类库
› ocr-extractor
jritzi/ocr-extractor
OCR Extractor是Obsidian插件,利用OCR技术从笔记中的PDF、图片和文档提取文本,并作为可折叠引用块存储为Markdown。支持多种本地或云端OCR服务,提取内容可通过Obsidian及系统搜索功能查找。
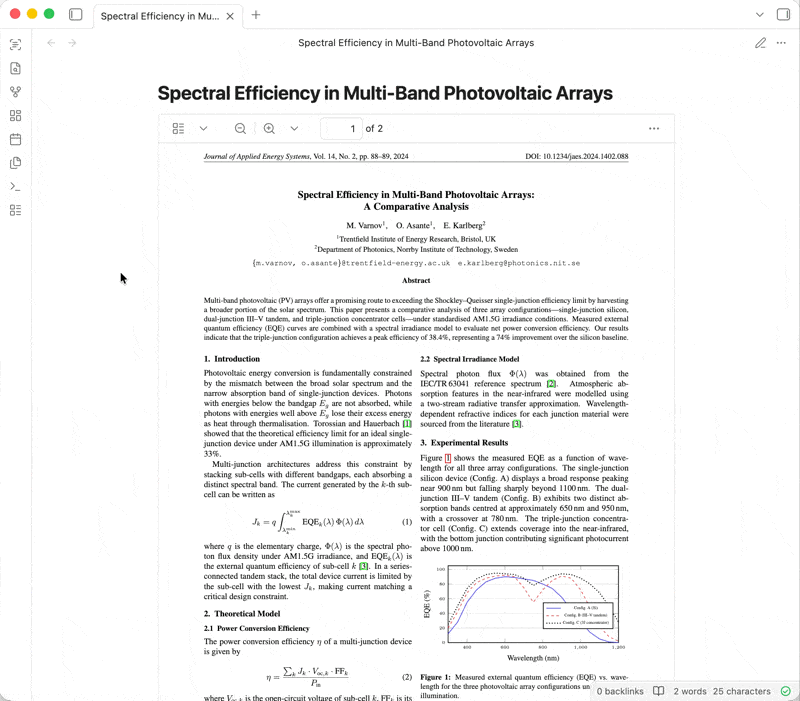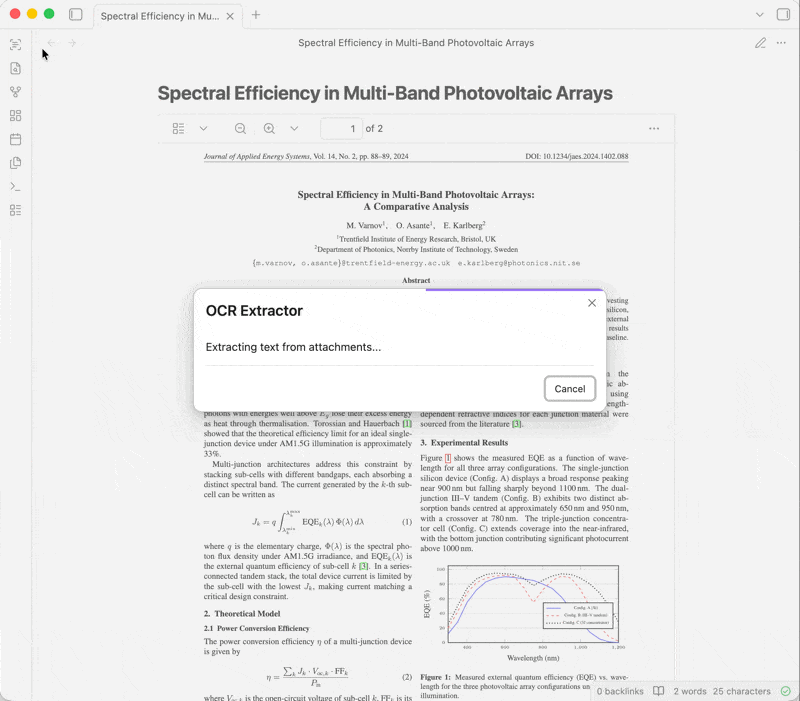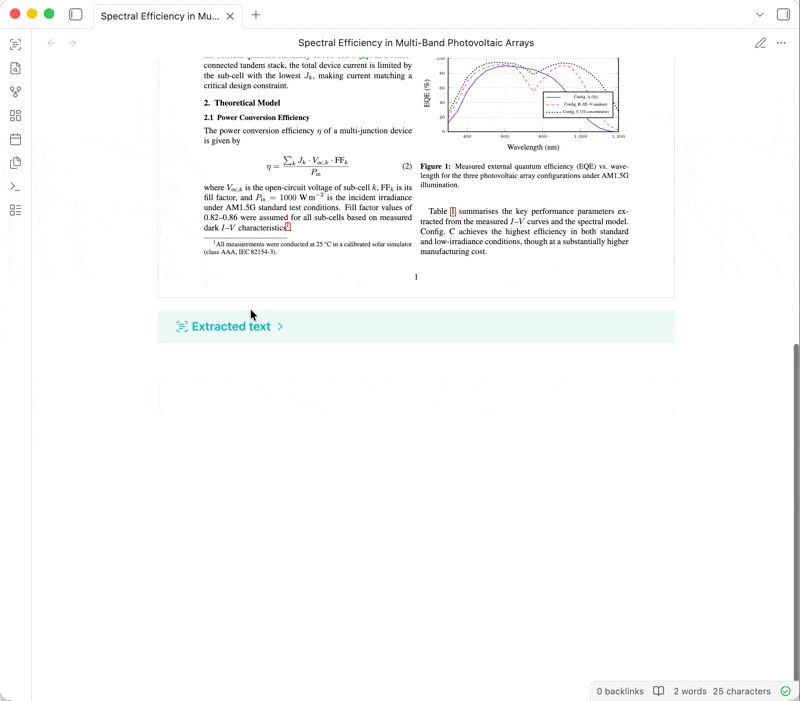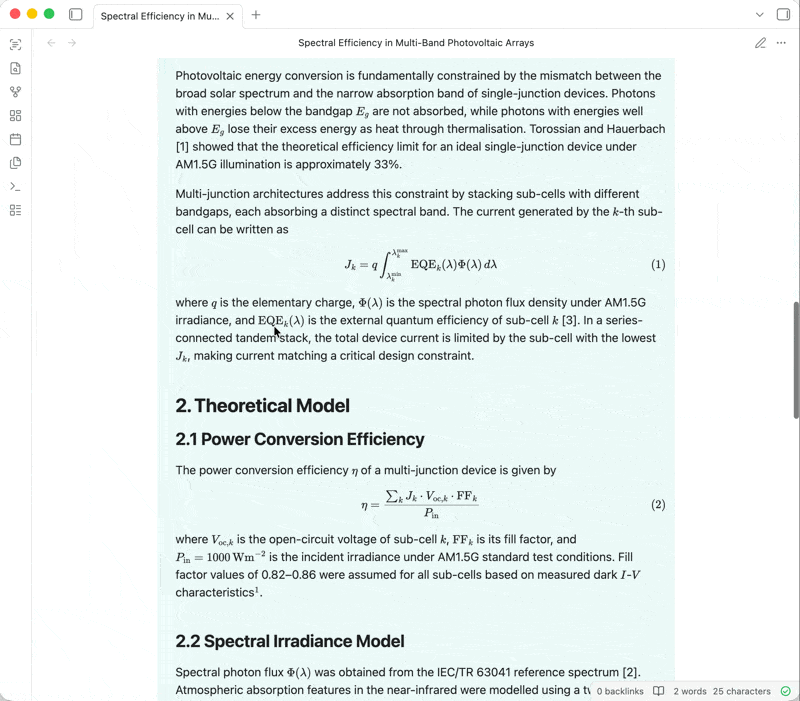
技术栈
根目录 javascript
构建工具
Vite
^8.0.16
esbuild
0.28.1
测试
Playwright
^1.60.0
Vitest
^4.1.8
代码规范
ESLint
^9.39.4
Prettier
3.8.3
查看全部依赖 (23)
依赖
@mistralai/mistralai
^2.2.5
file-type
^22.0.1
i18next
^26.0.6
openai
^6.42.0
pdfjs-dist
5.4.624
semver
^7.8.0
tesseract.js
^7.0.0
开发依赖
@electron/asar
^4.1.2
@eslint/config-helpers
^0.6.0
@eslint/js
^9.39.2
@mswjs/interceptors
^0.41.6
@tesseract.js-data/eng
^1.0.0
@types/node
^24.10.13
@types/semver
^7.7.1
eslint-config-prettier
^10.1.8
eslint-plugin-obsidianmd
^0.2.9
generate-license-file
^4.2.1
globals
^17.6.0
jiti
^2.5.1
obsidian
^1.12.3
tslib
2.8.1
typescript
6.0.3
typescript-eslint
^8.60.1