Refactoring and Optimizing a High Traffic API at PayPal
By Nisha Bhaskaran and Jeetendra Tiwari

Photo by Jason Olliff on Unsplash
Experimentation is increasingly becoming the standard for enabling data-driven decisions to determine the impact of every product change. It is an integral part of the product lifecycle at PayPal. Experiment Lifecycle Management and Optimization (ELMO), our in-house experimentation platform, is used to iterate and measure the impact of new product features, improved user experiences, marketing campaigns, etc.
Client teams integrate with experimentation platform (using SDK’s) and make a service call (using evaluation APIs) for experiment evaluation in real-time based on the active experiment configuration and return the evaluated variant. Today, our focus will be on ELMO's evaluation APIs, which forms the crux of the problem statement.
The evaluation APIs are critical endpoints which serve billions of requests per day from flows across multiple domains at PayPal and support different channels (such as the web and mobile). Earlier this year, we noticed the experience of using the APIs was sub-optimal, especially for our adjacencies. The SLA did not meet the standards that we set for ourselves and was also causing reliability issues for our clients. Therefore, we embarked on a journey to optimize the performance of the APIs by identifying critical bottlenecks in the flow.
Defining performance
We defined Latency as network latency plus application request processing time. With our focus on optimizing the application request processing time, 3 parameters were chosen to define performance:
- Average latency
- 95th percentile
- 99th percentile
Complexity
To understand the complexity of our evaluations, let us first get a sense of what an experiment setup looks like.
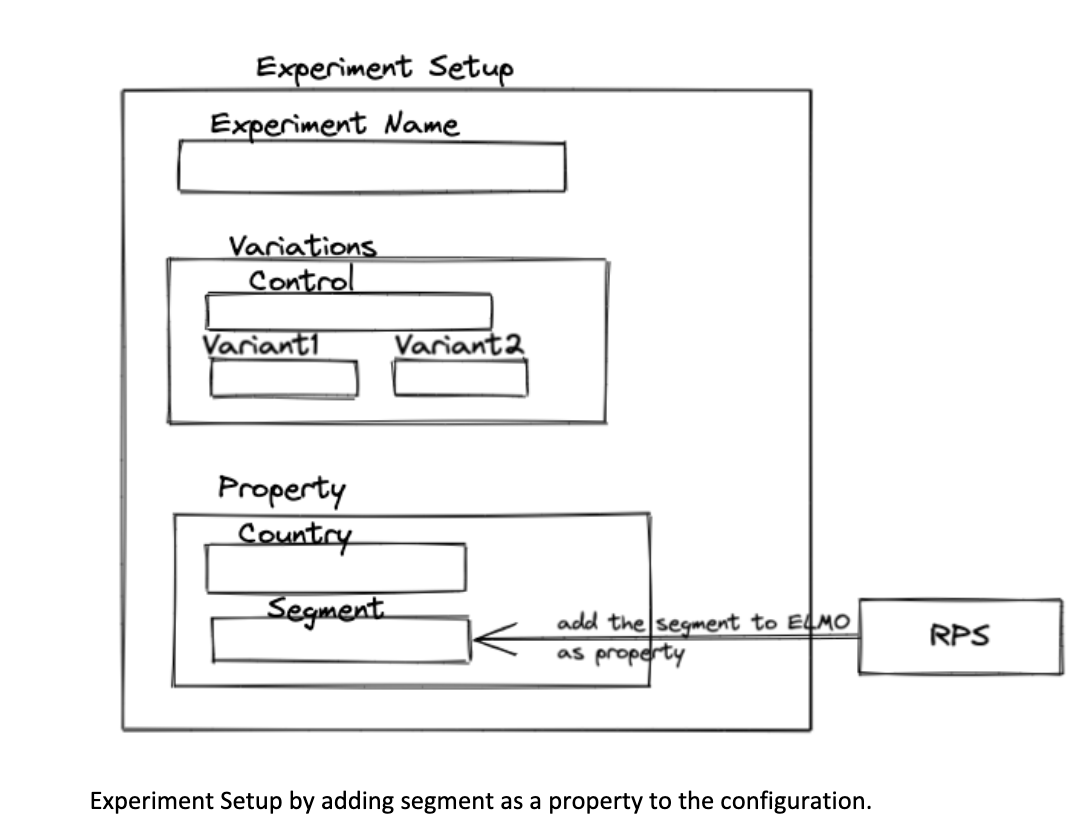
Experiment Setup
Each experiment in ELMO has a control (default behavior) and one or more variations which are the new experiences being evaluated. Clients define experiment population by different attributes (for example, country) and define segments or cohorts for an experiment.
To incorporate segments in experiments, Elmo is integrated with an in-house segmentation platform called Real-time Profile Store (RPS). RPS enables users to create segments or cohorts. Clients create or update segments in RPS and enable it for their experiment from ELMO by adding it as property in the experiment configuration.
Experiment Evaluation
During evaluation of experiments, we use an identifier string as the key. When a client makes a service call, we evaluate all experiments that are associated with this key. For each key, there can be X experiments. And for each experiment, there can be Z treatments. Therefore, during evaluation, each user is evaluated against X * Z combinations.
Moreover, for experiments that have a segment or cohort defined, we make a service call to RPS that conducts real-time evaluations, checking to see if the user or account id is part of that segment. Also, for post experiment analysis, measurement, and insights, we send events to a data acquisition service.

High level evaluation flow. Evaluation API calls are marked in orange
Baseline Evaluation
As with any optimization process, the first step was to set the baseline for these APIs. Once baselines were set, bottlenecks were identified.
Bottlenecks Identified
- Sequential load of experiments in case of cache miss — experiments were loaded in a sequential manner for a given identifier if they are not found in cache.
- Using RxJava for the complete flow was a good strategy to parallelize tasks but resulted in every step being put in a BlockingObservable that became almost sequential.
- Redundant service calls to other services.
Optimization Techniques
We spent time analyzing the baseline results, debugging, and identifying the bottlenecks. Once those were identified, we resorted to optimization techniques to improve performance:
- The flow was broken down to a mixed mode of RxJava + non RxJava, so that we could parallelize where needed and consolidate I/O calls wherever possible.
- The loading of experiments was isolated to evaluate RPS segments in bulk for all experiments associated with an identifier name for a given combination of user and segment evaluation type. This was done to avoid evaluating the segments for each experiment separately.
Segment Evaluation

E1, E2 = experiments, U1 = audience, Seg1, Seg2, Seg3, Seg4, Seg5 = segments in RPS which are added as properties in ELMO for runtime evaluation.
Outcome

Conclusion
The optimization outcome result shared reflects the SLA gain based on data per day. This was a good starting point in our journey to scale our platform. We also have clients performing the experiment evaluation locally which caches the active experiment configuration and properties. This further helps reduce the number of evaluation API network calls and contributes to our efforts to scaling our platform.