JB的Python之旅-每句话背后的情绪值
每个人相处都有一套生活方式,跟女人也不一样,不同的女人要用不同的逻辑思考,要琢磨不同语句背后的含义,生活,不容易;

对于情场小白而言,最担心的就是女朋友不开心了,毕竟好不容易才从右手变成了实物,肯定是加倍爱惜的;
但,你真的了解每一句话的情绪分析吗? 给一句话,能知道这句话的情绪占比吗?
情绪分析关键的是词典,网上找了下,大连理工情感词汇本体库比较有名,那就试试看;
下载地址:
链接:https://pan.baidu.com/s/18PeWl-9EjZ7O5Rdfejzgig 提取码:qc3n 复制代码
下载完后,看了下说明文档,了解下,词库里面的格式是这样的:

看起来好像不错,就试试看~
解压说,发现有这几个文件:
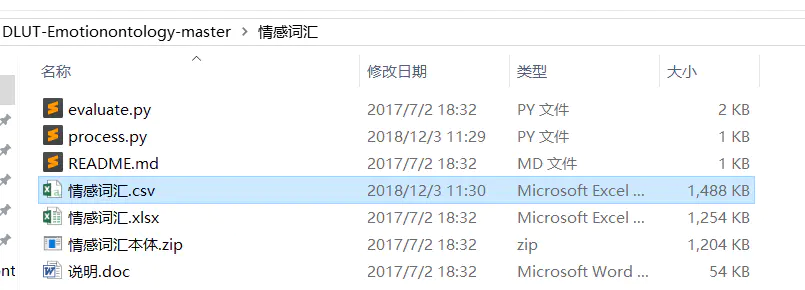
简单介绍下2个py文件:
- evaluate.py,把情感词汇.xlsx转成情感词汇.csv
- process.py
这里需要注意,使用evaluate.py时,有可能会报UnicodeEncodeError这个错;

解决也很简单,在原脚本的第11行,指定encoding用utf-8即可:
with open('情感词汇.csv', 'w',encoding='utf-8') as out_file:
复制代码
而执行evaluate.py时候,需要import docopy跟pandas两个库,自行安装吧;
pip install docopy pandas的话,之前听说很多依赖,后来jb安装个anaconda就好了(全家桶);
复制代码
安装完两个库,因docopy这个库没了解过,因此上官网了解下:
docopt官网上的介绍是:
Command-line interface description language
docopt helps you:
define interface for your command-line app, and
automatically generate parser for it.
复制代码
从中可以看出docopt的两个主要功能:
再看下官网的例子:
Naval Fate. Usage: naval_fate ship new <name>... naval_fate ship <name> move <x> <y> [--speed=<kn>] naval_fate ship shoot <x> <y> naval_fate mine (set|remove) <x> <y> [--moored|--drifting] naval_fate -h | --help naval_fate --version Options: -h --help Show this screen. --version Show version. --speed=<kn> Speed in knots [default: 10]. --moored Moored (anchored) mine. --drifting Drifting mine.
复制代码
在这个例子中,Naval Fate是app名称,naval_fate是命令行命令,ship、new、 move这些是可选的执行命令(commands), x、y、name 这些是位置参数(positional arguments), -h、 --help、--speed等这些是选项参数(options);
例子里面用
- "[]"描述可选元素(optional)
- "()"描述必要元素(required)
- "|" 描述互斥元素(mutually exclusive)
- "..."描述重复元素(repeating)
这些参数,前面加上naval_fate就形成了可用的命令,这些命令在Usage中介绍;
Usage下面的Options里罗列了选项(options)及其描述,它具体描述了
- 选项是否有长/短形式,如-h, --help
- 选项后面是否带参数,如--speed=
- 选项是否有默认值,如[default: 10]
Usage和options里的内容就组成了帮助信息,当用户输入-h或--help参数时,命令行就会输出帮助信息。
docopt会抽取帮助信息里的内容,然后对命令行传入的参数进行解析。
用实例来说明,创建一个test.py文档:
"""Naval Fate. Usage: naval_fate.py ship new <name>... naval_fate.py ship <name> move <x> <y> [--speed=<kn>] naval_fate.py ship shoot <x> <y> naval_fate.py mine (set|remove) <x> <y> [--moored | --drifting] naval_fate.py (-h | --help) naval_fate.py --version Options: -h --help Show this screen. --version Show version. --speed=<kn> Speed in knots [default: 10]. --moored Moored (anchored) mine. --drifting Drifting mine. """
from docopt import docopt if __name__ == '__main__': arguments = docopt(__doc__, version='Naval Fate 2.0') print(arguments)
复制代码
执行命令:
python test.py ship new jb
复制代码
结果:
{'--drifting': False, '--help': False, '--moored': False, '--speed': '10', '--version': False, '<name>': ['jb'], '<x>': None, '<y>': None, 'mine': False, 'move': False, 'new': True, 'remove': False, 'set': False, 'ship': True, 'shoot': False}
复制代码
然后再尝试一个Usage里没有的命令:
Usage: naval_fate.py ship new <name>... naval_fate.py ship <name> move <x> <y> [--speed=<kn>] naval_fate.py ship shoot <x> <y> naval_fate.py mine (set|remove) <x> <y> [--moored | --drifting] naval_fate.py (-h | --help) naval_fate.py --version
复制代码
- docopt(doc)这个函数根据帮助文档的说明解析命令行参数,然后将结果返回为一个字典;
- 当用户使用不在Usage之内的命令,输出帮助文档;
- 要使用的时候,
from docopt import docopt调用即可; - 必填参数,
doc,其他4个是可选(help、version、argv、options_first);
看回evaluate.py这个文件,顶部有这么一段:
__doc__ = '''
Usage: emotion WORD With Python: EmotionDict() --> init EmotionDict.evaluate(word) --> tuple(词语(str), 情感分类(str), 强度(int), 极性(int)) or None
'''
复制代码
这里面也专门告诉py怎么用了,那新建个test.py试试:
from 情感词汇.evaluate import EmotionDict test = EmotionDict()
print(test.evaluate(word="战祸"))
复制代码
直接运行,得到的输出:
('战祸', 'ND', 5, 2)
复制代码
对比了Excel的内容,内容是一样的;

- ND代表憎恶;
- 强度有1、3、5、7、9,9是最高,5则说明一般;
- 极性有4类,0代表中性,1代表褒义,2代表贬义,3带边兼有褒贬两性;
其他的,请看说明.doc,都有说明;
因此,战祸这个词,用贬义的方式来表达内心的憎恶? 不知道为什么,总感觉怪怪的;
一个词就是上面的用法,那一段话呢?
就需要分词了,中文分词用的最多就是jieba库,不了解的同学,请移步此处;
某博直接找来一段话,结合分词,一起看看:
seg_list = jieba.cut("带着立场看比赛注定是痛苦的,倒不如好好品品比赛中每一个精彩的瞬间!",cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
复制代码
输出:
Default Mode: 带/ 着/ 立场/ 看/ 比赛/ 注定/ 是/ 痛苦/ 的/ ,/ 倒不如/ 好好/ 品品/ 比赛/ 中/ 每/ 一个/ 精彩/ 的/ 瞬间/ !
复制代码
seg_list = jieba.cut("带着立场看比赛注定是痛苦的,倒不如好好品品比赛中每一个精彩的瞬间!",cut_all=False)
test = EmotionDict()
for i in seg_list: print(i) print(test.evaluate(word=i))
复制代码
输出:
带
None
着
None
立场
None
看
None
比赛
None
注定
None
是
None
痛苦
('痛苦', 'NB', 7, 0)
的
None
,
None
倒不如
None
好好
None
品品
None
比赛
None
中
None
每
None
一个
None
精彩
('精彩', 'PH', 7, 1)
的
None
瞬间
None
!
None
复制代码
标点符号没做过滤,不太影响; 简单看了下,那么多个词,只有精彩、痛苦是有返回内容的,也就说明,原来的词库远远不够;
而且要把对应的PH、数字对应起来,还需要单独写一个转换逻辑,还要过滤各种符号,这里面还是有很多小细节做的,到这里,效果实在太差了,主要是,词库内容太少了,很多词语都没有,压根就没办法判断;
既然不自己造轮子,那就看看别人的吧,这种语境分析,第一时间就想起BAT了,那就一起看看BAT吧;
直接某度搜索某度自然语言处理,直接弹出某度AI开放平台,点击后看下产品服务,选择自然语言处理,就看到有提供情感倾向分析,同时也有对话情绪识别两个服务,两者应该是共同原理,就看前者了;

点击后,登录,直接点击api文档,翻到情感倾向分析接口;
对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,并给出相应的置信度。
请求示例
- HTTP方法: POST
- 请求URL: aip.baidubce.com/rpc/2.0/nlp…
URL参数
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求示例
{ "text": "苹果是一家伟大的公司" }
复制代码
请求参数
| 参数 | 类型 | 描述 |
|---|---|---|
| text | string | 文本内容(GBK编码),最大2048字节 |
返回参数 参数|说明|描述 --|--| log_id|uint64|请求唯一标识码 sentiment|int|表示情感极性分类结果,0:负向,1:中性,2:正向 confidence|float|表示分类的置信度,取值范围[0,1] positive_prob|float|表示属于积极类别的概率 ,取值范围[0,1] negative_prob|float|表示属于消极类别的概率,取值范围[0,1]
返回示例
{ "text":"苹果是一家伟大的公司", "items":[ { "sentiment":2, //表示情感极性分类结果 "confidence":0.40, //表示分类的置信度 "positive_prob":0.73, //表示属于积极类别的概率 "negative_prob":0.27 //表示属于消极类别的概率 } ]
}
复制代码
Access Token获取是通过API Key和Secret Key来获取的,那这两个怎么获取?
还记得情感倾向分析的主页吗?有个立即使用的按钮,要去创建应用;
点击创建应用,输入应用名称、描述,然后点击查看应用详情,这里面的API Key 跟Secret Key需要使用到;

来到access token获取网址,按照要求试试,官方给的是py2,用py3重弄下,代码如下:
import requests url = 'https://aip.baidubce.com/oauth/2.0/token' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.32 Safari/537.36", "Content-Type":"application/json"
} params = { "grant_type":"client_credentials", "client_id":你的API Key, "client_secret":你的Secret Key }
response = requests.post(url,headers=headers,params=params)
text = response.json().get("access_token")
print(text)
复制代码
对应的结果就是access_token的值啦;
这里遇到个坑,按照官方文档操作,用requests库,无论怎么调,最终都会报下面这个错;
{'log_id': 3838837857684473751, 'error_code': 282004, 'error_msg': 'invalid parameter(s)'}
复制代码
最后网上找了好久,改用urllib库就好了,一脸懵逼。。贴代码:
import json
import urllib access_token=你的access_token值
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token='+access_token headers={'Content-Type':'application/json'} post_data = {"text":"带着立场看比赛注定是痛苦的,倒不如好好品品比赛中每一个精彩的瞬间!"}
data=json.dumps(post_data).encode('GBK') request = urllib.request.Request(url, data)
response = urllib.request.urlopen(request)
content = response.read()
content_str = str(content, encoding="gbk")
print(content_str)
复制代码
输出:
{"log_id": 830621152984506211, "text": "带着立场看比赛注定是痛苦的,倒不如好好品品比赛中每一个精彩的瞬间!", "items": [{"positive_prob": 0.521441, "confidence": 0.571177, "negative_prob": 0.478559, "sentiment": 1}]}
复制代码
根据官网文档,上面4个字段含义如下:
- sentiment,表示情感极性分类结果,官方没具体说明,猜测是跟上面一样,即0代表中性,1代表褒义,2代表贬义,3带边兼有褒贬两性;
- confidence,表示分类的置信度;
- positive_prob,表示属于积极类别的概率
- negative_prob,表示属于消极类别的概率
按照上面的结果,那这句话应该是属于中性词,偏积极;
直接找,会发现文智自然语言处理,产品介绍文档在这里,API指南在这里,官方提供demo,py的demo在这里;
download代码,github上说需要安全凭证,点击登录获取;
然后还要安装对应的依赖库,提供2种方式任君选择:
$ pip install qcloudapi-sdk-python 或者下载源码安装
$ git clone https://github.com/QcloudApi/qcloudapi-sdk-python
复制代码
 python setup.py install
python setup.py install
然后打开tests下的demo.py,修改模块、接口名、接口参数即可;
from QcloudApi.qcloudapi import QcloudApi '''
module: 设置需要加载的模块
'''
module = 'wenzhi' '''
action: 对应接口的接口名,请参考wiki文档上对应接口的接口名
'''
action = 'TextSentiment' '''
config: 云API的公共参数
'''
config = { 'Region': 'ap-guangzhou', 'secretId': 'AKIDmmuRdgSV8sjR0eokVh2159Kp2OiyPHPQ', 'secretKey': 'DNS9h6aBFLYo2BAEBPePI3d3IMGzb7ml',
} action_params = { "content":"带着立场看比赛注定是痛苦的,倒不如好好品品比赛中每一个精彩的瞬间!"
} try: service = QcloudApi(module, config) print(service.generateUrl(action, action_params)) print(service.call(action, action_params))
except Exception as e: import traceback print('traceback.format_exc():\n%s' % traceback.format_exc())
复制代码
输出:
b'{"code":0,"message":"","codeDesc":"Success","positive":0.58672362565994,"negative":0.41327640414238}'
复制代码
对了,某讯没有免费的体验,jb刚好是新人领了个免费礼包,如果不是新手,就要自己充钱的,很X讯;
点击这里-情感分析,登录,点击开通,然后来到控制台;
点击基础版,api调试:
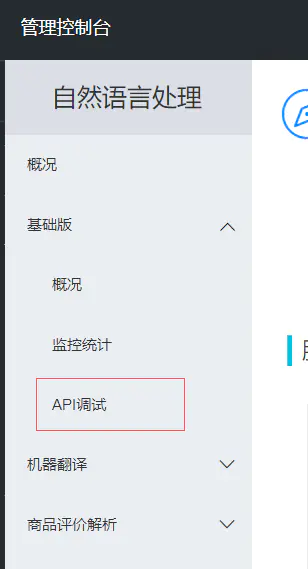
选择api,这里关于情感分析的,只有电商类的,其他都跟情感没啥关系:
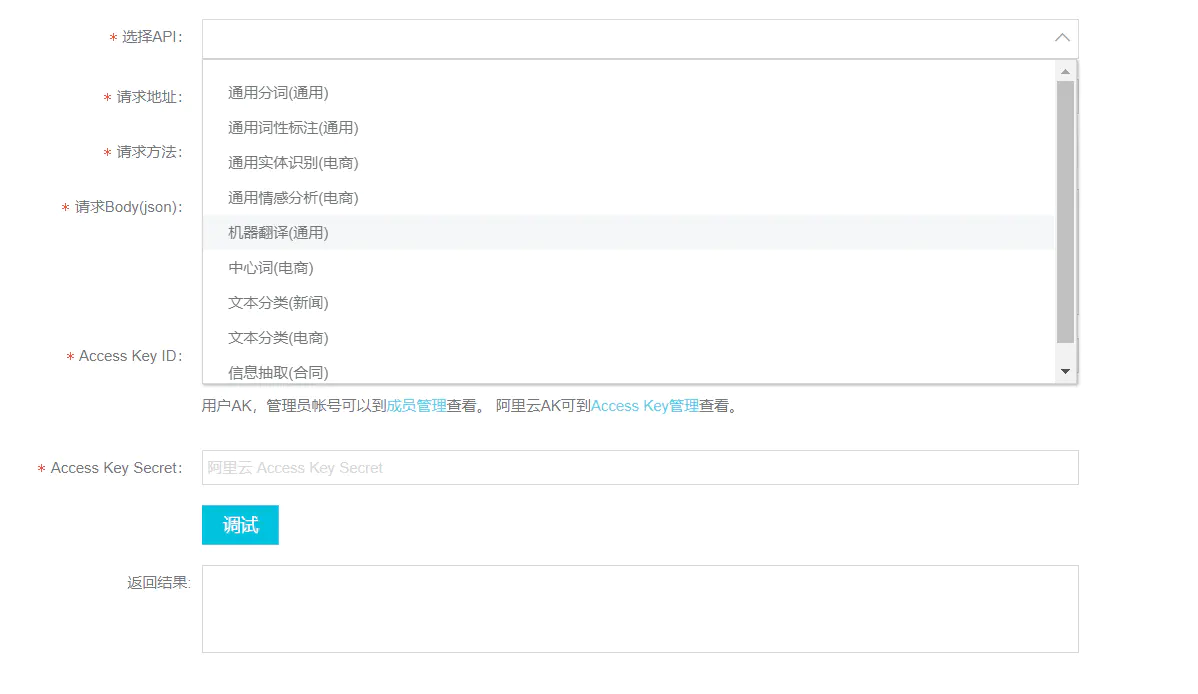
按照要求,输入你的access key跟secret,点击调试即可:

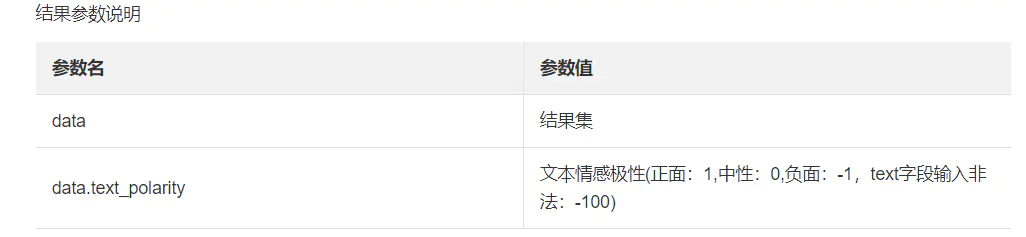
关于响应的讲解,点击这里,可以看到polarity的参数值,因此,例子是负面的,很合理;
剩下的,就是购买了,270起,感兴趣的了解下,使用的话,就到这里了;
阿里提供在线调试,比较方便,但是类型太少了,而且不够详细,结果就是正面、负面、中性3选1,一旦哪天有Bug,就惨了;
这个章节不想讲述太多内容,之前思路都有讲过,只是把代码结合下而已,详情请参考下面两篇文章:
JB的Python之旅-豆瓣自动顶贴功能
JB的Python之旅-爬虫篇-新浪微博内容爬取
上面3个平台的结果很明显,只能用某度,毕竟,免费嘛;
push到微信用的是server酱,直接贴代码:
import re
from json import JSONDecodeError
import time
import requests
from apscheduler.schedulers.blocking import BlockingScheduler
import json
import urllib wb_url = "https://m.weibo.cn/profile/info?uid=你要关注的微博用户id"
server_url = "http://sc.ftqq.com/你的server酱.send" access_token='你的百度access_token值'
bd_url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token='+access_token wb_headers = { "Host": "m.weibo.cn", "Referer": "https://m.weibo.cn/u/随便,一般是你要关注的微博用户id", "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) " "Version/9.0 Mobile/13B143 Safari/601.1",
} wb_params = { "text": "{text}", "desp": "{desp}"
} statuses_id = ""
scheduler = BlockingScheduler()
page_size = 10 def get_time(): """ 获取当前时间 """ return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) def push_wx(text=None, desp=None): """ 推送消息到微信 :param text: 标题 :param desp: 内容 :return: """ wb_params['text'] = text wb_params['desp'] = desp response = requests.get(server_url, params=wb_params) json_data = response.json() if json_data['errno'] == 0: print(get_time() + " 推送成功。") else: print(json_data) print("{0} 推送失败:{1} \n {2}".format(get_time(), json_data['errno'], json_data['errmsg'])) def filter_emoji(text, replace=""): """ 过滤Emoji表情 :param text: 原文 :param replace: 将Emoji替换为此内容 :return: 过滤后的内容 """ try: co = re.compile(u'[\U00010000-\U0010ffff]') except re.error: co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]') return co.sub(replace, text) def get_desp(user, statuse): """ 获取微博内容 """ global text; global nick_name; avatar = user['profile_image_url'] nick_name = user['screen_name'] follow_count = user['follow_count'] followers_count = user['followers_count'] description = user['description'] image = "" created_at = statuse['created_at'] source = statuse['source'] if 'raw_text' in statuse: print(statuse) text = statuse['raw_text'] else: text = statuse['text'] text = filter_emoji(text, "[emoji]") if 'pics' in statuse: pics = statuse['pics'] for pic in pics: image += "\n\n".format(pic['url']) return "\n\n### {1}\n\n关注:{2} and 粉丝:{3}\n\n签名:{4}\n\n发送时间:{5}\n\n设备:{6}\n\n微博内容:\n\n{7}\n\n{8}" \ .format(avatar, nick_name, follow_count, followers_count, description, created_at, source, text, image) def start_task(): response = requests.get(wb_url, headers=wb_headers) try: json_data = response.json() except JSONDecodeError as e: print(get_time() + " Json解析异常, 跳过此次循环:" + str(e)) return state = json_data['ok'] if state != 1: push_wx(get_time() + " 你的女朋友又挂啦,状态码:" + str(state) + ",快去看看吧。", "") scheduler.remove_job('wb') return data = json_data['data'] user = data['user'] statuses = data['statuses'] size = len(statuses) if size < page_size: print(get_time() + " 返回数据不正确,跳过本次循环。 size:" + str(size)) return first_statuse = statuses[0] new_id = first_statuse['id'] global statuses_id if new_id != statuses_id: print(get_time() + " 有新微博! id-> " + new_id) desp = get_desp(user, first_statuse) title = "女神更新微博啦" release_text = SentimentAnalysis() push_wx(title, release_text+desp + "\n\n[微博原文](https://m.weibo.cn/profile/2105667905)") statuses_id = new_id def SentimentAnalysis(): post_data = {"text": text} data = json.dumps(post_data).encode('GBK') request = urllib.request.Request(bd_url, data) response = urllib.request.urlopen(request) content = response.read() content_str = str(content, encoding="gbk") data = json.loads(content_str) positive_prob = '%.2f%%' % (data["items"][0]["positive_prob"] * 100) negative_prob = '%.2f%%' % (data["items"][0]["negative_prob"] * 100) confidence = '%.2f%%' % (data["items"][0]["confidence"] * 100) sentiment = data["items"][0]["sentiment"] if (positive_prob > negative_prob): prob = positive_prob elif (positive_prob < negative_prob): prob = negative_prob else: prob = positive_prob if (sentiment == 0 ): prob_text = "负面" elif (sentiment == 1 ): prob_text = "中性" elif (sentiment == 2): prob_text = "正向" analysis_text = "你女神博主:"+nick_name + ",发布了情绪值为"+prob+",疑似是"+prob_text+"情绪的微博,快来看看吧,可信度:"+confidence+",微博原文是:"+text return analysis_text if __name__ == '__main__': print(get_time() + " 骚年,噩梦来袭!") scheduler.add_job(start_task, "interval", seconds=6, id="wb") scheduler.start()
复制代码
代码不能直接用,要手动输入几个值,微博用户id、某度access_token、server酱,完;

百分号%不知道为什么被过滤了,正常是XX%这样的格式,但是看着懂就好了,不纠结;
通过上面的推送信息,信息最大化,也得出对应的情绪值,但是,女人说的话,要视不同场景而决定其含义;
比如吵架时的分手,其实就是要你哄,要你抱;
比如成家后的不要,是不舍得,偷偷买吧;
复制代码
而这种含义,不结合语境是没法判断的;
而女人的心思,别猜,买/哄/舔就对了;
对了,前提是得有个男/女朋友,不然,还是买点护肤品慰劳下自己的右手吧;
本文主要介绍了情绪分析的内容,有手动统计,也有利用BAT平台的接口,出了某度有免费接口提供外,其他都要收费,而且不低,用来调试或者内部用用,用某度的挺好的,量多可能会收费,但没找到具体文档,不纠结了;
同时学习了Py的docopt模块,会抽取帮助信息里的内容,然后对命令行传入的参数进行解析;
而在试用BAT平台时,会发现调用接口都需要安全凭证/授权校验,目的还是为了安全性,这块是值得学习的,回想下,内部接口是否无需校验就可直接调用?是否会被第三方利用的可能?
最好,祝有女朋友的,幸福美满,避开所有障碍,早日拉埋天窗; 没女朋友的,学会聊天,保持自信,别太死板,最重要是有上进心,阳光活力,换位思考,如果你是女生,你会喜欢自己吗?
最后,谢谢大家!