Pinterest’s Analytics as a Platform on Druid (Part 3 of 3)
Jian Wang, Jiaqi Gu, Yi Yang, Isabel Tallam, Lakshmi Narayana Namala, Kapil Bajaj | Real Time Analytics Team
This is a three-part blog series. Click to read part 1 and part 2.
In this blog post series, we are going to discuss Pinterest’s Analytics as a Platform on Druid and share some learnings on using Druid. This is the third of the blog post series, and will discuss learnings on optimizing Druid for real-time use cases.
Learnings on Optimizing Druid for Real Time Use Cases
When we first brought Druid to Pinterest, it was mainly used to serve queries for batch ingested data. Over time, we have been shifting to a real-time based reporting system to make metrics ready for query within minutes of arrival. Use cases are increasingly onboarded to a lambda architecture, with streaming pipelines on Flink, in addition to the source of truth batch pipeline. This creates a big challenge for the reporting layer on Druid: the biggest real-time use cases we onboarded has the following requirement: the upstream streaming ETL pipeline produces to the kafka topic Druid consumes with over 500k QPS, and expects the ingestion delay on Druid to be within one min. The expected query QPS is ~1,000 and P99 latency is ~250 ms.
In memory bitmap
While onboarding the use case, we first ran into bottlenecks on serving the real time segments running on peon processes on middle managers. Initially, considerable numbers of hosts were added in order to meet the SLA, but the infra cost soon became non-linear to the gain. In addition, with so many task counts and replicas, Overlord stressed a lot handling requests from peons when processing segment metadata. The large number of hosts were needed to provide enough processing threads and there is no way to reduce them unless each processing thread’s work, to scan a segment, becomes more efficient. We profiled and found the query logic for real time segments was inefficient: when data is first ingested into the real time layer, it is first put in an in-memory map which doesn’t have the inverted index that the batch ingested druid segments do, which means every query to real time segments will do a full scan of every single row to get the candidate rows to aggregate. For most of our use cases, the candidate rows to aggregate for each query represent a very small percentage of the total number of rows in the segment. We then implemented in-memory bitmaps when querying unpersisted real time segments. This resulted in a reduction of nearly 70% of the middle manager capacity for all the real time use cases we have while providing better latency.
Figure 1: Use case 1 P99 latency reduction on Middle Managers
Figure 2: Use case 2 P90 latency (ms) and infrastructure cost reduction on Middle Managers
Partitioned Real Time Segments
We had made good improvement on reducing CPU on processing individual segments after adding the in memory bitmap. However, we found we still fall short of processing threads because of the huge number of segments to process due to segments being unpartitioned. This was a problem when real time segments were served by peons on middle managers and when segments were finalized and served by historicals before compaction jobs kicked off a few hours later. The use case we have has the nature of many late events with timestamps spanning across the past 48 hours. This created a big burden on Druid because the number of segments to create for each hour is proportional to the number of late message time windows we accept. After some benchmarking, clients agreed to use a 3-hour late message acceptance window to catch the majority of the events. This is better than the 48-hour late message window before but still proposed a great challenge to the system. When the QPS is high, the constant multiplier matters. Imagine we need 250 tasks to keep the ingestion delay within 1 mins, with 3 hours late message window, the number of segments for the current hour is at least 250 * 3 = 750. Each single query needs to scan 750 segments and with 1000 QPS, the number of segments to scan each second is ~750 * 1000 = 750000. Each segment in Druid is processed by a single processing thread and the typical number of processing threads is set to equal to the number of available CPUs in the host. Theoretically we need 750000 / 32 = 23437 32-core hosts in order not to queue any segments, but the infra cost would be unmanageable.
In reality, the efficiency lies in the fact that events are scattered around all segments. For most of the real time use cases in Pinterest, each query comes with an id to filter on, e.g., pin_id, so if we can partition segments based on id, it will give us an opportunity to prune segments and limit query fanout. In batch ingestion, partitioning is possible because we can do arbitrary shuffling in the ingestion process, while in real time ingestion the data ingested into each segment is based on the kafka partition each consumer in the peon process was assigned to. So we let the upstream stream processor use a custom kafka key partitioner. The partitioning was done in a hash based mechanism and the real time segments adopted a corresponding custom shard spec which also has metadata on the kafka partitions that the segment is created from. During query time, Brokers can rehash the id in the filter to determine whether a given segment possibly contains data for the id. Hashing of an id leads to one kafka partition and thus one segment. With this in place, the number of segments to scan per segment is reduced by a factor of 250, dropping from the original number of segments to scan / task count (750000) to 750000 / 250 = 3000 segments, which requires 3000 / 32 = 93 32-core hosts — a much more manageable number than before.

As a follow up, we also extended the custom shard spec to have another field, fanOutSize, to hash a given partition dimension value to multiple segments to address potential data skewness issues in future use cases.
Bloom Filter Index on Real Time Segments
With the partitioned real time segments, the query segment fanout dropped significantly; but the number of CPUs needed is still high. The 3000 segments to query in the calculation above is only for an hour. Typically queries of our real time use case ask for data from now to 24 hours ago. For various reasons, it takes 8 hours before the compaction kicks in to compact the real-time segments 8 hours ago. By that time, the number of segments to query is reduced by 3 times because the 3 segments introduced by late events were compacted, so many fewer CPUs are needed for segments older than 8 hours ago. On the other hand, for the most recent 8 hours segments, 3000 * 8 = 24000 needs 24000 / 32 = 750 32-core hosts.
With more profiling on query patterns, we found that although the cardinality of the ids in the filter is large, not all ids have new data in a given hour. The hash based real-time segment partitioning doesn’t have enough metadata to do individual id level existence check because hashing will result in at least one segment potentially containing data while in reality that segment doesn’t have any data to return for the majority of the case. With high QPS and late events, the false positive on one segment to scan matters.
We didn’t find a good way to address the above issue on the real time segments served on peons on middle managers. They keep having new data flow in, and we don’t know if data for a concrete id will arrive or not until the segment is finalized and published to historicals. Meanwhile, because the pruning logic based on metadata in a shard spec of a segment is evoked on brokers while up-to-date information on what data is in a segment is known on peons, there is no way to sync what specific ids are in a segment in real time between two different components without metadata correctness. Since this is only one hour, we left the unfinalized segments untouched.
On the other hand, when finalizing real-time segments on peons, we have a full understanding of the data in the segment. Therefore, we added metadata to the shard spec — that data is initially ignored by brokers when segments are served by peons on middle managers, but later picked up when historicals load the finalized version of the segment. For the specific metadata, we used a bloom filter to the shard spec to store the ids which is a good probabilistic structure balancing size and accuracy. Only a few MBs are needed to get 3% expected false positive rate for ids of a million cardinality in a segment. With this change, we were able to reduce the number of segments to scan by 5 times for the last 8 hours in total. The above calculated number of CPUs needed became 750 / 5 = 150 32-core hosts, which is much more cost effective than before.
Figure 3: Use case 1 number of Segments to Scan
Figure 4: Use case 1 processing thread usage on historicals
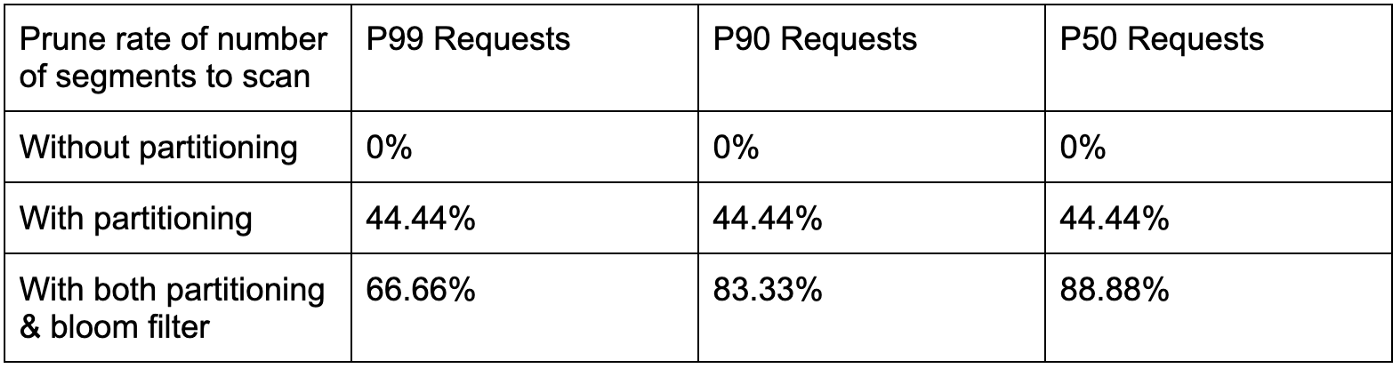
Table 1: Use case 2 prune rate of number of segments to scan
Future work
There are still many areas to improve, including but not limited to continuous compaction, Kafka topic scaling event compatible real time partitioning, large task count and late message window scalability improvement, etc. At the same time, we are also going to be more active on open sourcing what we have developed so far.
Acknowledgements
We have learned a lot from the discussions in the Druid Guild with Ads Data team and the feedback from the open source community when we started contributing back our work. We would also like to thank all the teams that have worked with us to onboard their use cases to the unified analytics platform: Insights team, Core Product Data, Measurements team, Trust & Safety team, Ads Data team, Signal Platform team, Ads Serving, etc. Every use case is different and the platform has evolved a lot since its inception.
To learn more about engineering at Pinterest, check out the rest of our Engineering Blog, and visit our Pinterest Labs site. To view and apply to open opportunities, visit our Careers page.