploration.
The result shows up in:
- Category pages where the most relevant items rise to the top
- Check out aisles where complementary items help customers complete their baskets
- Personalized carousels that surface the most relevant collections on the home and store pages
Search benefits as well: two people may type “ragu” and mean completely different things — pasta sauce, a restaurant, or even a brand. By incorporating dietary preferences, brand affinities, price sensitivity, and past shopping habits, we make sure the ranking reflects each user’s true intent.
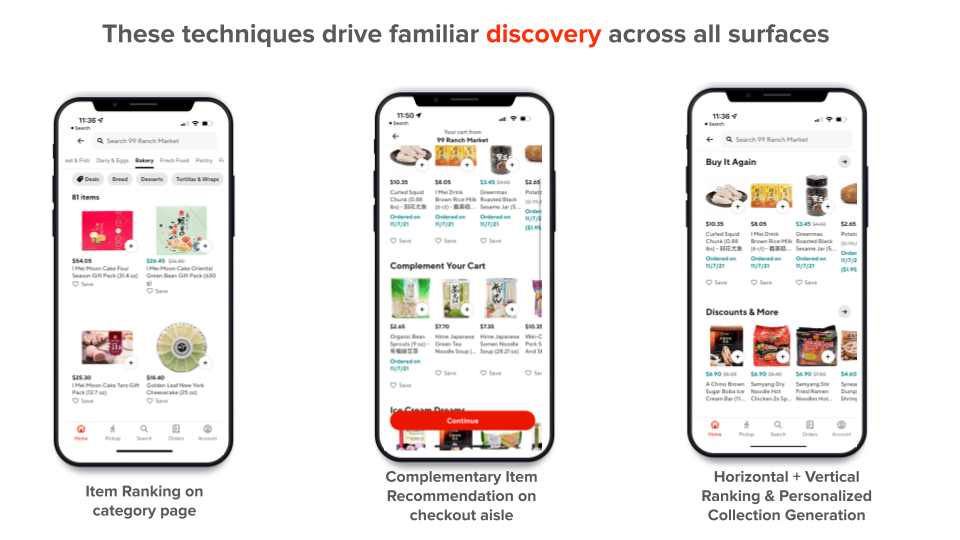
Figure 3: A few of our discovery surfaces across the app
Affordability isn’t just about showing the lowest price — it’s about finding the right value for each shopper’s context. Some customers want the most budget-friendly option; others are happy to trade up for higher-quality products, especially in their preferred categories.
To do this, we model:
- Price sensitivity – how responsive each customer is to price changes
- Bulk and size preferences – whether they prefer multipacks or single servings
- Stock-up behavior – when they’re topping up vs. doing a full pantry fill
These signals feed into a Value-to-Consumer optimization objective, which upranks the items that deliver the best value for that customer, meeting price expectations while also growing their basket value.
But price is more than static information. Our Deals Generation Engine actively pairs the right discounts with the right customers, within budget, efficiency, and marketplace constraints. This means:
- Customers see relevant, timely promotions
- Merchants move inventory more effectively
- The marketplace grows in a healthy, sustainable way
And because these deals are surfaced across discovery carousels, search results, and notifications, they’re visible at the moments that matter most.
Novelty is about inspiration, showing customers new items they didn’t know they wanted, but that fit their tastes. Done right, novelty helps customers build larger, more satisfying baskets; done poorly, it feels random and distracting.
We approach novelty in two ways:
- Intra-vertical novelty – surfacing new and complementary items based on co-purchase patterns and preference profiles, so suggestions feel natural (e.g., chips with salsa, oat milk with cereal).
- Cross-vertical novelty – translating restaurant history into retail discovery by combining consumer clusters with food and retail knowledge graphs. If you order ramen weekly, we might recommend instant ramen kits or Asian condiments in your next grocery run — turning past dining habits into future pantry inspiration.
The goal: make novelty feel like a helpful nudge, not noise.
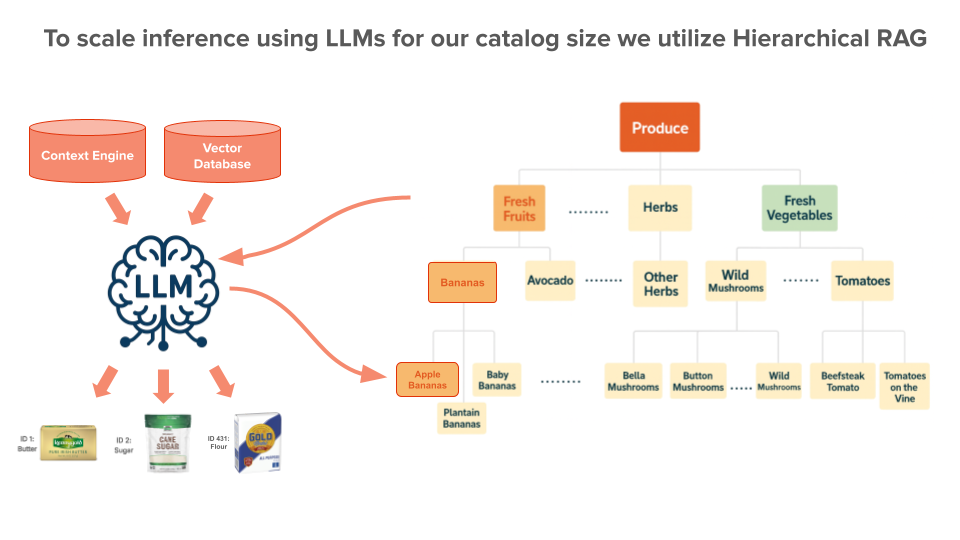
Figure 4: Hierarchical RAG to help us make the context for LLMs more precise in our pipeline
DoorDash’s catalog spans millions of items across thousands of merchants — a scale that makes naive prompting or brute-force generation impractical. To bring LLM reasoning to this reality, we’ve invested in two key infrastructure patterns:
- Hierarchical Retrieval-Augmented Generation (RAG) – Rather than dumping the entire catalog into a prompt, we narrow context using category trees and structured retrieval before calling the LLM. This keeps prompts compact, inference fast, and recommendations precise — even as the catalog grows.
- Semantic IDs – Compact, meaning-rich embeddings that encode catalog hierarchy. Semantic IDs unlock:
- Cold-start personalization for new users or items
- Free-text-to-product retrieval (“show me cozy fall candles”)
- Intent-aligned recommendations for tasks like gifting or recipe generation
- A shared semantic layer that powers recommendations, search, and future agentic workflows
These techniques make LLM-powered personalization scalable, cost-effective, and reusable across surfaces, a critical requirement for production ML systems.
Here are three principles that guided our work — and that we think are useful for anyone building large-scale personalization systems:
- Anchor on clear objectives. Framing everything around familiarity, affordability, and novelty gives us a simple way to balance trade-offs across retrieval, ranking, and presentation.
- Use each approach where it shines. Two-tower embeddings and MTML rankers give us scalable, reliable relevance; LLMs add semantic agility for collections, query rewriting, explanations, and knowledge graph enrichment.
- Building Scalable Abstractions Helps. Techniques like hierarchical RAG and semantic IDs make LLM contexts compact and shareable across search, recommendations, and other downstream tasks, improving both performance and cost efficiency.
We’re building the next generation of shopping — personal, affordable, and full of the right kind of new. If you’re excited about LLMs, recommender systems, and marketplace-scale ML challenges, we’d love to have you on the journey. Click here to see open Machine Learning roles.