Scaling productivity on microservices at Lyft (Part 2): Optimizing for fast local development

This is the second post in the series on how we scaled our development practices at Lyft in the face of an ever-increasing number of developers and services.
This post will focus on how we brought a great development experience right to the laptop to allow for super fast iteration.
The missing inner dev loop
One way to think about the process a developer may follow when making a code change is to break it down into an inner and outer dev loop. The inner dev loop is the quick cycle of iteration of making a code change and testing if it worked. Ideally a developer will execute the inner dev loop many times to get their feature working and most time should be spent editing code followed by quickly running tests in 10s of seconds. The outer dev loop usually involves syncing your code change to a remote git branch, running tests on CI and getting code review before a change is deployed.The outer dev loop usually takes at least 10s of minutes and is ideally completed only a handful of times to address code review comments.
As we mentioned in the previous post, executing the inner dev loop used to require syncing your code changes to a developer’s own environment running on a remote VM called Onebox. These environments were notoriously fickle, with long startup times and needed to be rebuilt frequently. Users were constantly frustrated that their inner dev loop was often impeded by these environment issues. The need for environment spin up and syncing code changes made this process look more like the outer dev loop. Developers would often fall back on the actual outer dev loop and use CI to run tests for each iteration they made.
Running one service at a time
So we set out to make a simple and fast inner dev loop. The core shift that needed to be made was from the fully integrated environment of Onebox (many services), toward an isolated environment where only one service and its tests would run. This new isolated environment would be run on developer laptops. This brought back the inner dev loop shown in the diagram above where users simply edit code and run tests with no additional steps in between. We worked to make the vast majority of tests isolated to an individual service. We also created the ability to start a single service on a laptop and send it test requests.
We decided to run service code natively on MacOS without containers or VMs. From previous experience, we learned that running code inside containers is not a free abstraction. While it makes it easier to setup the execution environment, it resulted in confusion by users and additional challenges debugging when things like container networking or filesystem mounts went wrong. Running natively also allowed much better IDE support compared to running inside containers. We still use containers in certain cases such as running datastores or services that can only run on Linux.
Setting up the laptop environment
The biggest tradeoff of running code natively on MacOS is having to configure and maintain the environment on each developer laptop. To overcome this, we have invested in tooling to make setup easier so that a new developer at Lyft can get up and running very quickly.
Backend services are written in Python and Go (with a few exceptions) and frontend services are written in Node. Each of our services has its own Github repository and its own set of library dependencies.
Python
For Python, we build a virtual environment (a.k.a. venv) for each service. We developed a tool that helps create and manage the venv. The tool distributes specific supported Python versions and does some OS setup such as installing shared libraries via Homebrew and setting up SSL to use the correct certificates. It also enforces using our internal PyPi repository.
When the user runs a command to build the venv it will:
- Look at metadata to select the correct version of Python for this service
- Create a new venv
- Use pip to install the library dependencies in requirements.txt
Once the venv is built it must be activated (added to $PATH). We use aactivator to automatically activate the venv each time a user enters the service directory and deactivates as they leave. The venv that’s created is immutable (pip install is disabled). When a change is made to requirements.txt a fresh venv is built. This ensures the dependencies in the venv precisely match the requirements.txt file and what will be deployed. Previous fully built venvs are cached so if a user reverts the change to requirements.txt it will use the previously built version. There is also support for creating a mutable venv to easily try out new dependencies without triggering a full rebuild. We also support creating a venv for internal Python libraries to easily run its tests locally.
Go
For Go, the setup is pretty simple. A user installs the Go runtime, sets a few environment variables (such as our proxy for downloading dependencies), then can use go run or go test. Thanks to the wonderful Go modules toolchain all the dependencies are downloaded and linked automatically every time you run these commands.
Node
For Node, we use a custom wrapper around nodeenv to download and install the correct node and npm for that service based on its metadata. It prevents users from needing to manually install a version manager like nvm and switches to the correct Node version when running a different service.
With the environments described above, developers can run their service code directly on their laptops for all but a handful of services. Some services rely on libraries that are only supported on Linux. For this very small subset, developers have an easy way to download Docker images built by our CI system, mount the local code directory and run the tests for their service. While it’s a more cumbersome process it still allows for fast iteration.
Running a service
It is important for developers to be able to quickly iterate on a fully running service so we worked to enable this use case on the laptop. We created tooling to orchestrate starting a service, sending test requests, and proxying any requests made by that service. To ensure isolation of data, the datastores used by the service are started locally with fresh data each time. A script is run at startup to create tables and insert any data needed for testing. Teams are responsible for maintaining this test data set to allow proper testing of their features.
Here’s an example of the steps needed to run a service:
- Run environment checks (e.g. correct tools are installed, necessary git repos checked out, ports are free)
- Activate virtual environment (Python and Node services)
- Start datastores (e.g. dynamodb, elasticsearch, postgres)
- Start proxy app (more on this later)
- Run datastore population scripts
- Run the service
Having developers run all of these manually would be very cumbersome and error-prone. We needed a tool that would orchestrate these checks and manage the necessary processes with declarative configuration. For this we decided to use Tilt. While Tilt is often used for testing code in a Kubernetes cluster, we are currently using it for purely local workflow management. Each service has a Tiltfile which specifies the steps that must run before starting the service. It’s written in Starlark which is a dialect of Python used by Bazel which provides lots of flexibility to service owners. We provide common functions (e.g. ensure_venv(), launch_dynamodb()) so service Tiltfiles mostly consist of these predefined function calls .
To start the service a user runs tilt up in the terminal and Tilt will parse the Tiltfile and create an internal execution plan. It will run all the checks and processes in the order specified in the Tiltfile. Tilt hosts a local web app that shows the status of everything that is run. A user can click on tabs in the web app to show the log output from each process. This allows the user to track the status of running processes and debug any errors using the logs.
Once the service is running it will automatically reload as the user edits code in the IDE. This is a big win for shortening the inner loop as a user doesn’t even need to trigger any action to reload the service.
Handling requests to other services
Lyft consists of a large mesh of services so nearly all of our services make calls to at least one other service in the mesh. There are two primary ways to handle these requests made by the local service:
- Return a mocked response
- Forward the request to another environment with live services
We support both of these in a very flexible way using an internal tool we developed.
A proxy app was originally developed at Lyft several years ago as a tool to help mobile app developers decouple their development workflow from backend service teams. It’s an Electron app that acts as a proxy between calls made by a mobile app to the staging API. Developers would connect their mobile app to the proxy server at a unique URL for each user. By default, the proxy would forward all requests to the staging environment. Users can choose specific calls to override and return fully mocked data or mutate individual fields in the response from staging. This allows mobile devs to test their app changes while the backend APIs are still under development. The setup looked like this:
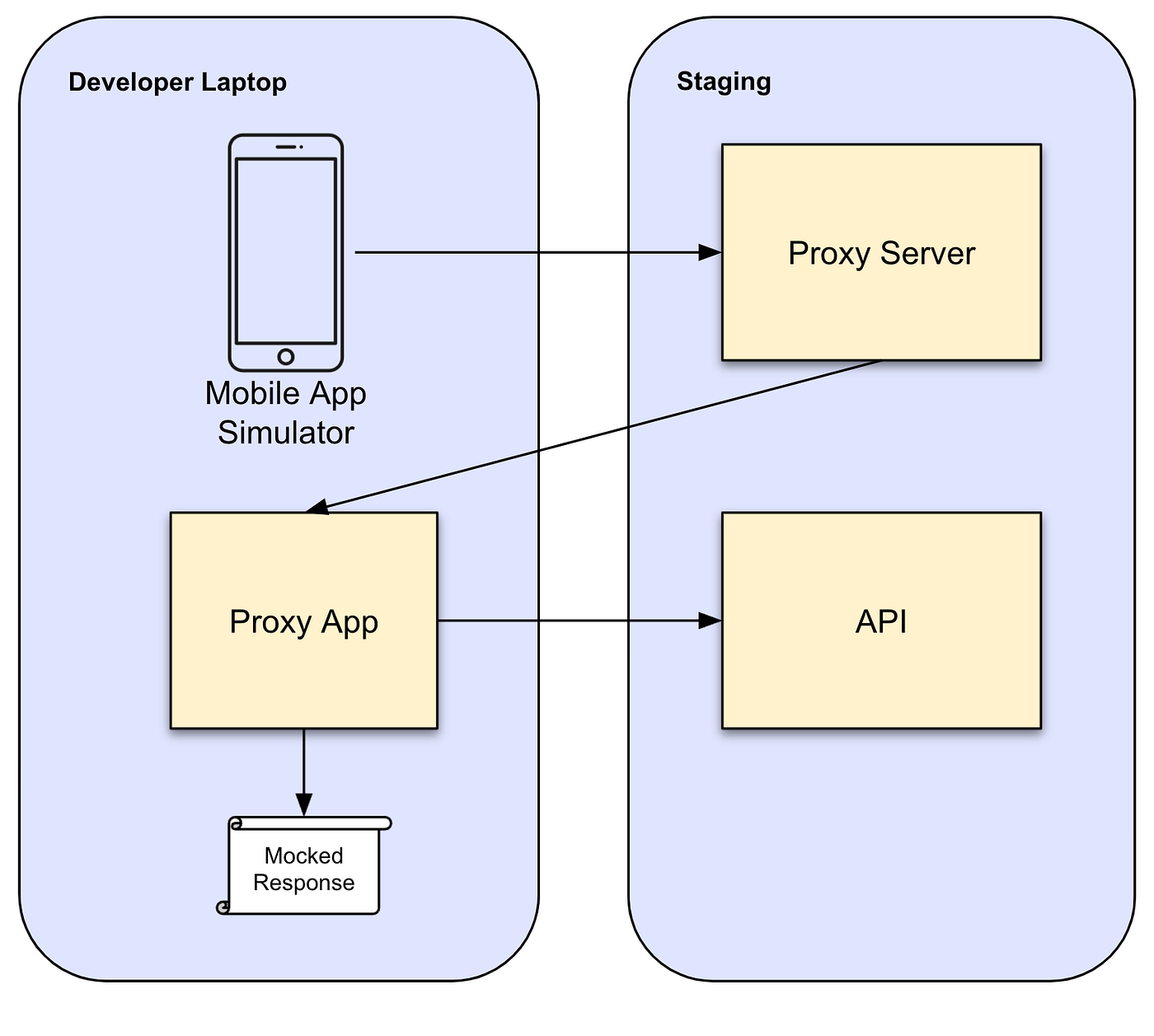
The big advantage this proxy app brought (compared to other tools like charlesproxy) is deep integration with Lyft’s interface definition language (IDL) which is implemented with protocol buffers. In IDL, we specify request and response structure for endpoints on backend services. In the proxy app we give the user a Typescript code editor (using the Monaco Editor from VSCode) to compose the responses. The integration with IDL allows the user to have an IDE-like experience with type checking and auto complete the structure of the mocked data responses. The code interface also allows complex interactions such as setting fields from a request into the response. It also shows human-readable request and response bodies of all requests flowing through the proxy giving users excellent visibility of all requests from the mobile app.
When we began developing the tooling to run a backend service locally, the proxy app was a perfect fit to handle requests the local service made to other services. We reused the proxy functionality to either forward a request to staging or return mocked data based on the user’s intent. The setup looks like this
Making requests to the local service
Next we needed a tool to let users compose and send requests directly to the locally running service. This was not a common practice in the days of Devbox/Onebox, with most test requests coming from mobile clients, so we had to come up with a new solution. There is no shortage of tools for constructing API requests such as curl or Postman. But we currently have several RPC transport formats we need to support at Lyft including GRPC, JSON over HTTP, and protobuf over HTTP. No existing tool could seamlessly handle these different formats and leverage our definitions and easily compose requests.
The proxy app turned out to be the best choice for us. We added the ability for a user to compose a request using the Typescript code editor and press a button to fire the request to the local service. This once again uses the integration with IDL to provide autocomplete on the URL path and fields of the request body.
Results
Since we rolled out this tooling to the entire company earlier this year, feedback has been incredibly positive. Developers love the ability to run tests on their laptops and in their IDE without needing any remote environment. Creating a new Onebox environment often took about an hour but now the laptop environment is always ready to run tests. Starting a service locally using Tilt takes just a few minutes.
We also observed a behavioral shift among developers as they were spending more time focusing on testing just their service. When running a service locally, users send requests directly to their service’s API instead of testing using the mobile app talking to public APIs. This increases the developer’s familiarity with their service’s API and reduces the scope of debugging when there’s an error.
While cost was not the primary driver of this project, we did end up saving noticeable amount of money by not paying for the beefy AWS instances for Onebox for each developer. Having users run services in isolation on their laptop instead meant a real reduction in total compute resources needed.
Future work
What’s described above has been the first iteration of tooling. We have many exciting ideas of where to take things next. Here are just a few of them:
Apple silicon support
We’re excited to begin shipping the new Macbook Pros with M1 chips to developers soon. Early benchmarks show these machines as providing a huge speed improvement out of the box, even under emulation! Additional work to ensure we’re running everything natively will help us realize further improvements.
Route requests from a service on staging to local service
Currently, a user must make a call directly to their locally running service. There’s no way for a user to make a request to the client API, have it travel through some services on staging before being routed to the local service. We plan to enable this feature soon. This will allow users to test full end to end user flows (such as running a mobile app) to test a new feature of a backend service while still having the fast inner dev loop of local development.
Improved UI for sending requests
The code interface in the proxy app for composing requests is very flexible and powerful but it can be challenging for novice users to construct a request correctly. We would like to create a more tailor-made UI for this use case more like Postman while maintain the power of the code interface. We also plan to create an API playground where users can easily discover and play around with endpoints in staging for any service at Lyft.
Remote dev environment
There have been some exciting developments in fully remote dev environments such as Github Codespaces. We are definitely keeping an eye on these solutions as they mature to see how well they fit our use cases.
Stay tuned for the next post in our series that will show how we safely deploy code still in PR to the staging environment and test it.
If you’re interested in working on developer productivity problems like these then take a look at our careers page.
Special thanks to the team who helped build all this tooling and contributed to this post: PG, Michael, Max, Garrett, and Jake