PinPoint: A Neural Inductive Attribute Extractor for Web Pages
Jinfeng Zhuang | Software Engineer, ATG Applied Science
Despite the explosive growth of the internet over the past couple of decades, much of the digitized knowledge has been curated for human understanding and has stayed unfriendly for machine comprehension. Even promising efforts towards creating semantic web like the Resource Description Framework in Attributes (RDFA), Ontology Web Language (OWL), JSON-LD, and Open Graph Protocol are in infancy and fall short for commercial applications due to data sparsity and high variance in data quality across websites. Hence Web Information Extraction (WIE), colloquially known as scraping, is the dominant knowledge acquisition strategy for several organizations in advertising, commerce, search engines, travel, etc. For our purposes, Pinterest uses this approach to bring high-level information (like price and product description) from saved websites to the Pin-level, to help provide Pinners with more information, along with a link back to the original website for more details, and to ultimately take action.
Formally, Web Attribute Extraction (a sub-branch of WIE) is defined as the task of extracting a value for domain-specific attributes such as Title:Marissa Henley Dress, Price:128.00, ItemID:№58632704, etc. for an entity (product in this case) from a webpage as illustrated in Figure 1. This is a challenging task for simple rule-based extraction systems (like XPath, Regex) because:
- Each website has a unique layout, making it impossible to configure a universal rule
- Even within a website, there may be multiple layouts, making it tedious to manually configure backward-compatible rules
- Website layout changes frequently require reactive and disruptive repairs
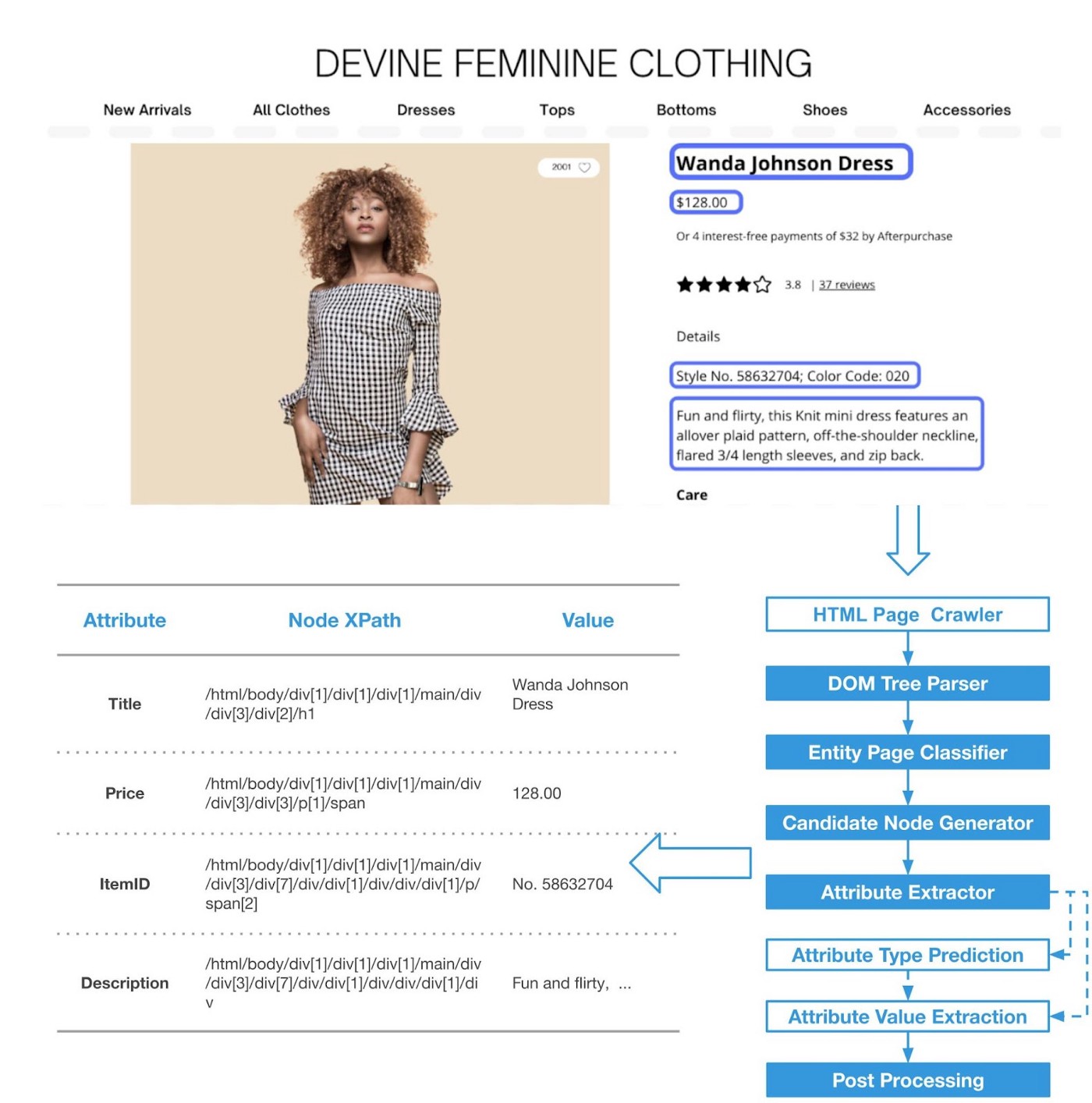
Figure 1: Left: PinPoint shopping attributes in a product page. Right: PinPoint workflow.
In practice, organizations use a combination of manually crafted, site-specific extraction rules and machine-learning approaches, notably Wrapper Induction (WI), to harvest the data from the web. WI-based extraction algorithms rely on a human-in-the-loop to label attributes for a few web pages that are then generalized to create extraction rules, also called wrappers. Due to their ability to achieve 95+% precision robustness to minor modifications of website layout, wrapper-based techniques are extensively used in the industry. However, WI systems are notorious for undetectable type 1 failures due to temporal changes and partial matching during the induction phase. Finally, WI algorithms haven’t evolved to transfer learnings from one website to another based on training examples. In the rest of the paper, we differentiate this capability and report in-domain and cross-domain performance for these algorithms. More recently, researchers proposed DNN models, e.g., FreeDOM, to learn representations of nodes and transfer them to unseen domains. However, such cross-domain extraction accuracy is around 90%, which is encouraging for research purposes but does not meet the bar for industrial applications.
WAE at Pinterest
Pinterest contains the biggest online collection of curated, inspirational web content (Pins) on a wide variety of topics such as recipes, fashion, products, travel, and services. Thus, WAE is essential for us to provide a rich user experience by showing visually appealing images along with relevant attributes to help Pinners take action.
Even though our algorithms generalize across different categories, for the sake of specificity, we deliberately restrict our examples to the shopping domain. For a given product, we extract 16 attributes like ID, title, image, description, price, color, size, review ratings, etc., as shown in Figure 1. We use this information to categorize products into a taxonomy for navigational purposes, build search engines to facilitate content discovery, recommend systems to pivot to closely related products, and finally to build detailed page experience to help customers compare and contrast products before making a shopping decision. Another challenging aspect in this domain is that some of the attribute values like price and availability fluctuate daily, while entire layouts can change quarterly to accommodate seasonal collections. Therefore, it is critical for the WAE solution to be robust to temporal drift, easy to train, and cost effective while scaling to a large number of domains. Finally, as a guiding principle, we prefer to not show an attribute value than to present wrong information as it erodes our customer trust.
We present the PinPoint system, which extracts attributes with as few as the one-shot label and achieves SOTA 95+% accuracy on domains unseen at training time. This system essentially turns the whole web into a big key-value store so that we can build end-to-end experiences across various aforementioned use cases. At the core of the system lies a graph neural network that learns to project DOM nodes into a metric space where node identity and edge relationships are preserved. Fundamentally, our approach is an inductive one, because we learn a function that embeds any DOM node across all websites instead of learning an embedding/wrapper that does not generalize to new websites. Because of this property, we are able to use the same model for new attributes as well as for unseen website layouts with as few as one training example.
The main contributions of this blog are:
- A cross-domain attribute extractor that is robust and can scale up with very few labels
- A new practical approach for embedding HTML DOM nodes
- A Graph Neural Network inspired approach to identify DOM nodes in a webpage
Proposed System: PinPoint
We first present our online system workflow, and then we discuss the machine-learning workflow.
High-Level Extraction Workflow
DOM Tree Parser: It accommodatingly parses the HTML page ? into a DOM tree T even when it is malformed. Node features are extracted by traversing this DOM tree structure.
Page Classifier: We use a separate machine-learned classifier that decides if a given webpage is an entity page before attempting to extract attribute values. Based on the contents of the page, the vertical (shopping or travel, for example) is also determined and attributes to be extracted are determined.
Candidate Node Generator: It selects a good set of candidate nodes on a given page. The ML inference only works on this selected set. This helps both the inference efficiency and the prediction accuracy. We employ a simple heuristics in PinPoint: the nodes with depth in the DOM tree in a range [min_depth, max_depth].
Attribute Extractor: After we have a candidate set of nodes, we have an extractor module that outputs the value for the predefined attribute for that vertical. It is further separated into two sub-components: attribute type prediction and attribute value extraction. The former one tells us if a node contains a particular attribute type. If the answer is yes, the latter will extract the values from this node. In most cases, the node text will be the attribute value. However, there are also cases where we need to design some rules or look into several node attribute predictions to derive the value. In this paper, we focus on the attribute type prediction part, where a DNN model learned offline plays a core role. We define the problem and notations in the next subsection.
Post Processing: The desired value for an attribute may be present in node text, attributes, or only partially present across multiple nodes. We use heuristics-based rules to extract the final value. For example, 1) for the image attribute, we use the source node attribute value, 2) for the price attribute, we look for a number prefixed with a currency symbol. We have rules, created using domain knowledge like the ones described above, that work across different websites.
A Machine Learning View
Our solution involves learning a function h that embeds all the DOM nodes of a webpage in a metric space, which preserves semantic information and structural relationship to other nodes within a page, as well as node identity across webpages. At inference time, we identify attribute nodes with similar representation on unseen pages. At a high level, we decompose our solution in to four logical steps:
- Featurization: In this process, we extract features ? (? ) about the labeled node such as tag name, class attribute value, id attribute value, node text, num siblings, num children, node depth, etc., similar to the ones in classic wrapper induction systems. An important difference that helps us scale is that the featurization function is universal and not customized per domain.
- Representation: The goal of the representation layer is to project discrete features of the node from the previous step into Euclidean space: h : ? → R? such that it can be passed to the learning and inference phases. Technical details of embedding generation are dependent on the feature itself and are explained in the next section.
- Learning: Using the labeled pages ?, we train a supervised machine learning (ML) model h (?) end-to-end, which can in turn be used to generate the embedding for a given node. We choose the labeled node as a positive node for the attribute and use a combination of random nodes and siblings of the positive nodes as negatives while training the model. We use a classification loss but note that supervision based on triplet loss or ranking loss had negligible impact to the final performance and hence omit those experiments for brevity.
- Inference: Once the model has been trained, the first step in the inference is to derive attribute embeddings ? := h(?(?)), which is the same as the embedding of the labeled node ? on the page ? for that attribute. This step is only required once per website. The next step is to create ? for all the nodes of the target page. The attribute of interest is the one that is closest to ? as long as it crosses a predetermined threshold ? : 0.9. When there are multiple training examples, we use the same process and find the node closest to the majority of the vectors in training examples for that attribute.
The Model
We start from the forward representation because it plays a central role for our model.
Neural Representation
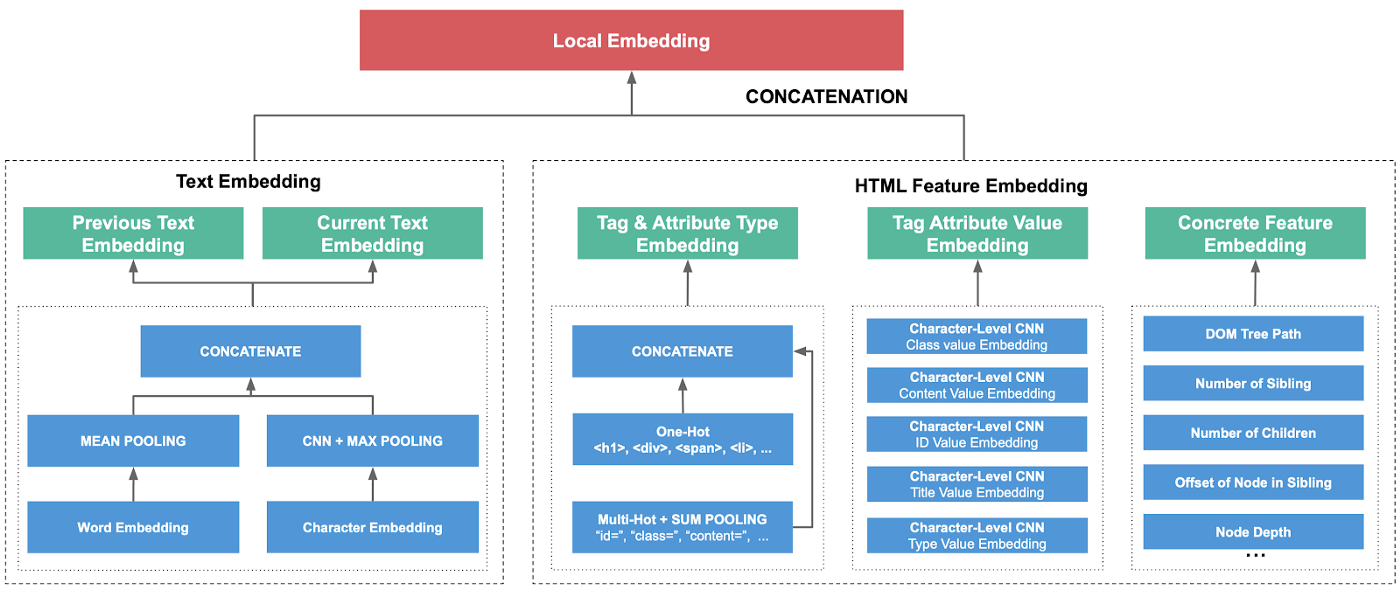
For a particular DOM node, it is of the utmost importance to design the DNN modules carefully such that the embedding vector can generalize best. We employ different DNN modules to model different features of a node.
Node Text Embedding: We use the concatenation of average word embeddings and character-level Convolutional Neural Networks (CNN) embeddings to model the node text. We run this on both current node text and the previous node text. Note that we work on word-level embedding and character-level embeddings independently to capture different granularity. We do not use more complex models like LSTM or BERT (Bidirectional Encoder Representations from Transformers) because a simple average of embeddings like fastText is a strong baseline in classification tasks. We use this technique for both the current node text embedding and the previous text embedding, because the leading text is often very indicative. Formally, we have the node text embedding:
hTEXT := CONCAT[MEAN(word), CHAR-CNN(text seq)]
HTML Tag Type Embedding: We simply map each HTML tag to an embedding vector by a lookup. This tag type embedding dictionary is a learnable variable.
HTML Tag Attribute Value Embedding: In addition to the tag type, the tag attribute value is a discriminating feature too. For example, the HTML tag for the title in the cover Figure 1 is:
Marissa Henley Dress, where the CSS class value contains “heading,” indicating the node attribute type is “title.” We use character-level CNN with filter size
3 to 7 to model them. We believe raw character-level ngram can generalize better than word-level ngram. Formally,
hATTR_VALUE := MAX-POOL(CHAR-CNN(tag attribute text))
DOM Tree Path Embedding: Each node in the path consists of two parts: the HTML tag and the offset of the tag among its siblings. For example, “div[2]”, which means the DOM node is a “div” tag and it’s the second child of its parent. We use LSTM on top of the lookup embedding of both the tag and the offset:
hDOM_PATH := LSTM[CONCAT[tag embedding, offset embedding]]
Concrete Feature Embedding: Other than the feature above, there are quite a few predictive concrete features. We map them into embedding vectors by lookup operation. Some representative examples include:
- Number of Children
- Number of Sibling
- Offset of Node in its Sibling
- Node Depth
- Having a Particular HTML Attribute, e.g. “class”
The final forward Local Embedding vector is:
h(?) := CONCAT[ Previous Text Embedding, Text Embedding,Tag Type Embedding,Tag Attribute Value Embedding,DOM Tree Path Embedding,Concrete Feature Embedding],
Details about these local embeddings are displayed in Figure 2.
Contextual Inference
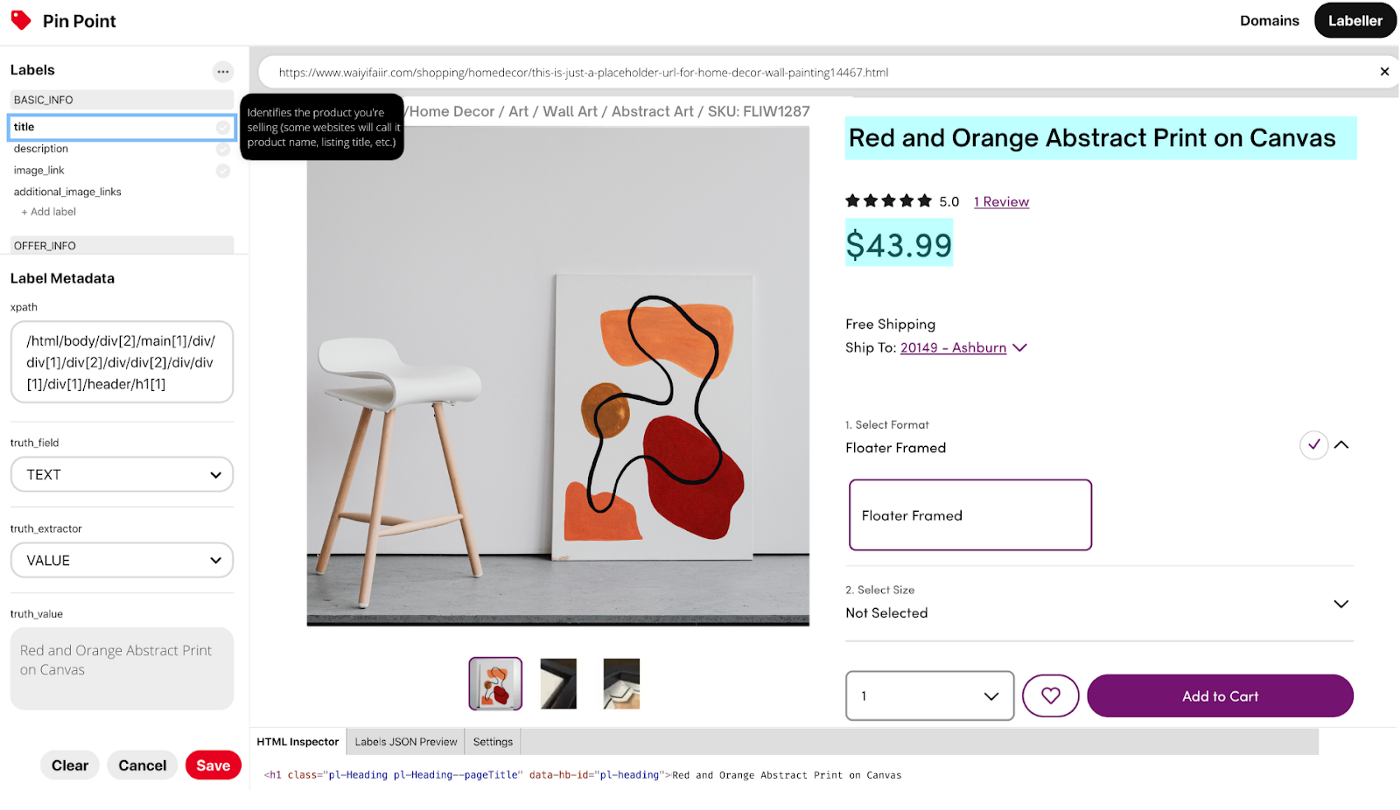
With a good representation, we can simply do a similarity search between a query and a candidate using some ranking function: ? : V × V → R . We refer to it as Local Inference in this way because it only depends on per node representation. Figure 3 presents a tool we developed to get queries efficiently with just a few mouse clicks. We can incorporate their neighbors’ embeddings into ? to better capture the page structure information:
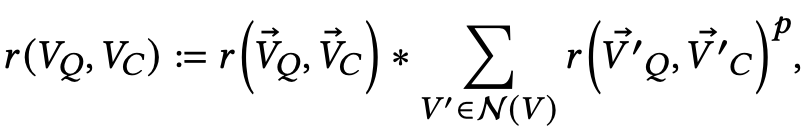
where ? ≥ 1 is a hyper-parameter controlling the importance of context. In practices, we found ? = 1 is usually good enough. The neighborhood of ? is defined by the union of neighbors of ? :
N (? ) := PARENT(? ) ∪ SIBLINGS(? ) ∪ CHILDREN(? ).
Unlike an undirected graph, we know the different roles of neighbors in this context of DOM tree nodes. Therefore, we distinguish the contributions of different types of neighbors when aggregating them. We refer to this approach as Contextual Inference:
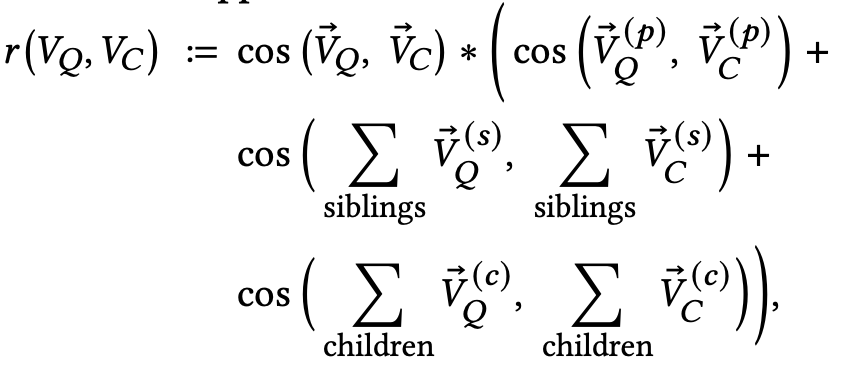
where? (?) ∈PARENT(?) is a parentnode,? (?) ∈SIBLINGS(?) denotes a sibling node, and ? (?) ∈ CHILDREN(? ) denotes a child node. We have filtered out the nodes with negative cosine similarity to _V_Q. We use SUM instead of MEAN pooling following GIN, because it is more powerful to encode graph topology information than GCN. We use the graph information at the inference time instead of learning GNN-based node embedding at the training time. The hypothesis is that the graph topology between the query and candidate nodes of the same domain is stronger than that between pages of different domains.
Experiment
SWDE is the most commonly used public dataset to measure the performance of web attribute extraction algorithms. This dataset contains data for eight verticals, 80 websites, 124K webpages, and 32 attributes. We compare the performance of our model with other state of the art algorithms in Table 1.
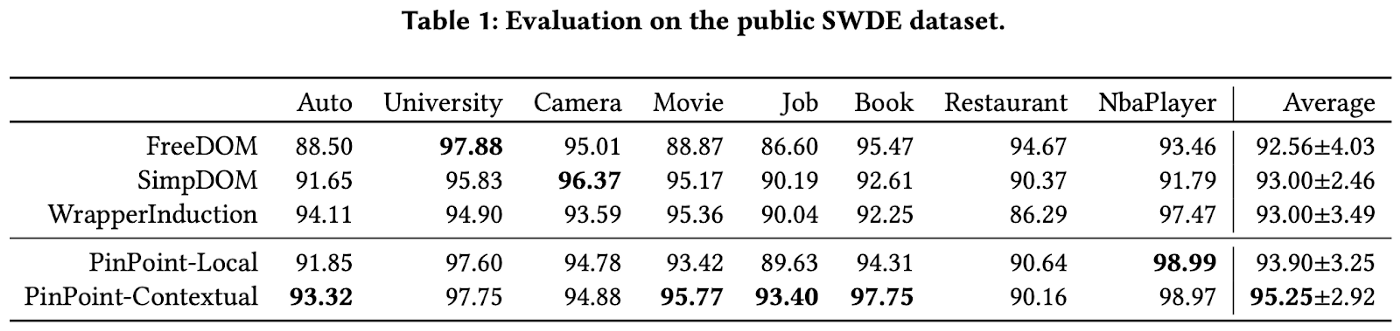
For each page, we count a prediction for an attribute correct if the top one prediction is in the positive labels. There can be more than one positive label per attribute per page. Then we can calculate F1-measure. As we can see, both our PinPoint models beat state-of-the-art DNN models. The Contextual Inference helps precision.

Modern websites have significantly more complex webpages than the ones in SWDE. For example, the raw HTML page size can be 10 times larger. Hence, we curated a large dataset from nine shopping domains with varying numbers of web pages as shown in Table 2. This makes the task more challenging and representative of an industrial application. Although we use this system to extract 16 attributes, we show performance only on the five most important attributes; Title, Description, Price, ImageLink, and ItemId.
We use the first five domains as the pre-training dataset to learn the inductive embeddings. The remaining four domains are used for the in-domain training purpose when we compare in-domain versus cross-domain training data quality, with 1,000 pages left out for the evaluation purpose. We then collect another top eight shopping domains without any labels. We use the top-1 prediction precision as the metric. We train models and evaluate them as follows:
- Training: we pre-train the deep neural representation model with a classification task. We do not conduct any further fine-tuning for pre-trained cross-domain models.
- Inference: we only label one page as the query page and use 1,000 pages as candidate test pages. Because the results can vary depending on the choice query page, we repeat this process 10 times and report the mean and variance.
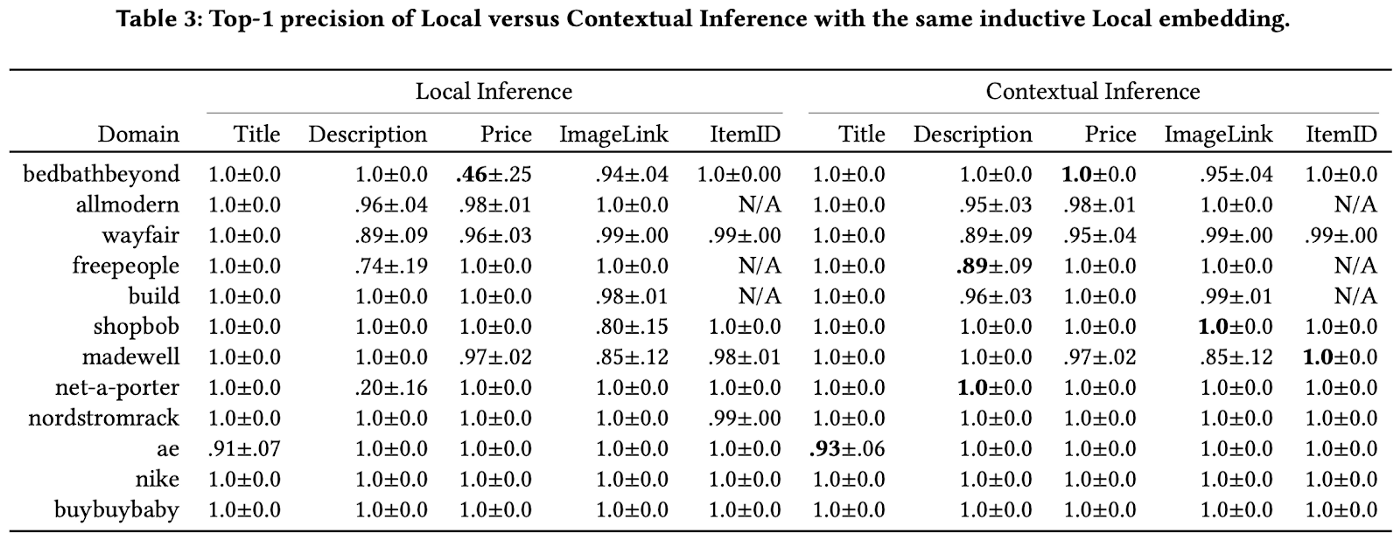
The first and most important observation is that our pre-trained local embedding plus context-aware inference works well even with only one-shot label when presented a new domain. Note that the Local Embedding + Contextual Inference approach does not require any training on new domains. The top-1 attribute extraction precision is mostly in the range [90%, 100%]. In contrast, our human designed template method has an average precision around 95%. That means this PinPoint system achieves near human-level performance, which potentially makes Pinterest the information hub of the huge amount of product detail pages on the web. It provides the attribute database for other shopping content mining projects.
Second, the Contextual Inference is consistently better than local inference across different attributes and different domains. In particular the biggest gain is from the price attribute on bedbathbeyond. It improves the precision from 46% to 100%. When we examine the data, a typical dominate image link is shown below:
Such a link tag can have 50+ link tags with very similar HTML attributes. They do not have any node text. That means the local embedding is not rich enough to distinguish them even after extensively featurizing the node. When we encode neighbors’ information, the borrowed features help differentiate and accurately resolve to the correct node. To conclude, Contextual Inference is required when local node-level information is sparse.
Third, the extraction difficulty level is very different among different attribute types. For example, the title has the same 100% precision with only local inference. But our goal is to generalize PinPoint to hundreds or thousands of shopping domains, and it is important to guarantee the performance of challenging attributes.
Conclusion
Pinterest’s knowledge acquisition system PinPoint learns robust DOM node embeddings inductively. We presented two algorithms and showed that encoding context is required for reliable extraction of attributes. Furthermore, our approach of using context-aware inference extracts information at >95% accuracy from new domains with as few as one-shot label.