The next generation of Data Platforms is the Data Mesh
Here’s why.
As enterprises become more agile, centralization appears more and more as a thing of the past world, a waterfall world. The same appears to be true with data platforms. Therefore, we are building a Data Mesh, this next generation of data platforms for PayPal Credit. This post details the evolution of data platforms, highlights their problems, and why we decided to build a Data Mesh. I will detail the four principles of the Data Mesh, how to get started, look at the architecture, and describe some of the challenges.
Evolution of data platforms
Before diving in the details of the Data Mesh, let’s review how the information industry came to this situation.
Sixty-five million years ago, dinosaurs… no, I will not go that far away in time. In 1971, Edgar Codd invented the third normal form, the key to relational databases. Soon after that, enterprises starting seeing the benefits of aggregating data, which opened the way to the creation of data warehouses.
With data warehouses came the need for more rigor in data management: you were creating a warehouse for data, so like in a logistics warehouse, aisles, shelves, and spaces must be clearly identified. You had to design the data warehouse to accommodate incoming data and build ETL (extract, transform, and load) processes to fill the warehouse. Enterprises were now capable to perform analytics to a new dimension. Unfortunately, warehouses are not very flexible and with the increasing number of data sources, onboarding data became complex.
Let’s imagine a retail company, Great Parts, with B2C and B2B activities. They have a few thousand stores across North America, a loyalty program, and they accept returns.
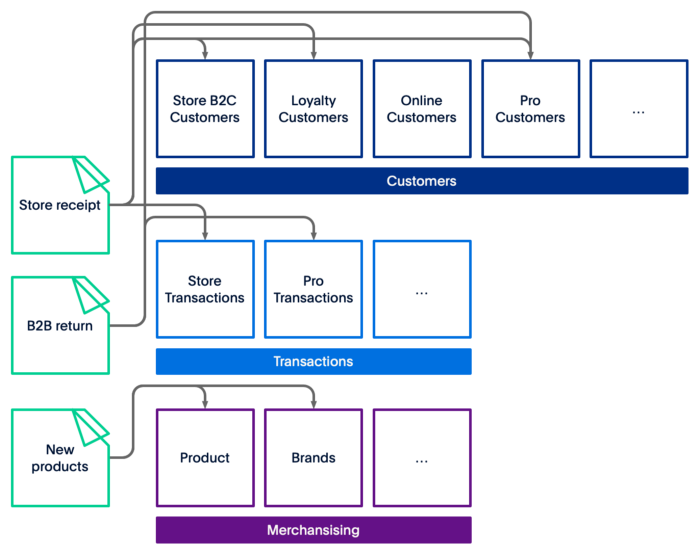
Figure 1 — Dataflows for new receipts, returns, and new products.
Now imagine Great Parts decides to expand their loyalty program to B2B; you will have to build an ETL process between the B2B returns and your customer space. If you are planning on adding a new data source like clickstream from your mobile application, your web applications, and your B2B sites. It will be increasingly complicated, and you will have to manage the ETL spaghetti.
As often in our industry, Great Parts decided to completely shift from the data warehouse to a data lake. The pendulum just shifted drastically. In a data lake, you collect all the data you want and store it. Wherever. You can see where this is going.

Figure 2 — Ingesting data in your data lake is much easier than with a data warehouse.
Now, it gets a little tricky when you try to consume your data — again. Storing is easy, however reading is complex. You can access the data by creating small data warehouses (databases or data marts) for your analytics loads, but you’re back to the ETL spaghetti. It is the same dilemma when it comes to operational processing through micro-services.
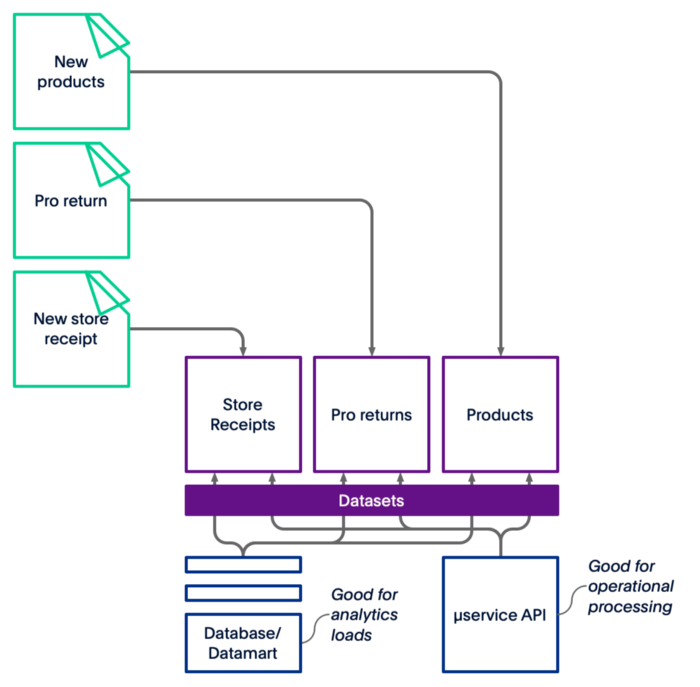
Figure 3 — Getting value from your data lake may be a bit tricky.
More recent architectures, like the data lakehouse, are trying to combine the best of the lake and warehouse, but they still lack the data quality, governance, and self-service features to ensure compliance with the enterprise and regulatory standards.
Opportunities
Unfortunately for some technologists, projects are not happening for the sake of technology; they are driven by opportunities and challenges. PayPal is not different. Let’s look at the opportunities that presented themselves as PayPal’s leadership considered a new data platform.
PayPal pioneered in self-service analytics, offering business analysts and data scientists access to our data warehouse very early compared to many companies. The success of this initiative, combined with PayPal’s willingness to move to the cloud, drove a need for a different type of data platform.
In addition to the self-service, data scientists’ needs have evolved with more data discovery capabilities. As with many companies, data sources have increased, whether internally, through acquisitions, or even from external sources such as data provider.
As the business has become more and more complex, a major driver was increased compliance and auditability, and the challenge became about marrying big data, self-service discovery, experimentation, compliance, and governance, while providing a clear path from data experimentation to production.
Our team at PayPal, GCSC IA (Global Credit risk, Seller risk, and Collections, Intelligence Automation) settled on the Data Mesh paradigm as it was the best suited for our customer needs.
The four principles of the Data Mesh
In May 2019, a brilliant engineer, Zhamak Dehghani, published a paper highlighting the basis of the Data Mesh. In her paper, Dehghani sets the ground for four principles, which, over the last couple of years refined into the Data Mesh’s four core principles. I like to compare those principles to how the agile manifesto disrupted the waterfall-based lifecycle in software engineering. Data Mesh is bringing to data engineering many of the concepts you may have been familiar with agile software engineering.

Figure 4 — The Three Musketeers’ motto was “One for all, all for one.” Illustration by Maurice Leloir for the Calmann-Lévy edition, Paris, 1894. Source: Wikipedia.
Let’s discover together those four principles.
1. Principle of Domain Ownership
The term “domain” has been so overused in the last decades that its meaning is almost gibberish. Nevertheless, let’s try to tame the domain and ownership in this context.
A domain is a specific area of business you are focusing on. If you are in the healthcare industry, it can be a hospital or a specific department such as radiology. Identifying the domain sets the boundaries and helps you falling into scope-creep situations (as in, let’s also include the hospital cafeteria in the project).
If you are familiar with domain-driven development, this principle will come naturally to you.
It is common sense: don’t try to boil the ocean. Find the people who know a domain best, and associate them with a data architect. The decentralized team has a precious domain expertise: they know more about the data sources, data producers, rules, history, and evolution of systems than a centralized team that switches from domain to domain. Adding the data architect in the mix will bring the security, rules, and global governance in order to stay compliant with the enterprise policies.
2. Principle of Data as a Product
In software engineering, agile replaced the project by the product. It was only a question of time before data became one as well. Let’s see what a data product can bring.
Focusing on a data product will enable you to switch from a project planning perspective to a customer-centric approach. Daunting? No, just DAUNTIVS, a data product must be:
- Discoverable,
- Addressable,
- Understandable,
- Natively accessible,
- Trustworthy and truthful,
- Interoperable and composable,
- Valuable on its own, and
- Secure.
In software architecture, the smallest deployable element is called a quantum. When applied to data architecture, the data quantum is the smallest deployable element bringing value. The data quantum is not related to quantum computing.
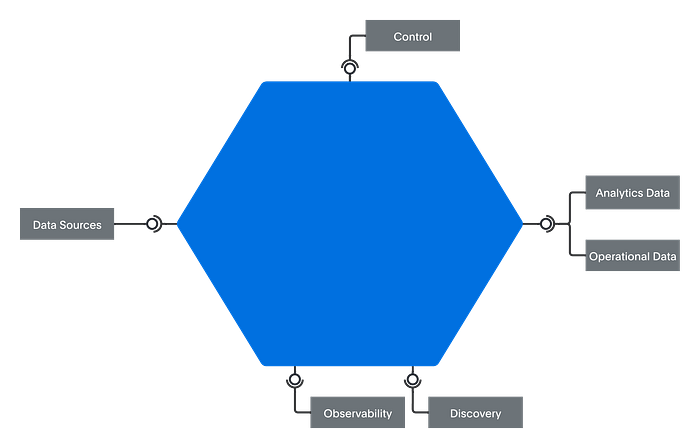
Figure 5 — The data quantum takes the shape of a hexagon, highlighting its multiple endpoints allowing access to data, metadata, observability, and control.
You’re probably wondering, “Hey, how is that different from my data lake with a couple of data governance tools?” The answer is that size matters: instead of an entire enterprise-level lake, you focus on a single domain. It’s definitely more “byte size” and chewable.
Thanks to its smaller size and scope, implementation is faster and the value from data is reinjected in the company a lot faster.
3. Principle of the Self-Serve Data Platform
When I was a kid, in France, I loved going to the local supermarket with my parents as it had a cafeteria where I could put on a tray all the food I wanted. The self-service empowered me to make (bad) food choices. But what does it mean when it comes to a data-platform?
Since its inception in 2001, Agile has proven to be a working methodology. Agile software engineering empowered software engineers. The way to empower data scientists is to give them access to data.
Data scientists and analysts spend (too much) time in their data discovery phase. In many situations, they find a piece of data in a random column in a table somewhere and take a bet on the fact that this is what they need. Sometimes it works, sometimes your PB&J toast does not fall on the jelly side.
Empowering the data scientists means that you must give them access to not only a basic catalog of fields, but precise definitions, active and passive metadata, feedback loops, and much more. They are your customers, you want to be this 5-star Yelp cafeteria, not this crappy 1-star shack.
4. Principle of Federated Computational Governance
Every word of this principle has a very important meaning. Let me try to convey to you their crucial interpretation.
Information technology has become so ubiquitous in our day-to-day life. States and governments have developed laws to manage how personal data is handled and used. Famous examples include Europe’s GDPR (2016), California’s CCPA (2018), and France’s National Commission on Informatics and Liberty (1978). Of course, those constraints are not the only push towards governance in enterprises; companies like PayPal often have data governance rules and protections that may go beyond what the law requires.
But why a push towards computational governance and not just data governance? Because data governance is simply too limitative. Even when you include metadata in your governance (and of course you do), you are still missing the entire eco-system of computational resources linked to your systems. In a modern cloud-based world, you must account for many more assets. It made sense to extend from data to computational governance.
Your data governance team creates policies applicable to the entire organization, which the domain team will follow to achieve enterprise-level consistency and compliance. However, the domain team owns the local governance at the quantum level, maximizing the team’s expertise.
Four principles
Like Alexandre Dumas’ Three Musketeers, who were four, the four principles of the Data Mesh are intertwined.
Each principle influences each other, and as you design and build your data mesh, you cannot look at one principle in isolation: you need to progress on the four fronts at the same time. It is easier than it seems as you will see how PayPal is building such a data mesh.
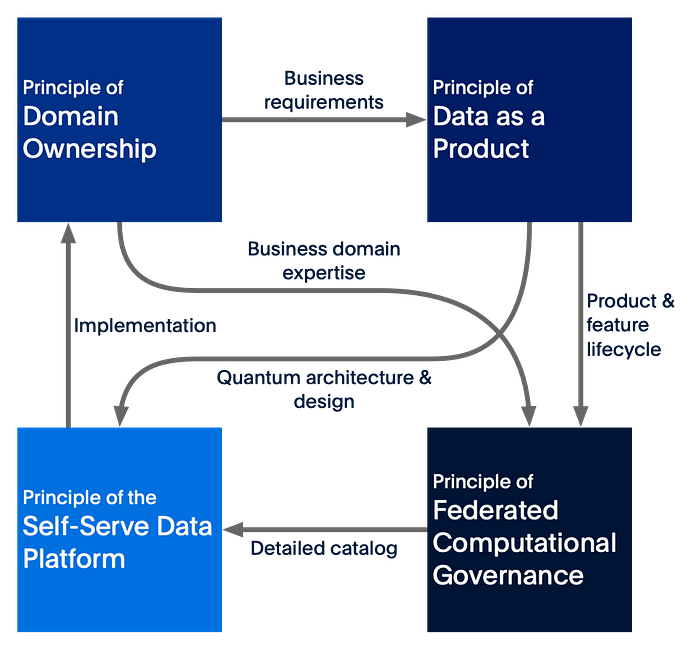
Figure 6 — An attempt at mapping the influences of one principle towards the others.
Building our first Data Quantum
Now that you have read about the motivation, opportunities, and governing principles, it seems about time to build your first data quantum, or, more precisely, architect it before you implement it.
Before building an entire data mesh, you will need to focus on each data quantum. The data mesh is a composition of data quanta.

Figure 7 — Unwrapping the data quantum, what’s inside?
You can divide the data quantum in five subcomponents:• The dictionary, • The observability plane,• The control plane,• The data onboarding, and
• The interoperable data.