图解ChunkSplitPlugin
该文章阅读需要 7 分钟,更多文章请点击本人博客halu886
@兔几直播是一款主打交友的秀场直播平台,前端部门累计 8 人+,主要负责 PC 主站/H5 的视图层及 Node(BFF)层,以及 6 个+内部数据可视化系统。
在一个长期快速迭代且多人协作的中大型项目中,前端部署自动化一直都是团队的痛点,以下则是我们团队在基于多样的场景自研的 web-ci 完整版心路历程,实现前端部署一键化/可视化,同时将耗时从 30min+缩短为 3s 左右。
背景
我们项目架构是采用前后端分离,BFF 基于 EGG 搭建,前端页面集成 MVVM 框架 Backbone.js/Vue.js,工程化打包工具则采用 fis。
我们将各个前端业务拆分成一个个完全隔离的 repo(累计 10 个+),在项目 run 起来之前,
需要将涉及到的 repo 基于我们自定义的 fis 配置规则
通过 fis 将源码打包成标准的 EGG 结构的项目(pc-master),然后启动 pc-master
所以无论是线上还是本地都是通过 pc-master 实现服务
基于 CDN 加速
最开始我们部署流程是通过 web-ci 服务处理如下几步,并且线上搭建四个源站且集成 aliyun CDN 加速和缓存服务进行支撑业务
- 开发者向部署分支(master/test)合并提交且推送至远程仓库
- 触发 gitlab 配置的 web hook,通知 web-ci 新建任务执行构建任务
- web-ci 服务执行相关命令
- 将所有 repo 打包进 pc-master 中
- 上传 pc-master 相关源码及资源至源站
- 启动服务
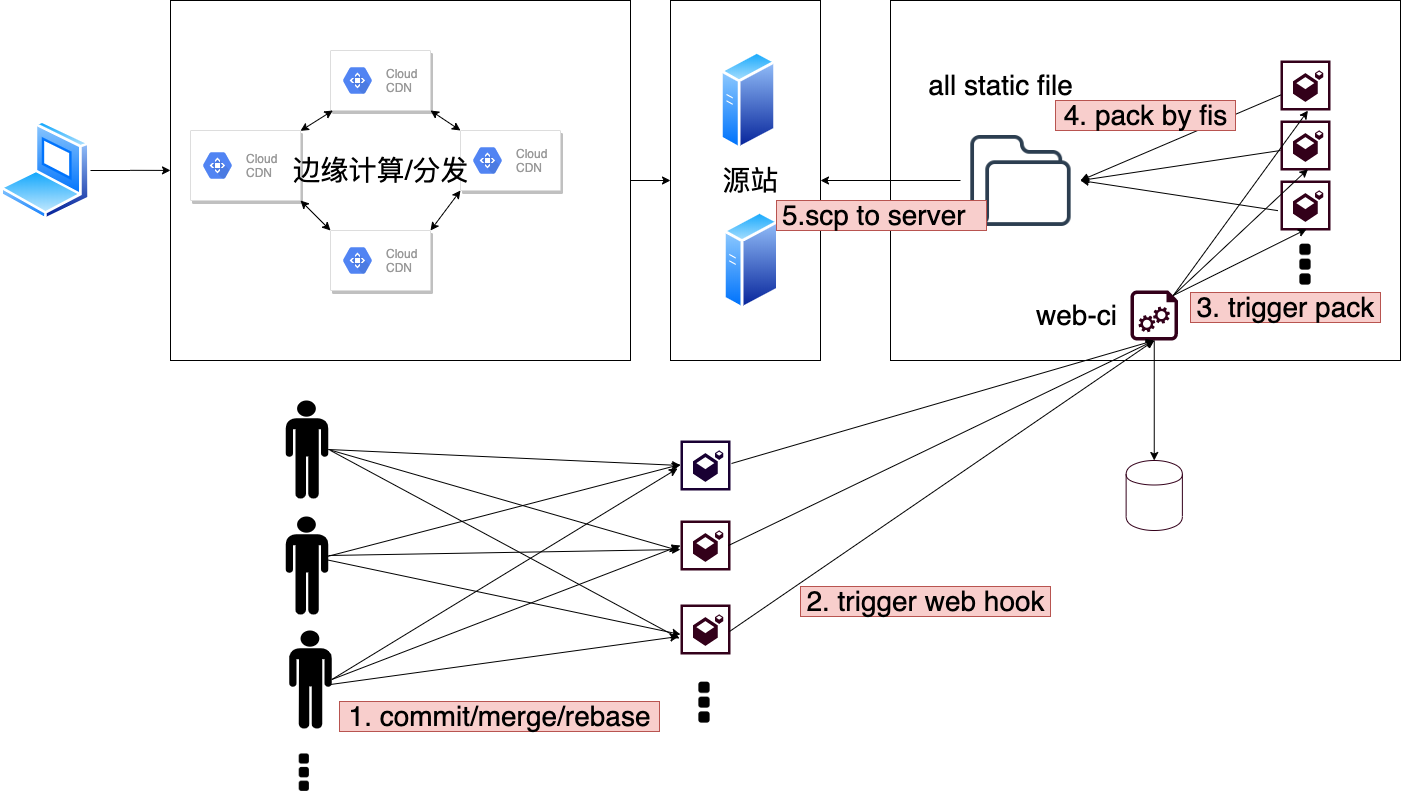
由于 cdn 的缓存策略,在我们采用的是增量发布,结果随着项目推进却带来了一系列的弊端。
场景 1:
线上活动 A-index.html,依赖 a-123.js/b-123.css(资源文件通过打包注入的 HASH 值进行区分其版本)
开发人员发现由于线上流量过大,对相关服务端接口做了节流处理,更新源码后合并到发布分支且推送到远程仓库。
此时 web-ci 重新打包,重新生成相关依赖静态资源 a-456.js,由于是增量发布,那么此时该活动的静态资源目录则变成 a-123.js,a-456.js,b-123.css blabla。
将相关打包后的文件上传至源站的体积就变大了。
随着项目快速迭代,打包后的 pc-master 逐渐变得越来越庞大,由几十 KB 涨到以 GB 为单位,即时是在局域网传输也需要耗费二三十分钟左右,那么这对于开发人员肯定是极度不友好的。
为什么需要做增量发布?为什么不能删除旧的资源文件?
cdn 网络具有缓存且缓存具有时效性,当用户通过地址访问 html 文件时,
一旦命中 CDN 的缓存,html 依赖的还是旧的静态资源,那么此时则请求 a-123.js 文件。假如该文件在 CDN 网络的缓存已经过了时效性或者没有命中缓存,经过 CDN 回源策略最后请求回到源站,
一旦发现文件不存在,那么对于用户来说,该网站则是不可用或者异常的。
对于商用的产品这个问题肯定是不能接受的。
集成 OSS
基于上述痛点我们决定通过集成 OSS 对象存储服务,并且在构建过程中引入一个中间目录进行过渡且增加灵活性。
- 开发者向部署分支(master/test)合并提交且推送至远程仓库
- 触发 gitlab 配置的 web hook,通知 web-ci 启动构建服务
- web-ci 服务执行相关命令
- 将所有 repo 打包进 main-pc 中
- 执行脚本将相关静态资源文件上传逻辑至 aliyun OSS 服务中
- 将 BFF 层 script 及相关 html 资源文件 cp 到 main-pc-release 中
- 触发 walle 将 main-pc-release 同步到源站重启服务
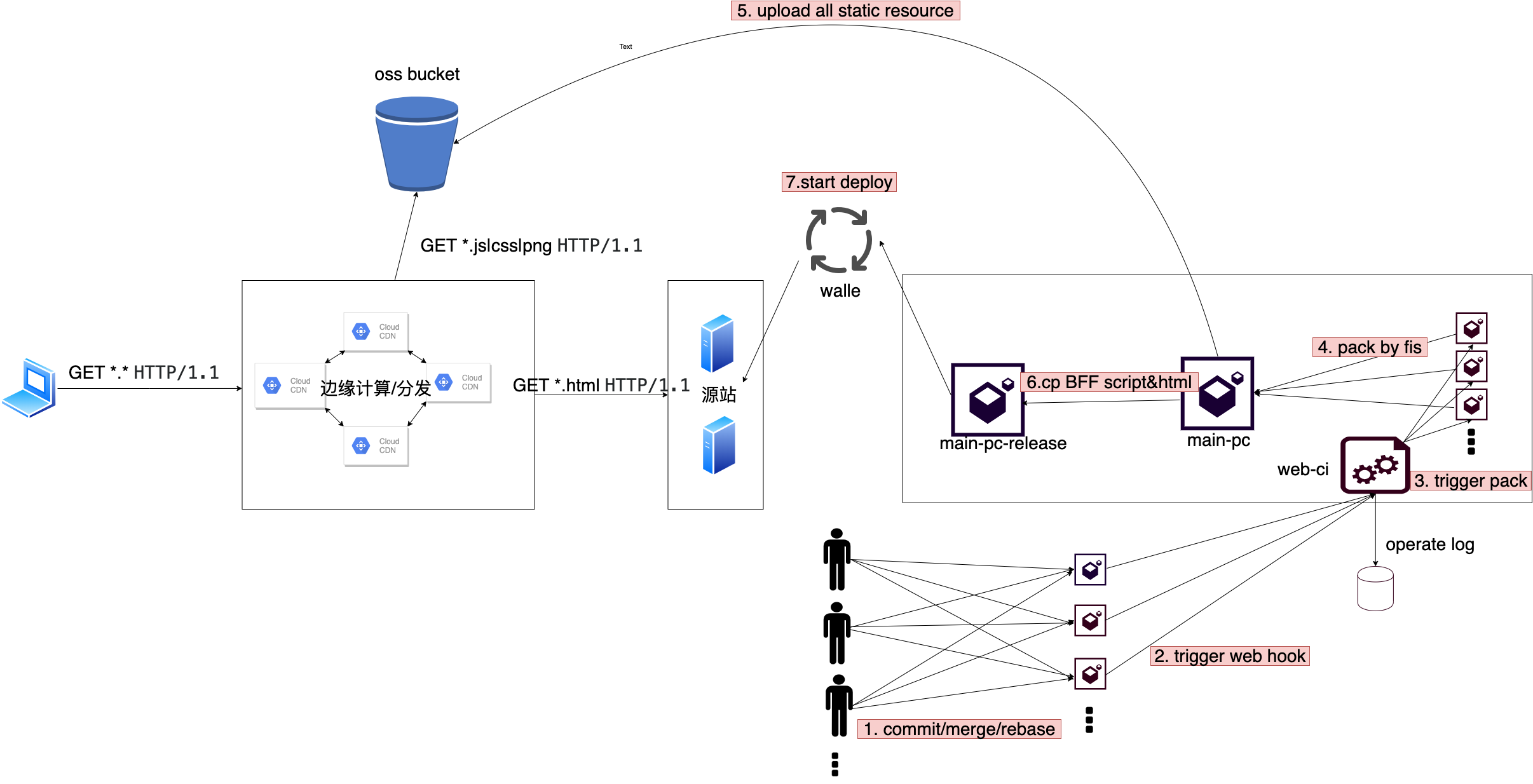
仔细观察流程则可以发现多了第 6 步 upload all the static resource。
这个思路的本质则是将我们的增量发布从源站转换到 OSS bucket 中,
在 OSS bucket 稳定的前提下,我们只需对每次新生成的个别文件进行上传操作,并且每个有文件都存在唯一的哈希值保证唯一。
完美的在 web-ci 服务中规避了由于增量发布带来的维护旧文件所带来的成本。
并且最后源站执行的是 main-pc-release 项目,此时项目已经剔除所有非必要的静态资源的文件,
源码本身只存在 BFF 层相关的业务代码和 html 文件。则在第七步中传输到源站耗费的时间完全可以忽略不记
这时从开发者提交代码,到代码构建完成全流程只需要秒级别,大幅度的提升了开发人员的效率
可视化
为了提升构建服务本身的也易用性,同时搭建可视化看板实时读取日志,且加入了回滚及及销毁等个性化操作。
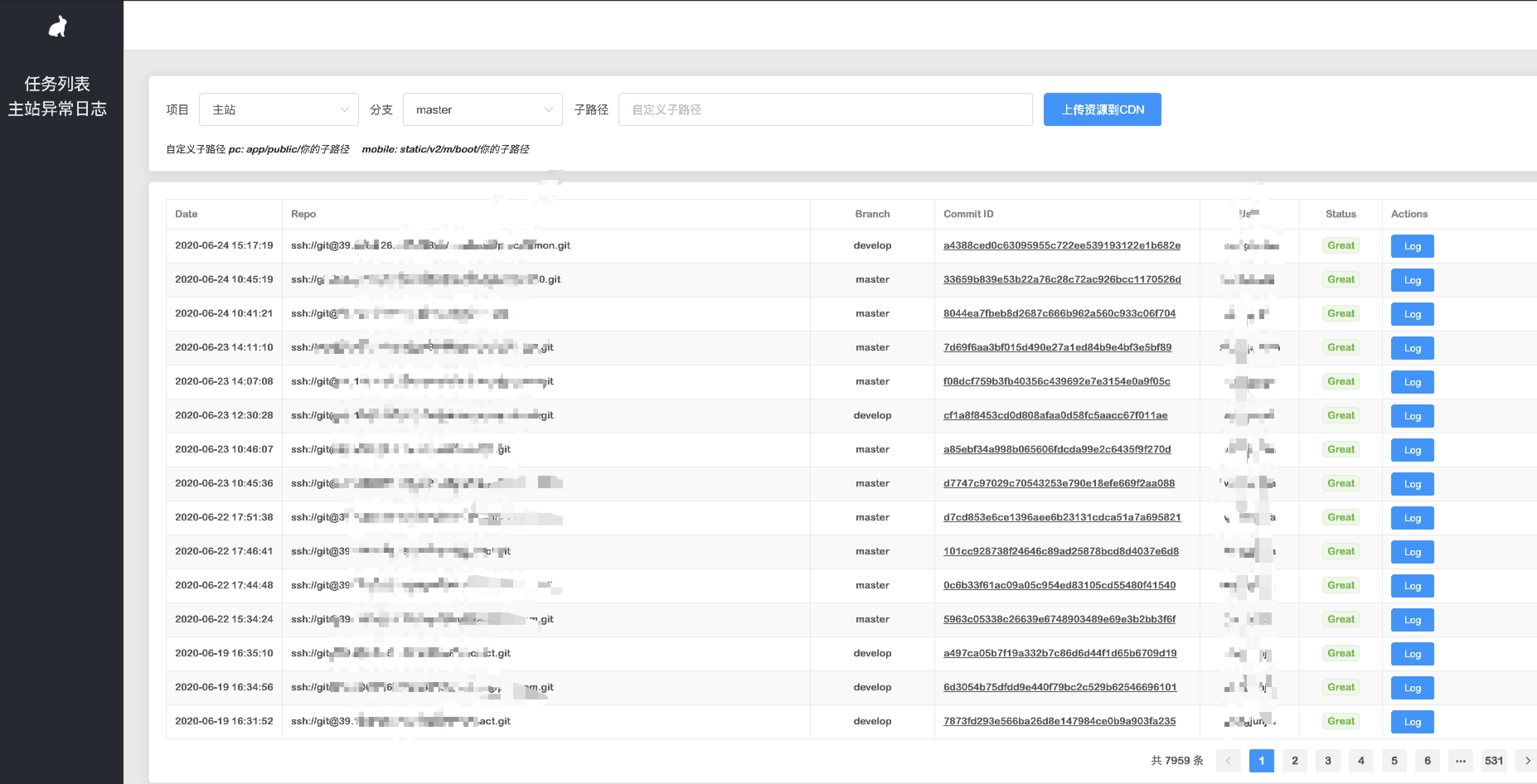
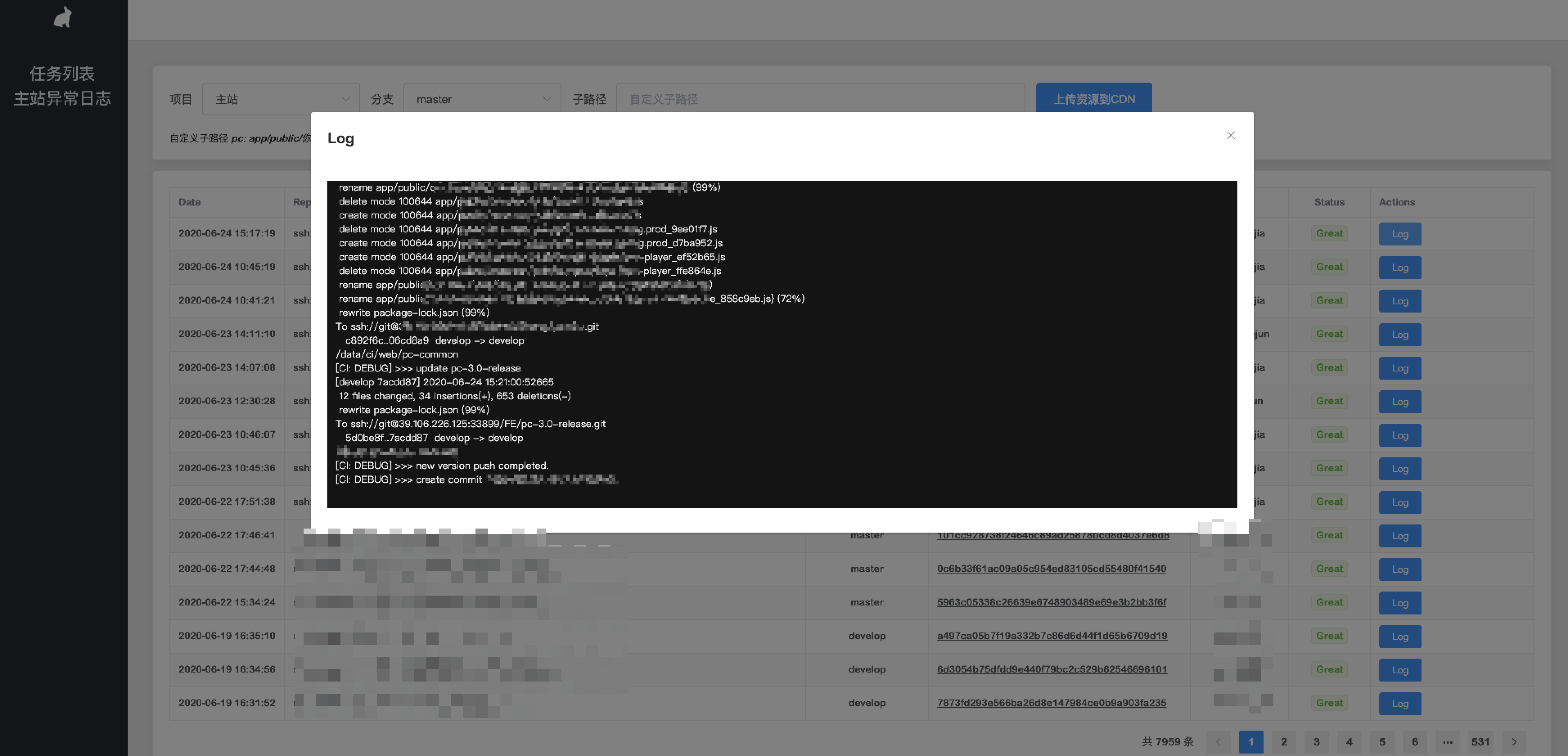
例如:web-ci 内置启动一个 web 服务,对每步流程都进行进行日志写入,当前如果有任务执行,且日志正在写入中,看板则会发起一个 http 请求,web-ci 则将 log 文件可读流转发至 response 响应流中,实现同步显示 log
总结
优雅的构建流程是前端工程化中不可或缺的一部分,如何实现易用且高效的方案每个团队的侧重点都有所取舍。
不论是基于第三方构建平台或是选择自研搭建,核心都诉求都是尽可能都节省时间及人力。
以上就是我们团队相关历程的总结,欢迎拍砖及讨论:halu.hong1996@gmail.com

该文章阅读需要 7 分钟,更多文章请点击本人博客halu886
chunk(module 的集合)在 webpack 解析的依赖图中以父子关系联系起来的。最初CommonsChunkPlugin被设计用于 chunk 之间避免重复依赖,但是性能远远不是最优解。
在 webpack 4 中,内置了ChunkSplitPlugin用于替代CommonsChunkPlugin。
以下基于官方 demo进行梳理,将主要的数据结构结合图示和个人的理解进行总结。
揭开此插件的设计思路和源码神秘面纱
思路
在梳理之前建议先了解一下 webpack 内部基于 tap 事件流架构。
以及 Chunk(module 的集合,也是 webpack 的打包单元,最后输出的文件就是 chunk) 和 Module(依赖树中的解析单元,可简单理解成每一个依赖的 js 文件) 的数据结构
观察 demo 中文件结构,可以简单得出以下结论
- 共有 7 个入口文件 a ~ f.js,也就是最少七个 chunk(分别通过索引 1 ~ 7 来表示)
- 共有 14 个 js 文件,则共有 14 个 module
- stuff/*下的 s1.js
s8.js 和 node_modules/m1m7.js 之间是没有相互依赖的
插件被注入在 compiler 的thisCompilation的 tap 事件以及 compilation 的optimizeModules的 tap 事件下
thisCompilation:Executed while initializing the compilation, right before emitting the compilation event.
optimizeModules:Called at the beginning of the module optimization phase. A plugin can tap into this hook to perform optimizations on modules.
为了方便后续调试和梳理,特意将 demo 的 14 个文件之间的依赖关系整理出来

分别将 7 个入口文件 entryPoint 按颜色区分开来,箭头指向为依赖关系,橘黄色的区域为经过
ChunkSplitPlugin生成的newChunk
以及将执行前的所有 Chunk 快照

./webpack.config.js
1 | |
前置逻辑
在插件分析整个依赖图整理 module 之间的重复依赖之前,进行了大量的额外的优化,通过空间换时间,将大部分数据状态缓存起来,
以下就通过代码顺序和逻辑一步步进行剖析。
chunkSetsInGraph
通过遍历 14 个 module,分析 module.chunksIterable 被依赖的 Chunk,通过 Chunk 的索引整合成 key 值指向 Chunk 的集合,类型为Map<string, Set<Chunk>>

例如:遍历到 m1 时,该模块被 Chunk1 和 Chunk2 以及 Chunk3 引用,则如图所示 "1,2,4"->set<Chunk>{Chunk1,Chunk2,Chunk3}。
当遍历到 m2 时,发现改模块也被 Chunk1 和 Chunk2 以及 Chunk3 引用,”1,2,3”已经被缓存,则跳过继续遍历
chunkSetsByCount
对chunkSetsInGraph进行遍历,将chunkSet通过 length 聚合。类型为Map<number, Array<Set<Chunk>>>

例如:遍历 ChunkSetsInGrouph时"1,3"指向的 Set<Chunk>{Chunk1,Chunk3}长度为 2。则chunkSetsInGraph中推入 key 值为 2 指向[{Chunk1,Chunk3}]数组。
当遍历"2,5"时指向Set<Chunk>{Chunk2,Chunk5}时长度为 2,则 key 值为 2 数组推入Set<Chunk>{Chunk2,Chunk5},此时 key 值 2 指向的数组为[{Chunk1,Chunk3},{Chunk2,Chunk5}];
combinationsCache
对所有的 ChunkSet 进行遍历,将 ChunkSet 及它的子 Set 进行聚合,通过聚合中的 ChunkSet 最大 key 进行引用。类型为Map<string, Set<Chunk>[]>

例如:遍历 chunkSetInGraph,当 key 值为1,2,3时,指向[{chunk1,chunk2,chunk3}],同时后续遍历中将所有 subSet 推入,最后"1,2,3"指向[{chunk1,chunk2,chunk3},{Chunk1,Chunk3},{Chunk1},{Chunk2},{Chunk3}]
selectedChunksCacheByChunksSet
所有的 chunkSet 对应的不同的配置过滤后的结果,基于 webpack.config.js。类型WeakMap<Set<Chunk>, WeakMap<ChunkFilterFunction, SelectedChunksResult>>
在我们的 demo 中chunks: "all"的配置,所有的filterFunction都是const ALL_CHUNK_FILTER = chunk => true;,所以SelectChunkResult都是 chunkSet 本身

核心
基于以上的生成的缓存数据,接下来就是开始生成最重要的数据结构chunksInfoMap,同时遍历这个对象剥离出新的 Chunk 并且在 ChunkGroup 中建立联系。类型Map<string, ChunksInfoItem>,ChunksInfoItem 类型为{modules,cacheGroup,name,chunks,chunksKeys,blabla...}
对 modules,combinationCache,以及 cacheGroups 进行三层嵌套循环找出每个被依赖的 module 的重复 chunk 关系(可以尝试对照第一张图逆向推导)
cacheGroups 是中间数据, 遍历每个 module 时生成的配置项,主要用于区分 module 的类型用于过滤
例如:在chunk:all的配置下,module 默认存在配置{key:normal,minChunk: 2},但是node_modules/*下的 m1 ~ m7 除了默认配置额外{key:vendor,minChunk: 1}
例如:遍历到 m1 时,存在两个 cacheGroup 配置项[{key:normal},{key:vendors}],且在 combinationCache 被{chunk1,chunk2,chunk3} 及子集[{chunk1,chunk3},{chunk1},{chunk2},{chunk3}]依赖。所以基于 key 值分别推入 7 条数据(另外 3 条由于 vendor 的 minChuck 为 2 被过滤)

最后对chunksInfoMap循环检索
在每次循环检索,推出优先级最高的ChunksInfoItem(通过 name/path/chunks.lengthd 长度等等)。
通过校验后,使用compilation.addChunk生成一个 newChunk,并且GraphHelpers.connectChunkAndModule将 newChunk 注入 Graph 中,并且通过chunk.removeModule移走旧 chunk 中 newChunk 中的 module。
直至 chunksInfoMap 为空
注意:进入下一次循环前,会将剩余的 ChunksInfoItem 的 module 进行清理,已被封装进入 newChunk 的 module 移除,如果 ChunksInfoItem 的 module 为 0,则这个 chunkInfoItem 被 delete
总结
webpack 极大的解放了前端工程化的劳动力,一个插件中的逻辑都能给予我们大量的启发,并且对于阅读知名的开源项目,源码结构也确实十分严谨和美观,收获颇丰。
由于 demo 比较基础,插件中很多边界情况并没有涉及到,但是主流程梳理的比较完善。
研习大佬的代码,就像阅读一本著作,虽然很痛苦但是却很享受~
该文章阅读需要 7 分钟,更多文章请点击本人博客halu886
在续上篇 ssr 骨架搭建之后,服务端渲染生成的 HTML 代码直接渲染在浏览器客户端上,可以大大减少 TTC(time-to-content)。
但是在现在前端 MVVM 的框架中,例如 VUE,React,都是在单页面中采用动态虚拟 DOM 的思路进行实现页面的交互和组件的更新。
如果采用服务端渲染的话,节点都是直接基于 HTML 中的代码片段直接生成的。 MVVM 中的 V(视图模型)这一步直接都省略了,以及相关绑定器也没有实例化不会被绑定。
那么对于现代的前端的框架的支持太不友好了。
所以降级渲染这个概念也就诞生了,所谓的降级渲染通俗理解则是一套代码基于 SSR 渲染后,在客户端后降级为 CSR(客户端渲染)
这样就能同时享受到两个渲染方式带来到便利和优势。
思路
我们先将代码的路由和数据状态分别托管到 Router 和 Store 组件中,将项目逻辑细化提升可维护性和减少代码量,
并且基于 Router 对事件触发数据的更新。同时只用 Store 对接存在差异的 Api 层,让组件对数据的处理无感知。
1 | |
抽象逻辑层
为了减少对于相关服务端或者客户端对于数据拉取的重复代码,我们在每个 Vue 组件中封装通用的方法asyncData进行数据处理。
1 | |
在 router 匹配时触发该方法进行数据获取挂载在 Store 上,然后在服务端和客户端路由变化时触发。
1 | |
我们将所有数据逻辑统一管理在 Store 中,其中也负责统一对 Api 进行调用
由于在服务端渲染相关数据处理封装在 Service 层,客户端相关数据获取通过 HTTP 请求获取,所以这里分别封装service-api和client-api开放标准接口,在 webpack 打包中使用alias特性将对于 API 逻辑打包进对应文件中。
1 | |
客户端激活
使用 Webpack 将源码打包后,在生成 HTML 片段时,以参数传入后,将会以预加载。
同时在 Router 的onReady事件后,使用实例化后对 Vue 对象进行\$mount 挂载。
在服务端渲染出的 DOM 根节点上,自动添加了**data-server-rendered=”true”**属性,与此同时在客户端激活时,Vue 会识别该属性,进行自上而下顺序的匹配 Visual Dom Tree,当无法匹配时,退出混合模式,重新渲染,并且抛出 warm。生产环境跳过检查,直接渲染
服务端渲染时,会将 Store 属性挂载上 Windows 的__INITIAL_STATE__
1 | |
踩坑
在 Egg 中当进行 SSR 渲染时,相关业务数据的 fetch 为了兼容同构,另外封装在 Server-api 层,在 Vue 根据路由生成 HTML 时进行调用。
但是相关业务层又封装在 service 层,在请求访问时,挂载在当前请求的上下文中,造成了页面生成与请求上下文强耦合。
1 | |
总结
基于 Egg 进行 Vue SSR 的降级渲染主要就是以上的思路,这样既保留了 SSR 的优势,同时也能兼顾单页面下 MVVM 框架所带来的优势,同时在业务开发的过程对开发人员也可以是无感知。
拉取数据主要通过 Router 的 onReady 事件触发,每个的组件的数据相关的操作都封装在asyncData 方法中。API 层通过 Webpack 的alias属性区分打包。
在 Egg 中将请求上下文传入打包文件中调用 ctx.Service 方法。
服务端会将 Store 中的状态挂载到客户端 Window 对象上的__INITIAL_STATE__上,可以通过store.replaceState植入客户端中的 Store 中从而减少消耗。
该文章阅读需要7分钟,更多文章请点击本人博客halu886
目前所在团队主要负责秀场项目,中间层是基于Nodejs并且集成了Egg企业级框架,主要处理路由分发以及一级缓存,同时还负责了首页的渲染以及前端代码的脚手架。
但是由于遗留代码过于老旧,且集成了比较多和杂的框架,不论是编译以及打包和维护都需要耗费大量的精力和时间。
基于以上痛点,我们决定尝试研习出一套更加客制化以及功能完善的项目架构.
对于To C端的产品还是非常依赖SEO(Search Engine Optimization)带来的流量,并且基于服务端渲染的页面的TTC(time-to-content)也是非常有吸引力的。
技术选型则是企业级框架Egg,对于前端MVVM框架则选择国内比较热门VUE,配上Webpack打包工具。
最基本的需求主要有以下几点
- Vue组件服务端渲染
- 模版缓存
- 依赖解析
- 多入口打包
- 支持同构
项目初始化 Pc-4.0-demo
我们将业务代码以Egg标准骨架进行承载。然后将我们的VUE渲染引擎和Webpack打包工具分别封装成Egg-Plugin进行解耦。
标准的目录结构如下
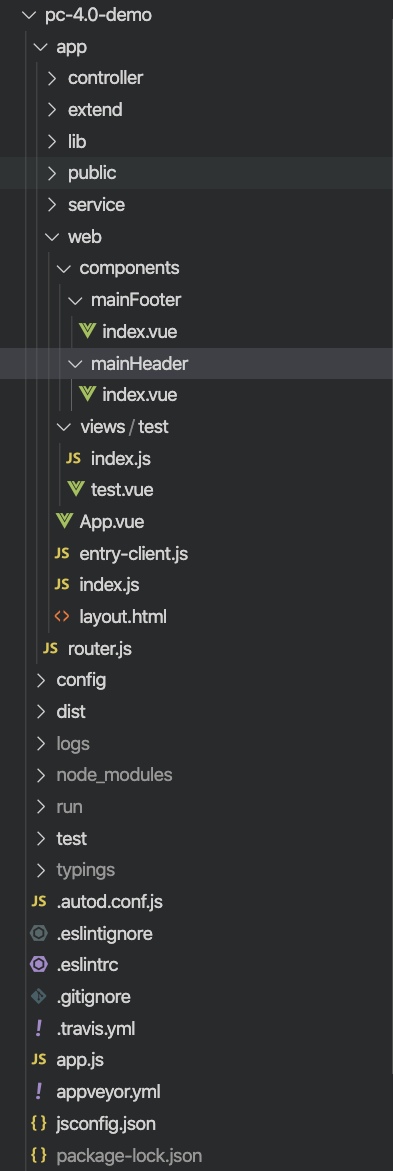
具体的目录分类可以参考Egg doc
Vue模版引擎 egg-view-vue-tuji
首先实现view-plugin下标准对外开放接口lib/view.js的render和renderString。
这里主要是集成Vue官方推荐的vue-server-renderer的渲染工具。
通过createBundleRenderer实例化BunlderRenderer。
将接收到第一次请求时,获取egg-webpack-tuji编译打包生成的JSON格式bundler传入BunlderRenderer中进行模版加载。
最后在标准开放接口中获取cxt挂载的相关参数,将参数注入加载好的模版,然后在回调中获得渲染后好的HTML字符串。
将回调转换成promise后render接口功能就算实现了。
1 | |
Webpack打包插件 egg-webpack-tuji
webpack的默认配置我们维护在插件下标准的config/config.defualt.js目录下,业务上需要客制化的配置则可以挂载在config.webpack进行webpack-merge进行merge。
对于服务端Vue组件渲染,我们需要默认集成Vue-loader,babel-loader,以及less-loader等官方推荐的loader工具链。
由于不支持多入口打包,在这里我们放弃了Vue SSR官网上推荐的vue-server-renderer/server-plugin,
This is the plugin that turns the entire output of the server build into a single JSON file. The default file name will be
vue-ssr-server-bundle.json
而选择通过更加灵活的手动加载多入口下打包生成的Bundler Object。
我们在该插件下的app/lib/tujiWebpack.js封装了大部分Webpack相关操作。
初始化时将相关参数挂载在该实例上,通过build()进行构造编译器compile。
通过哨兵变量isBuilde监听构建状态。
通过getBundle接口将生成的Bundler暴露给Egg-view-vue-tuji。
1 | |
模版缓存
当每次请求访问时,每次都要重复生成一个新的模版这是非常浪费CPU和影响性能。
所以我们尝试利用NodeJS的文件依赖的缓存机制将模版缓存在内存中,以便于重复利用。
同时集成LRU双向链表的缓存策略进行优化。
1 | |
考虑到NodeJS在单节点下的1.7G的内存限制,将模版节点限制20个。
小结
以上便是基础版的服务端渲染的Demo,但是应用到生产以及推广到项目中还需要进行非常多的加工,后续进展也会陆陆续续整理出来,欢迎持续关注~
该文章阅读需要7分钟,更多文章请点击本人博客halu886
80%终端用户的响应时间被花费在前端,大部分时间被当前页面的依赖资源下载占用:图片,样式表,脚本,动画,等等。减少依赖资源的数量从而减少渲染页面所需要HTTP的请求。这是更快的页面的关键。
减少页面的依赖资源的一个方法就是简化页面的设计。但是是否存在方法即使构建更加丰富内容的页面也能实现快速的响应时间呢?以下存在一些技术减少HTTP请求的数量,并且仍然支持丰富的页面设计。拼接文件的挑战在于脚本与样式表在页面之间变化,但是将其作为发布过程中的一部分可以提升响应速度。
CSS Sprites 是一个不错的选择对于减少图片请求,将背景图片整合成一张图片,然后用CSS background-image和background-position属性展示预期的图片内容。
Image Maps 拼接多个图片进一个单个图片。前后的大小大约相等,但是减少了http请求的数量从而提升了页面的响应速度。Image Maps只有图片在一个页面中连续时才生效,例如导航栏。定义Image Maps的坐标非常繁琐和易错的,对于导航栏使用Image Maps也是不可取的,所有这个方案不被建议。
Inline images在页面中使用data:URL shema包裹图片的数据。这会增加HTML文档的大小。将Inline Image与缓存的样式表将会减少HTTP 请求并且组织增加页面的大小,但是Inline Images不被所有主流的浏览器支持。
减少HTTP请求访问是当前页面开始的第一步。这里存在大部分对于第一次访问用户提升性能的准则。正如在Tenni Theurer`s blog文章Browser Cache Usage - Exposed!40%-60%的第一次访问者处于一个空的缓存,对于第一次的访问你的页面更快是提升用户体验的关键。
.2. 减少DNS查找
DNS将主机名映射为IP地址,就像是电话本将人名映射为电话号码。当你输入www.yahoo.com进你的浏览器中,浏览器立马访问DNS服务器返回服务器地址。DNS存在损耗,通常需要损耗20-120毫秒从根据一个主机名到一个IP地址。浏览器不能下载任何资源从主机名,直到DNS查找完成。
DNS从缓存中查找性能更好,它能被缓存在特定的缓存服务器,被用户的宽带提供商或者局域网维护,并且个人电脑上也存在。这个DNS信息被维护在操作系统的DNS缓存(微软则是DNS Client service)。大部分浏览器也存在他们自己的缓存,区别于系统缓存。一旦浏览器在缓存中记录了DNS,它将不会请求操作系统获取记录。
IE默认缓存DNS结果默认三十分钟,可以根据DnsCacheTimeout配置修改。火狐缓存DNS结果为一分钟,network.dnsCacheExpiration配置这个属性。
当客户端当DNS(浏览器和操作系统)缓存为空时,DNS的结果数量等同于当前页面所有不同的主机名的数量。包括当前页面的URL,图片,脚本和样式表和动画等等被使用的主机名。减少不同的主机名的数量就是减少DNS查找的数量。
减少主机名的数量会潜在的减少当前页面并行下载的数量。减少DNS查找缩短响应时间,但是减少并行下载数量可能增加响应时间。我的参考是拆分这些资源通过至少两个但是不超过4个主机名,对于减少DNS查找和并行下载的高度使用的之间一个折中方案。
.3. 阻止重定向
重定向通过301和302状态码完成,下面这个就是301响应体HTTP头部
1 | |
浏览器自动带用户到Location字端指定到URL。在头部中到所有信息都是回调所必须到,通常来说响应体为空。不管它们的名称是什么,实践中都不会缓存301和302响应除非新增Expired或者Cache-control表明它应该被缓存。通过刷新按钮和Javascript能够导致用户到不同的地址,但是如果一定要重定向的话则更好的策略则是使用标准的3XX HTTP状态码,首先确保回退按钮能准确工作。
记住重点是重定向将会降低用户体验,在用户与HTML文档之间插入一个重定向将会延迟当前页面的所有东西,当文档到达时,页面上不能渲染并且任何依赖都不能下载。
一个最耗时的重定向频繁发生并且Web开发者通常不在意它。当URL应该有一个反斜杠时但是不存在时则会发生这个问题。例如,访问http://astrology.yahoo.com/astrology导致一个http://astrology.yahoo.com/astrology/(注意新增的斜杠)的重定向。在Apache中能通过Alias或mod_rewrite或者DirectorySlash修复如果你使用Apache handlers。
将新站点链接到老站点是重定向的一个使用场景,另外还包括链接站点的不同部分基于固定的位置(浏览器类型,用户账号类型)进行跳转。使用重定向链接两个站点是相对简单且只需要添加很少的代码。尽管在这些场景使用重定向能够降低开发者的复杂度,但是这会降低用户体验。如果是两个地址访问同一个地址服务器对于重定向可以选择Alias和mod_rewrite。如果重定向中域名发生变化,在Alias和mod_rewrite的组合中可以通过创建一个CNAME(DNS记录中一个域名指向另一个域名的别名)
.4. 缓存Ajax
使用Ajax的一个好处是它立马返回结果因为它是异步请求后端服务器。然而,使用Ajax不能保证用户不会等到这些Javascript和XML异步响应返回。在很多应用中,用户是否保持等待取决于Ajax如何使用。例如,一个Web在线客户端用户将保持等待Ajax请求的根据所有查询条件匹配的返回邮件结果。记住异步不意味着实时十分重要。
优化Ajax响应对于提升性能十分重要。提升Ajax的性能最有效的方案则是缓存响应。正如在添加过期时间或者协商缓存-Control Header讨论中的一样。
让我们来看一个例子。在线邮件客户端2.0使用Ajax自动下载用户的地址簿。如果用户没有修改地址簿自从她上次使用这款应用,那么上一次的地址薄响应能被从缓存中读取如果Ajax响应能够通过过期时间或者协商缓存头部字端进行缓存。浏览器必须通过上一次的地址簿缓存与新的请求响应对比才能得到接到结论。能在Ajax路由上地址上添加一个时间戳表明上次用户修改地址簿解决这个问题,例如,&t=1190241612。如果这个地址自从上次下载时没有被修改,这个时间戳将会和从缓存中读取的地址簿相同从而可以避免额外的HTTP请求。如果用户修改了地址簿,URL上携带的地址簿能够确保不会匹配到缓存中,并且浏览器也会更新缓存中的地址簿条目
该文章阅读需要7分钟,更多文章请点击本人博客halu886
将当前项目中所有JS文件的依赖解析出来。
在前端工程化中,打包是很基础的一个功能点。打包的第一步则是获得所有入口文件(单页面/多页面)的所有依赖。
这篇总结重点则在于如何实现以及优化这一个需求。
.2. 分解
实现这个功能首先需要解决以下几个问题
- 遍历当前项目结构,根据文件后缀获得出JS文件。
- 递归回朔分别对JS文件进行正则解析获取当前文件依赖文件路径
- 将正则解析出来的文件路径转换成绝对路径(兼容客制化配置)
.3. 实现思路
.3.1. 入口文件
通过命令行参数获取项目路径,解析成绝对路径。同时调用core function。
入口文件 ./index.js
1 | |
.3.3. 解析文件依赖树
读取文件内容,首先通过/require\('.*'\)/g全局匹配require(“xxxx”)
对每个匹配到到require(“xxx”)通过正则/'(.*)'/获取第一个子句,
从而拿到src
然后将src加工成可访问的绝对路径进行回朔
1 | |
.3.4. 对路径进行加工
通过正则解析出的src的转换成绝对路径,同时实现一些客制化规则
例如 dialog.js第一步转成./dialog.js
然后被转成/module/dialog.js
再然后被转成/module/dialog/dialog.js
blabla…
1 | |
.4. 总结
demo是通过Node.js编写的,功能虽然并不复杂。
但是对比目前现有的框架,还是非常的粗糙,优化点也是非常多。
正则解析目前只兼容一种格式,
而且每次解析路径都使用正则匹配了两遍路径,
客制化路径转换规则设计的太过于耦合 blabla…
后续应该会开帖继续优化吧
源码地址 requireTreeHandle
以这篇博文为即将结束的2019做一个总结。解决了一些老问题,产生了一些新问题。
但依旧收获满满,2020年会更好~
今年开始尝试每天早上挤20min做算法题,从0刷到60多题,发现当用心提升编程软实力后,在日常工作无论面对多复杂的业务都不会再感到棘手和胆怯了。
并且在刷题的过程中发现JavaScript作为脚本语言对很多数据结构和指针都不够友好,然后重新捡起了Cpp用来做题。
顺便把vim折腾成我的唯一开发工具,同时工作台也升级 hhkb 无刻+4k显示器+mac mini。
同时心血来潮花了两三个月啃完了《深入理解计算机原理》,导致我到现在对计算机底层都还有阴影。
blog也在努力保持每周输出一篇,但是依旧更多的还是对阅读过程难点的复盘和在工作与生活中遇到的问题的梳理。
职场上最大的改变应该从苏州来到上海吧,第一次尝试跳槽,并且作为一个社会人进行求职。如何处理好与老东家的离别,如何筛选出匹配的工作机会,让自己获得更加心仪的offer,blabla,都需要一一解决。
在不影响工作和学习的前提下,提前两个月开始准备面试题和简历.但是当我踏出第一步后发现后续的一切都很顺利,从第一个电话面到最后的决定一共只花费了两个礼拜。 每一个面试邀请都是有条不紊的进行着,而且过程中只耽误了一天的工作.
最后决定加入嵩恒网络(500-999人),薪资涨幅了2.25倍,获得资深Node.js开发工程师的title。
离职当晚和Annie姐以及金伟在酒吧里聊到凌晨三点,无论是价值观还是职场规划以及做人做事,都感触特别多。
在嵩恒被安排在秀场项目前端组,项目组30-50人的研发团队,前端团队就有10人+。
新的办公节奏完全是之前没法比的,需要快速产出,快速试错。在这段时间非常辛苦,同时收获也非常大,不断突破自己的边界。
平均每个月要加班120个小时以上,但是加班费和调休也是比较合理和人性的。
每个人的分工都很细致,职责边界也很明确,如何平衡工作和成长算是比较大的挑战吧。
前端团队比较年轻化,都是一帮对技术充满激情的直男,在团队里面非常荣幸受到了很多小伙伴的帮助和影响。
NodeJs做为前端领域的一个方向,我的日常工作不仅需要处理各种NodeJs平台的需求,还需要独立完成各种前端开发的工作。
从第一次主站的活动页开发,被文俊老哥diss到怀疑人生,然后恶补Css和Html的知识。大清早跑来公司,花了一个多月系统性的看完《CSS世界》,尝试慢慢跟上其他前端小伙伴的节奏。
参与10人+协作的前端项目,发现前端远远比我想象的复杂多了。MVVM,前端工程化,Web性能优化,前端部署,组件化,前端解析视音频流,服务端渲染,CSS在各种浏览器各版本的兼容性,以及H5在各种真机的调试,blabla多种多样的挑战。
接触了各种打包工具fis/webpack/vue-cli,以及Backbone和Vue等框架。不停的在尝试如何写出更加优雅的前端代码,高阶组件的封装,以及与非常专业的中间层同学及后端同学对接。
我的职业规划也自然从NodeJs后端工程师过渡到前端工程师,并且也在努力让自己对行业内各种各样的场景和痛点有更加深刻的感悟。
并且也作为面试官负责前端岗位一二面的质量把控,总共参与了50场+的面试。
对前端领域的就业趋势和薪资待遇也有了不同的感受,短期内前端这个工种还是存在大量的缺口,无论是薪资还是待遇都非常可观,但是更多的是需要基础非常扎实的中高级前端岗位。
身边的接触的大佬越来越多,还有其他各种各样非常高大上的工种,以及前端领域各种层出不穷的新技术和挑战,压力山大~
但是还是希望把握自己的节奏,找准自己的定位,冲冲冲???
2. 生活
脚踝由于运动不当而损伤,坚持了四五年的晨跑也暂停了两个月。
最近每天早上起来做一组瑜伽进行调理再去上班。
天天加完班后再健身一小时到家都12点半了。
每周固定和前端组的小伙伴们约一次酒,酒量倒是锻炼的越来越好了,但是体重也增加了10斤。。。
工作和生活联系的越来越紧密了,大部分喝酒的时候聊的也是职场上的各种乱七八糟的事以及各种各样花里胡哨前端的黑科技。
第一次加入酒局,听着醉醺醺的文俊给我讲了一个小时的Web安全(XSS攻击/http劫持/DNS劫持),既新鲜又有趣。
自从有了小罗送的kindle后,手机彻底被我闲置了,阅读量相较去年简直不止翻了一倍。平均一个月两本,看的书也越来越杂,也越来越包容。小说,科幻,自传,科普,散文,历史,凭感觉挑中哪本都可以耐着性子慢慢看完。
阅读带给我的放松和愉悦也越来越让我沉溺。
3. 爱情
在努力和小罗走向爱情中的下个阶段,双方也越来越熟悉和默契,呆在一起各自干着自己感兴趣的事,完全没有恋爱中的束缚感。
两人共同的旅游基金也慢慢达到预期目标,最近也在筹备明年年初的出国旅行,一起体验更多丰富的经历。
两个人一起长胖然后再一起减肥也是最近的计划。hhh
每周都能见面,能够呆一起看同一部电影,听同一首音乐。幸福就是这么简单> 以这篇博文为即将结束的2019做一个总结。解决了一些老问题,产生了一些新问题。
但依旧收获满满,2020年会更好~
1. 工作
今年开始尝试每天早上挤20min做算法题,从0刷到60多题,发现当用心提升编程软实力后,在日常工作无论面对多复杂的业务都不会再感到棘手和胆怯了。
并且在刷题的过程中发现JavaScript作为脚本语言对很多数据结构和指针都不够友好,然后重新捡起了Cpp用来做题。
顺便把vim折腾成我的唯一开发工具,同时工作台也升级 hhkb 无刻+4k显示器+mac mini。
同时心血来潮花了两三个月啃完了《深入理解计算机原理》,导致我到现在对计算机底层都还有阴影。
blog也在努力保持每周输出一篇,但是依旧更多的还是对阅读过程难点的复盘和在工作与生活中遇到的问题的梳理。
职场上最大的改变应该从苏州来到上海吧,第一次尝试跳槽,并且作为一个社会人进行求职。如何处理好与老东家的离别,如何筛选出匹配的工作机会,让自己获得更加心仪的offer,blabla,都需要一一解决。
在不影响工作和学习的前提下,提前两个月开始准备面试题和简历.但是当我踏出第一步后发现后续的一切都很顺利,从第一个电话面到最后的决定一共只花费了两个礼拜。 每一个面试邀请都是有条不紊的进行着,而且过程中只耽误了一天的工作.
最后决定加入嵩恒网络(500-999人),薪资涨幅了2.25倍,获得资深Node.js开发工程师的title。
离职当晚和Annie姐以及金伟在酒吧里聊到凌晨三点,无论是价值观还是职场规划以及做人做事,都感触特别多。
在嵩恒被安排在秀场项目前端组,项目组30-50人的研发团队,前端团队就有10人+。
新的办公节奏完全是之前没法比的,需要快速产出,快速试错。在这段时间非常辛苦,同时收获也非常大,不断突破自己的边界。
平均每个月要加班120个小时以上,但是加班费和调休也是比较合理和人性的。
每个人的分工都很细致,职责边界也很明确,如何平衡工作和成长算是比较大的挑战吧。
前端团队比较年轻化,都是一帮对技术充满激情的直男,在团队里面非常荣幸受到了很多小伙伴的帮助和影响。
NodeJs做为前端领域的一个方向,我的日常工作不仅需要处理各种NodeJs平台的需求,还需要独立完成各种前端开发的工作。
从第一次主站的活动页开发,被文俊老哥diss到怀疑人生,然后恶补Css和Html的知识。大清早跑来公司,花了一个多月系统性的看完《CSS世界》,尝试慢慢跟上其他前端小伙伴的节奏。
参与10人+协作的前端项目,发现前端远远比我想象的复杂多了。MVVM,前端工程化,Web性能优化,前端部署,组件化,前端解析视音频流,服务端渲染,CSS在各种浏览器各版本的兼容性,以及H5在各种真机的调试,blabla多种多样的挑战。
接触了各种打包工具fis/webpack/vue-cli,以及Backbone和Vue等框架。不停的在尝试如何写出更加优雅的前端代码,高阶组件的封装,以及与非常专业的中间层同学及后端同学对接。
我的职业规划也自然从NodeJs后端工程师过渡到前端工程师,并且也在努力让自己对行业内各种各样的场景和痛点有更加深刻的感悟。
并且也作为面试官负责前端岗位一二面的质量把控,总共参与了50场+的面试。
对前端领域的就业趋势和薪资待遇也有了不同的感受,短期内前端这个工种还是存在大量的缺口,无论是薪资还是待遇都非常可观,但是更多的是需要基础非常扎实的中高级前端岗位。
身边的接触的大佬越来越多,还有其他各种各样非常高大上的工种,以及前端领域各种层出不穷的新技术和挑战,压力山大~
但是还是希望把握自己的节奏,找准自己的定位,冲冲冲???
2. 生活
脚踝由于运动不当而损伤,坚持了四五年的晨跑也暂停了两个月。
最近每天早上起来做一组瑜伽进行调理再去上班。
天天加完班后再健身一小时到家都12点半了。
每周固定和前端组的小伙伴们约一次酒,酒量倒是锻炼的越来越好了,但是体重也增加了10斤。。。
工作和生活联系的越来越紧密了,大部分喝酒的时候聊的也是职场上的各种乱七八糟的事以及各种各样花里胡哨前端的黑科技。
第一次加入酒局,听着醉醺醺的文俊给我讲了一个小时的Web安全(XSS攻击/http劫持/DNS劫持),既新鲜又有趣。
自从有了小罗送的kindle后,手机彻底被我闲置了,阅读量相较去年简直不止翻了一倍。平均一个月两本,看的书也越来越杂,也越来越包容。小说,科幻,自传,科普,散文,历史,凭感觉挑中哪本都可以耐着性子慢慢看完。
阅读带给我的放松和愉悦也越来越让我沉溺。
3. 爱情
在努力和小罗走向爱情中的下个阶段,双方也越来越熟悉和默契,呆在一起各自干着自己感兴趣的事,完全没有恋爱中的束缚感。
两人共同的旅游基金也慢慢达到预期目标,最近也在筹备明年年初的出国旅行,一起体验更多丰富的经历。
两个人一起长胖然后再一起减肥也是最近的计划。hhh
每周都能见面,能够呆一起看同一部电影,听同一首音乐。幸福就是这么简单~~
该文章阅读需要7分钟,更多文章请点击本人博客halu886
回溯法是一种选优搜索解题思路,按照优的解题思路进行向下搜索,当遇到不优的情况会退回去,换一个选择接着向下搜索。判断当前选择不为优时,则称为当前选择为回溯点。
并且回溯法又是一种通用解题思路。
总结来说就是,按一条路往前走,能进则进,不能进则退回来,换一条路走。
2. 解题
编写一个程序,通过已填充的空格来解决数独问题。
一个数独的解法需遵循如下规则:
- 数字 1-9 在每一行只能出现一次。
- 数字 1-9 在每一列只能出现一次。
- 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。
空白格用 ‘.’ 表示。
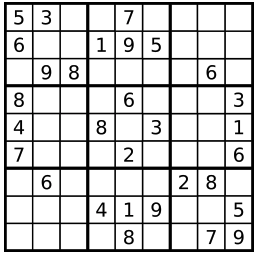
一个数独。

答案被标成红色。
2.1.2. 解题思路
我们从左往右,从下往下搜索空缺的位置,然后依次将 1-9 放入当前位置,当满足条件(当前行/列/三宫格 不存在)时,进入下一个空缺的位置。
当不存在满足条件的数字(1-9)时,回溯到上一个位置,进行更新选择,继续向下搜索。
2.1.3. 源码
1 | |
2.1.4. 分析
2.1.4.1. 时间复杂度
一行不会超过9行,第一个有9种情况,第二个有8种情况…所有一行总共有的(!9)
共9行,所有总共会计算不超过(!9)^9次
2.1.4.2. 空间复杂度
额外多出了col/row/boxes的空间,每一个分别81个元素。
2.2. 组合总和
2.2.1. 描述
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括 target)都是正整数。
- 解集不能包含重复的组合。
示例 1:
输入: candidates = [2,3,6,7], target = 7,
所求解集为:
[
[7],
[2,2,3]
]
示例 2:
输入: candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
2.2.2. 解题思路
通过将所有可能的组合的第一个数字(所有数字)列出作为根结点,每个可能的节点向下展开,子节点向下展开(所有数字),每个节点依次展开,形成一个树状的结构,直至当前路径大于等于target,停止展开。
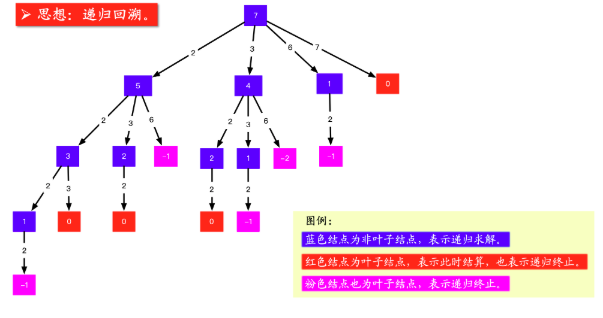
从左往右,从上往下依次搜索,当前路径等于target时进行记录,并且回溯。当大于target时,不记录当前路径直接回溯。
为了防止重复记录相同路径,需要进行剪枝,当子节点小于父节点时,则当前路径已经存在,进行剪枝。
2.2.3. 源码
1 | |
2.2.4. 分析
2.2.4.1. 时间复杂度
回溯法本质上还是枚举,在这题边界过于模糊,并不太好计算。当忽略子节点等于父节点的情况,则为O((!n)^n)。
2.2.4.2. 空间复杂度
多出一个记录路径的额外的数组,数量与n无关
2.3. 通配符匹配
2.3.1. 描述
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 ‘?’ 和 ‘*’ 的通配符匹配。
'?' 可以匹配任何单个字符。
'*' 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。
说明:
- s 可能为空,且只包含从 a-z 的小写字母。
- p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "*"
输出: true
解释: '*' 可以匹配任意字符串。
示例 3:
输入:
s = "cb"
p = "?a"
输出: false
解释: '?' 可以匹配 'c', 但第二个 'a' 无法匹配 'b'。
示例 4:
输入:
s = "adceb"
p = "*a*b"
输出: true
解释: 第一个 '*' 可以匹配空字符串, 第二个 '*' 可以匹配字符串 "dce".
示例 5:
输入:
s = "acdcb"
p = "a*c?b"
输入: false
2.3.2. 解题思路
通过递归回溯进行搜索两个字符串,分别两个指针进行向下遍历,当两个指针指向当字符相同或者为?时,两个指针分别进1。
当存在*,对后续的s子串进行遍历且递归。
回溯点为两个指针指向的字符不同时。
当s子串长度为0时,且p长度为0或p子串全为*。
2.3.3. 源码
1 | |
2.3.4. 分析
2.3.4.1. 时间复杂度
最好的情况下就是只需要遍历一次,不存在回溯点,则为O(n)
最差的情况则是每次都是在最后回溯,O(!n)
2.3.4.2. 空间复杂度
只需要两个指针表示子串的位置,则空间复杂度为O(1)
2.4. N皇后
2.4.1. 描述
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
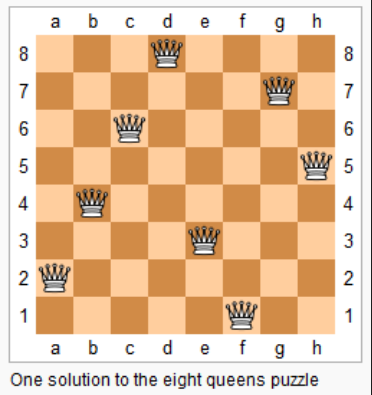
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
示例:
输入: 4
输出: [
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
解释: 4 皇后问题存在两个不同的解法。
2.4.2. 解题思路
当前位置是否能放置Q的约束条件总共有三个,当前行不能存在其余的Q,当前列不能存在其余的Q,当前斜边不能存在其余的Q。
我们可以从左往右,从上往下进行遍历,当满足以上三个条件时进行放置Q且进入下一行,否则跳过。
当一行结束未放置Q时,则视为回溯点,向上回溯。
当遍历到最后一行时,将结果推入结果集中。进行回溯。
当回溯点为第一行最后一个时,则推出遍历,返回结果集。
2.4.3. 源码
1 | |
2.4.4. 分析
2.4.4.1. 时间复杂度
第一行需要遍历1遍,第二行需要遍历n-1,第三行需要(n-1)(n-2)…所以时间复杂度为 O(1+n-1+(n-1)(n-2)…+!n)=O(!n)
2.4.4.2. 时间复杂度
分别需要N*N当二维数组进行记录数组O(N^2)
该文章阅读需要 5 分钟,更多文章请点击本人博客halu886
在网络传输都是明文传输,一旦在传输中被截获风险很高。所以希望提供一种保证传输安全的机制,但是在应用层进行数据的加密和解密成本又太高。最初网景设立一种加密规则 SSL(Secure Socket Layer)。作为传输层加密协议,在传输层传递到应用层被解析为明文,在 IETF 将其标准化,称为 TLS(Transport Layer Security)。
Node 提供了 cypto 和 tls 以及 https 模块,cypto 模块提供了一些加密算法,例如 SHA1,md5 等。tls 提供的功能和 net 类似,但是基于 SSL/TLS 的 TCP 连接之上。https 和 http 接口一致,但是是建立在安全的连接之上。
TSL/SSL
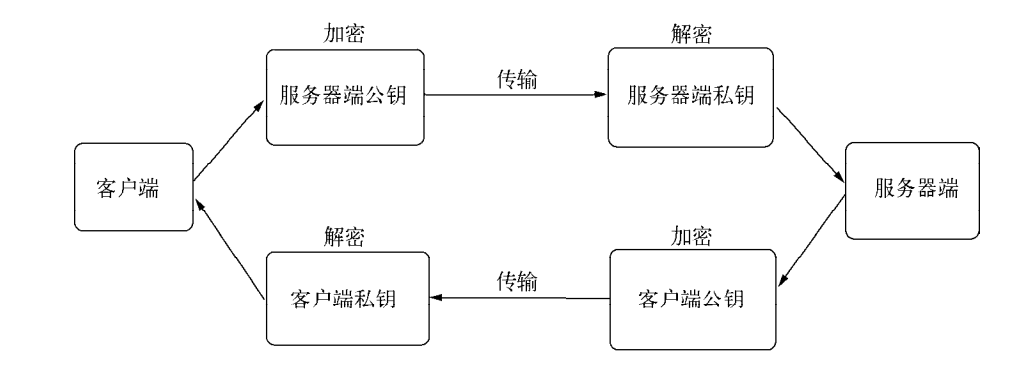
TSL/SSL 都是公钥/私钥的结构,它们是非对称的结构,服务器和客户端各自存在各自公钥和私钥。公钥负责加密数据,私钥负责解密数据,只有私钥能解密公钥加密的数据。在建立连接时,客户端和服务器分别将公钥发送给对方。
Node 底层是通过 OpenSSL 生成公钥和私钥。
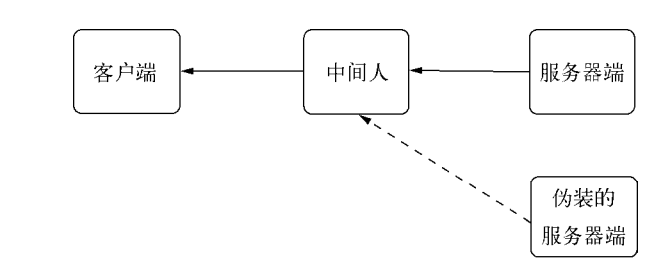
非对称加密虽然好但是也会存在中间人攻击的风险。当客户端与服务端建立连接时,存在一个中间服务器,对客户端来说是服务器,对服务器来说是客户端。中间服务器分别发送自己公钥给客户端和服务端。为了避免这个问题,需要存在一种对得到的公钥进行一种认证的方案。
为了解决这个问题,引入了数字证书。数字签名包括服务器的主机名和名称以及公钥,签名颁发机构的名称,签名颁发机构的签名。客户端通过签名校验公钥是否是合法的。
数字证书
为了确保通信的数据安全,我们建立了一个第三方 CA(Certificate Authority,数字证书认证中心)。作用是为站点颁发证书,并且 CA 中是用了公钥/私钥实现了这个证书。
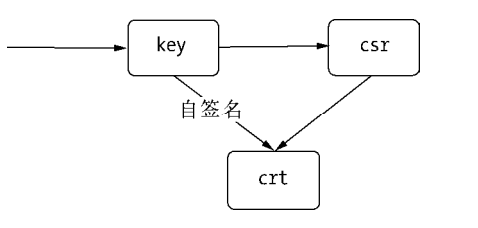
为了得到签名证书,首先需要将私钥生成 csr(Certification Signtaure Request),然后在 CA 通过 crs 获得证书服务器的签名证书。并且只能在 CA 校验签名的真伪。
通过 CA 机构来颁发签名证书,需要花费一定的经历精力和物力,所以大部分公司都采用自签名来构建安全网络,也就是自己作为 CA 机构。
1 | |
以上就是实现建立一个 CA 的步骤。但是在服务器上,需要生成 csr 然后在 CA 上生成签名,同时 Common Name 需要对应域名,不然会申请失败。
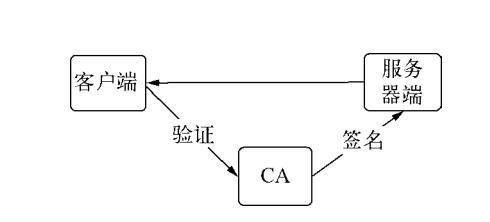
然后通过 CSR 向 CA 申请证书,需要使用 CA 的证书和私钥,然后生成带 CA 签名的证书。
客户端在发起安全连接前会获取服务端证书,然后将服务端证书与 CA 证书验证真伪。同时还包括检验服务器名称和 IP 的过程。
以上知识点均来自<<深入浅出 Node.js>>,更多细节建议阅读书籍:)
该文章阅读需要5分钟,更多文章请点击本人博客halu886
webSocket和node配合起来非常完美,因为
- webSocket基于事件的编程模型和Node的自定义事件十分类似
- webSocket中客户端和服务器端需要保持长连接,同时node基于事件驱动十分适合处理大量的高并发客户端连接
而且webSocket相较于http有以下三点优势
- 客户端与服务器端只存在一个tcp连接,
- 服务端可以推送数据至客户端,更加灵活
- 更加轻量的协议头
webSocket最早是作为HTML特性推出的,在W3C和ITEF的推动下,成为了一个RFC6455的一个规范,现在大部分浏览器都支持这个规范
1 | |
上述代码的含义是当WebSocket确认链接后,每隔50毫秒发送一个hello world至客户端。同时也能接收到客户端的消息。这个行为类似于TCP通信,同时又能和客户端双向通信,所以说应用空间非常大。
在这之前客户端和服务器通信效率最高则是Comet和iframe流。Comet是基于长轮询(long-polling)实现的,客户端向服务器发送一个连接,当服务器返回数据(res.end())或者超时断开连接,客户端里面向服务端重新发送一个请求,由于这样每个请求后面都会拖着长长的尾巴,所以叫做Comet(慧星)连接。
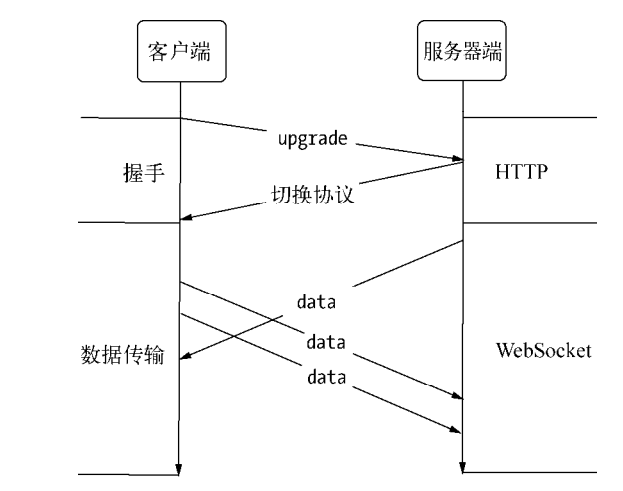
相较于HTTP,WebSocket基于TCP协议重新定义了服务端推送数据的协议,但是三次握手是由HTTP完成的。
webSocket握手
WebSocket发起连接时,通过HTTP发送请求报文
1 | |
与普通HTTP连接的区别在于upgrate和connect字段,表示将请求升级为WebSocket。
Sec-WebSocket-key表示用于安全性校验
客户端将随机生成的字符串asdfqwer321asd==基于Base64编码后发送给服务端,服务端再通过将随机字符串与服务端密钥进行拼接后进行SHA1随机数加密编码为Base64后返回给客户端。
返回报文如下
1 | |
这个报文告诉客户端正在更新协议,将应用层协议更新为WebSocket,同时将套接字连接升级为WebSocket连接。并且客户端会校验服务端基于Sec-WebSocket-Key生成的密钥,如果成功则开始传输数据。
webSocket数据传输
当完成升级协议后,则不再进行http的数据交互,而采用WebSocket的协议传输。
为了完成TCP套接字到WebSocket的事件封装,需要从接收数据时开始进行封装。WebSocket的数据帧协议是在底层data事件开始封装的。
1 | |
以及发送数据也是经过了一层封装
1 | |
为了安全考虑,客户端发送数据帧至服务端时需要对数据进行掩码操作(防止中间层篡改),如果服务端接收到数据没有掩码加密,则关闭连接。但是客户端接收服务端的数据帧时,数据帧则不用进行掩码操作,如果接收到了数据进行掩码操作则断开连接。
以下我们以hello world作为实例,以WebSocket协议分析数据帧构成
- fin:只占一个字节,1表示最后一个数据帧,0则相反
- rv1,rv2,rv3:表示拓展,当都为0时,则是默认格式,不加拓展
- opcode:1~15位,1表示二进制格式,2表示文本格式,8表示ping,9表示pong。当一端发送ping时,另一端则需要发送pong响应,表示存货,其他则都是未被定义的数据格式。
- mask:1表示进行掩码,0表示不进行掩码。
- payload length:长度有可能为7,7+16,7+64为,前七个字节的表示的最大数值只占0~125,如果为126时表示paloadlength7+16。如果为127时,表示长度为7+64。
- masking key:当mask为1时存在,4个字节,用于解密数据。
- payload length:表示携带内容,8的倍数
hello world!一个12个字节一个数据帧完全够了,长度为(12*8)96个位。payload length表示为1100000,所以数据帧如下。
fin(1) + rv1,rv2,rv3(000) + opcode(0001) + mask(1) + payload length(110000) + masking key(32位) + payload length(hello world!加密后的二进制)
以文本格式发送时,编码格式UTF-8,由于这里不存在中文字符。所以一个字符占一个字节。
服务端接收编码数据后,触发data事件, 然后将数据解码位数据帧格式,同时将数据解密出来再执行onMessage事件。
服务端回复yakexi时,就不需要掩码操作了,格式如下
fin(1) + rv1,rv2,rv3(000) + opcode(0001) + mask(0) + payload length(011000) + payload length(yakexi加密后的二进制)
这里的行为类似于TCP套接字的Connect和data事件。
以上知识点均来自<<深入浅出Node.js>>,更多细节建议阅读书籍:)