DeepSeek MoE -- 一种创新的 MoE 架构
DeepSeek MoE -- An Innovative MoE Architecture
DeepSeek MoE -- 一种创新的 MoE 架构
Those who have been following DeepSeek’s work since DeepSeek V3/R1 might easily think that a significant portion of DeepSeek’s efforts are focused on engineering optimizations for efficiency. However, reviewing DeepSeek’s papers over the past year reveals that they have actually been continuously innovating in model architecture and training methods, with V3 and R1 being scaled versions based on previous architectural innovations. The DeepSeek MoE paper introduces the main innovations in MoE architecture by DeepSeek, which currently appears promising and could potentially become the standard for future MoE architectures.
自 DeepSeek V3/R1 以来,关注 DeepSeek 工作的人可能会轻易认为 DeepSeek 的大量努力集中在工程优化以提高效率上。然而,回顾过去一年 DeepSeek 的论文可以发现,他们实际上在模型架构和训练方法上持续创新,V3 和 R1 是基于之前架构创新的扩展版本。DeepSeek MoE 论文介绍了 DeepSeek 在 MoE 架构中的主要创新,目前看起来前景可期,可能会成为未来 MoE 架构的标准。
MoE vs Dense
MoE与Dense
First, let’s discuss the differences between MoE and traditional Dense architectures. Early LLMs were mostly based on Dense architectures, where every token generation requires activating all neurons for computation. This approach is quite different from how the human brain operates, as the brain doesn’t need to engage all brain cells for every problem. If it did, humans would be exhausted. Therefore, a natural idea is to no longer activate all neurons when generating tokens, but instead activate only those most relevant to the current task. This led to the MoE (Mixture of Experts) architecture, which divides neurons in each layer of the LLM into N Experts, with a Router selecting the K most relevant Experts to activate.
首先,让我们讨论 MoE 和传统稠密架构之间的区别。早期的 LLM 大多基于稠密架构,每次生成标记都需要激活所有神经元进行计算。这种方法与人脑的运作方式截然不同,因为大脑并不需要为每个问题都调动所有脑细胞。如果这样做,人类将会感到疲惫。因此,一个自然的想法是在生成标记时不再激活所有神经元,而是仅激活与当前任务最相关的神经元。这导致了 MoE(专家混合)架构的出现,它将 LLM 每层的神经元划分为 N 个专家,由路由器选择 K 个最相关的专家进行激活。
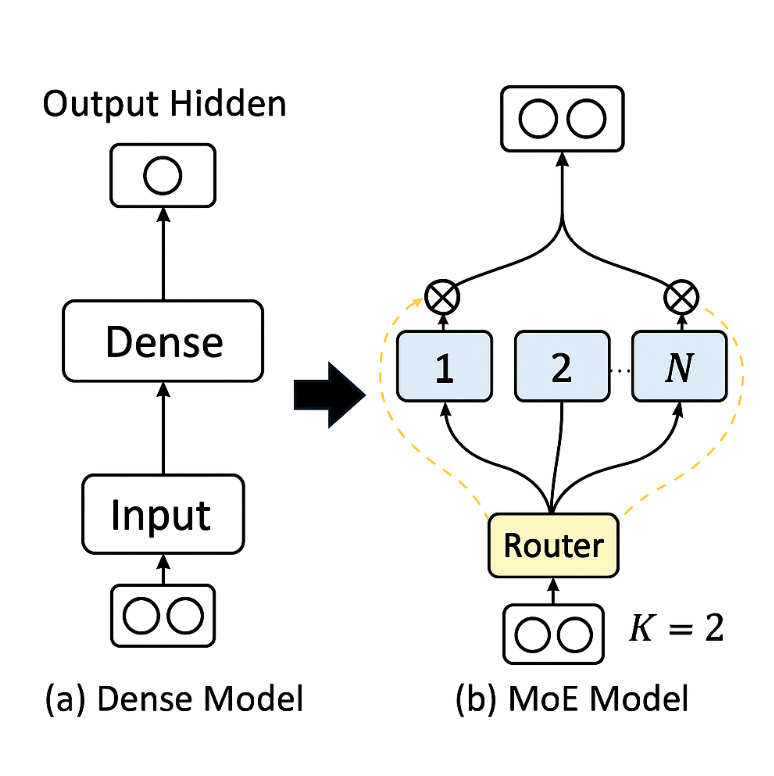
The benefit of this architecture is that during inference, not all neurons need to be activated, significantly reducing computational effort. In t...