前言
从某种角度上说,ES 是十分易用的,利用 ES 完成一些基本的写入和查询操作,只需要简单看下文档就能学会。但是 ES 又有很多配置可以自定义,当你有实际的业务需要时,如何能有效利用现有的资源达到比较好的时延和吞吐量确又非常困难。本文就聊一下分片(shard)和副本(replica),来看看究竟应该如何选择一个合适的分片和副本数。
分片副本是什么
分片类似于数据库的分库分表,将一个索引里的数据分到不同的分片中。在写入过程中,通过相应的路由手段(默认规则是分片编号=hash(_id)%总分片数)写入相应的分片。在查询过程中,会分别查询所有分片并将结果汇总得到最终查询结果,这样就可以将非常大量的索引数据分散到不同的分片中,由于每个分片的查询都使用一个线程,这样可以有效地减小单次查询的时延。
副本其实很容易理解,用处就是保证当部分节点掉出集群时保证 ES 集群的可用性。副本数量越多,能容忍节点脱离的数量就越多。另外,副本也是一种分片,也可以执行查询任务。
分片副本数量应该怎么选
副本数量比较好选,根据你需要的可用性选择就好。另外,副本越多,写入消耗就越大(相当于写了不止一份的数据)。
接下来,我们主要聊一下查询过程中一个节点上的分片数量应该有几个(这里说的分片就包含了副本,因为副本也会参与到查询中去)。
既然分片数量增加,单个线程可以更快地完成单 shard 的查询,那么是不是分片越多越好呢?其实不然,分片数量过多会导致以下三个问题:
- 多个 shard 并发查询会使用到更多的线程数,这样会增大 CPU 上下文切换次数,可能会增大时延
- 一次查询会查询多个 shard,并将结果合并,这会受木桶效应影响,一旦某一个或几个 shard 的查询时延增大,总的查询时延也会受到影响。(在这种情况下,网络波动是一个容易出现的影响因素)
- ES 使用主从机制,shard 信息的元数据需要 master 节点管理。当 shard 数量增多时,master 节点同步元数据的压力会增大,可能会影响集群的可用性。ES 在 7 版本之后增加了一个参数 cluster.max_shards_per_node 限制单节点 shard 数量不超过 1000
分片最少一个节点一个(shard 数量为 1,replica 数量为 node 数-1),这种情况下由于无法利用分片并发查询,时延会比较高。那么最多应该是多少呢?
其实这里可以参考 ES 源码中 SEARCH 线程池的设置,保持单节点同时被查询的分片数不超过 SEARCH 线程池的大小(即 1.5 倍核数+1)。因为如果超过这个数值的话,同一时刻的查询任务就肯定会遇到排队的情况。排队就会影响到查询的时延和吞吐量。这是为什么呢?
这里其实逻辑有问题,排队与否与吞吐量有很大的关系,并不是同时被查询的分片数不超过 SEARCH 线程池大小就行。并且,ES 有一个查询时候的配置:max_concurrent_shard_requests,默认是 5,作用是一次查询中 coordinate 节点不会发送给一个节点超过这个数量的 shard 查询,就是为了避免节点压力过大。
吞吐量和时延
首先,时延这个问题很好理解,可以参考下图:
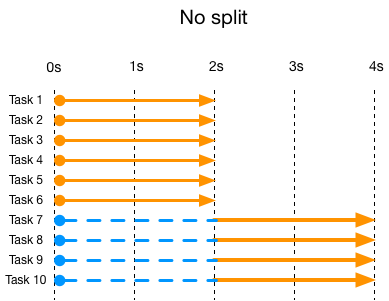
假设有一次查询需要查询 10 个分片,但是线程池只有 6 个线程可用。这个时候有 2 个线程在后 2 秒的时间里无事可做,时延必定会收到影响。这里可以继续延伸一下得到一个很有趣的结论,并行的任务数如果能够整除线程数,那么时延是不会受到影响的。还有一点需要注意,如果一次查询没有跑满 CPU,时延也是会延长的。
接着再说一下吞吐量的问题。事实上,在 CPU 占用 100%的理想情况下(无 IO),吞吐量不会受到分片数量的影响。举个例子,假设 CPU 核数是 4,单节点集群有 1 个分片和单节点有 4 个分片的情况下,单位时间内响应的请求数量是一样多的。(比如跑慢满 4 个核,1 个分片单位时间可以响应 4 个请求,假设需要 4 个单位时间处理完毕,就是 4 个单位时间处理 4 个请求;4 个分片单位时间内也可以响应 1 个请求,但在单位时间内就可以将请求处理完,所以也是 4 个单位时间处理 4 个请求)。但是由于有了 IO 的损耗,并行多任务的 IO 时间消耗不等于原时间/任务数。换句话说:将大任务分解成小任务的 CPU 耗时不变,但会增加 IO 的耗时,从而影响吞吐量。
这里也有些问题,不知道当时是为什么得出来小任务 IO 损耗高的结论的。不过,将大任务分解为小任务会让线程上下文切换更频繁,从而影响一些性能。从这个例子也能看出来,不考虑线程上下文切换,两者的吞吐量是一样的,但是小任务的时延要少很多,单位时间就能响应 1 个请求。但由于线程切换和上面提到的木桶效应,这种时延可能会收到影响。
SEARCH 线程池为什么是 1.5 倍核数+1
这里我可以举一个形象的例子,假设 CPU 核数是高速路的车道数 C,每一条车道对应一个核,收费站数量则是线程数 P。现在假设 P=C=10,并且每一辆车都用 ETC 过收费站(假设占了 10 个 CPU 时间片),这种情况下每一个任务(车)都正好占了一个核(收费站),此时 CPU 被占满。假设所有 ETC 换成了人工收费口,过收费口时有一半的时间都被浪费在了掏手机扫码上(5 个时间片 IO,5 个时间片占用 CPU),这种情况下进去 10 辆车,只能出 5 辆车,CPU 占用率只有一半。此时如果想要占满 CPU,那么就需要提高线程数,让一个收费员负责两个车道,这样分下来就可以进去 10 辆车,出来 10 辆车了。
通过这个例子,可以推断出:ES 假设了平均情况下一个查询时间中 CPU 时间:IO 时间=2:1,因为这样设置 SEARCH 线程可以将 CPU 跑满。这样我们可以得出一个结论:单节点最多被查询的分片数量为 1.5 倍核数+1
那么单节点同时被查询分片数量的上限可以认为是 1.5 倍核数+1,因为这种情况下 CPU 会被占满。从上面对于吞吐量和时延的分析来看,这样子会达到查询收益的最大化。
同上,这里描述有问题。现在看来 ES 这样设置 SEARCH 线程池可能只是根据经验设置的,来保证查询的吞吐量最大化。
总结
当然,本文给出的结论仅仅是启发式的,上面这种计算方式只能作为一种预估的手段,毕竟做了许多的理想化假设。并且实际情况下,集群会有写入等其他操作,不可能让查询占满 CPU 资源。另外,如果集群出现节点脱离集群的问题,分片容量过大会造成集群无法很快恢复,这里 ES 官方给出的建议是单分片不要超过 50GB 大小。
所以,综上所述,分片数量的选择仍然是很复杂,需要根据实际情况做出调整。