基于词元叠加的高效预训练
Efficient pretraining with token superposition - Nous Research
使用token叠加进行高效预训练 - Nous Research

2605.06546
2605.06546
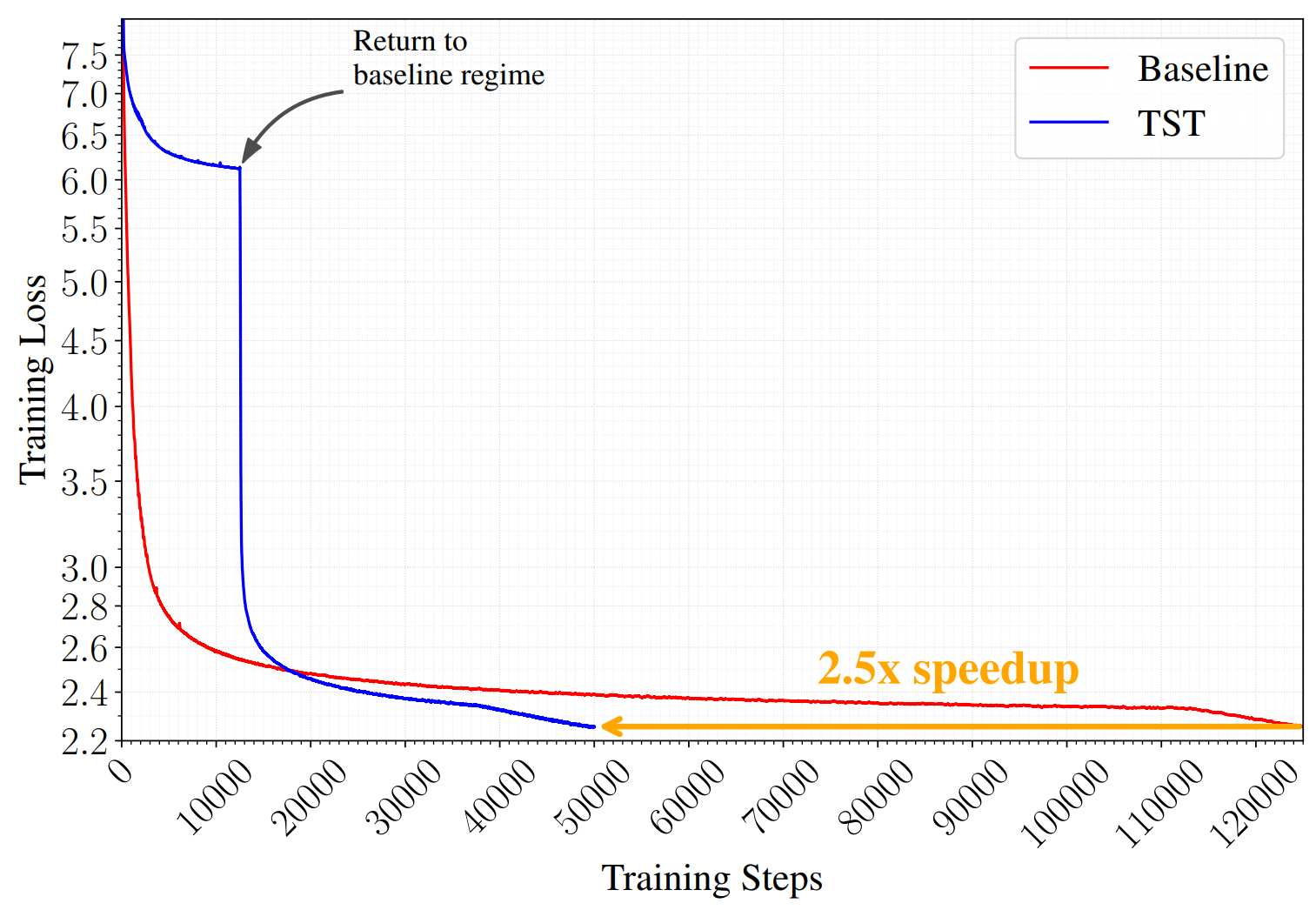
Figure 1. Loss curves during pretraining of two Qwen3-shaped 10B-A1B MoEs at matched FLOPs per step. The TST run consumes 2T tokens over its course; the baseline consumes 1.05T. The two runs are stopped at matched final loss, which is how we read speedups at iso-loss off the wall-clock axis.
图1. 在每步FLOPs匹配的情况下,两个Qwen3架构的10B-A1B MoE预训练期间的损失曲线。TST运行过程消耗了2T个token;基线消耗了1.05T。两次运行在匹配的最终损失处停止,这就是我们如何从实际时间轴上读取等损失下的加速比。
TL;DR. A 2–3× wall-clock speedup on LLM pretraining at matched FLOPs, without changing the final model architecture, optimizer, tokenizer, or training data. During the first 20–40% of training, the model reads and predicts bags of $s$ contiguous tokens — averaging their embeddings on the input side, predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining. Validated at 270M, 600M, and 3B dense, and at 10B-A1B MoE.
TL;DR. 在匹配的 FLOPs 下,LLM 预训练实现了 2–3× 的实际时间加速,且无需更改最终模型架构、优化器、分词器或训练数据。在训练的前 20–40% 期间,模型读取并预测 $s$ 个连续 tokens 的 bags——在输入侧对它们的 embeddings 求平均,在输出侧使用修改后的 cross-entropy 预测下一个 bag。在运行的剩余部分,它在 next-token 预测上进行正常训练。推理时的模型与传统预训练生成的模型完全相同。在 270M、600M 和 3B dense 以及 10B-A1B MoE 规模上进行了验证。
We introduce Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces substantial wall-clock speedups at fixed compute, without requiring any change to the model architecture, the optimizer, the parallelism strategy, the tokenizer, or the training data. On a 10B-A1B mixture-of-experts model trained to 2T tokens, TST reaches a lower final training loss than a matched-FLOPs baseline in roughly 40% of the wall-clock, and beats that baseline on HellaSwag, ARC-Easy, ARC-Challenge, and MMLU. The method consists of two phases: an initial superposition phase in which the model processes and predic...