领域驱动设计之基础篇
领域驱动设计不是新鲜的概念,自2004年由建模大师Eric Evans发表他最具影响力的书籍《领域驱动设计—软件核心复杂性应对之道》至今已有十六年1·时间,一直以来不曾大行其道,直到IT行业内掀起微服务的狂潮,技术界才重新审视和意识到领域驱动设计的价值。不能说微服务拯救了领域驱动设计,但是确实因为微服务,让领域驱动设计又重新焕发了青春。DDD是一个非常庞大的建模和设计体系。
2. 什么是领域驱动设计(DDD)
DDD是一种开发理念,让软件开发所有参与者围绕一个统一的和一致的领域模型建模和设计,分析模型和设计模型不再割裂,并引出以领域为核心的分层架构,有效的隔离业务和技术复杂度,使得领域层的代码和领域模型保持高度一致。
DDD分为战略设计和战术实现两个阶段
2.1. DDD战略设计阶段
DDD战略设计主要包括领域/子域、通用语言、限界上下文和上下文映射图等概念
2.1.1. 通用语言—提炼统一领域模型
领域专家代表最了解业务领域知识的专业人员,可以是任何角色(业务专家、产品或者技术人员),为了避免业务知识缺失,技术人员需要同领域专家一起,通过统一通用语言,可以不限于交流形式的共同建模,寻找达成一致的领域模型。
关于领域模型的说明
-
领域模型是对具体某个边界领域的一个抽象
-
领域模型只反应业务,和任何技术实现无关
-
领域模型确保了我们的软件业务逻辑都在一个模型中,都在一个地方
-
领域模型能够帮助开发人员相对平滑地将领域知识转化为软件构造
-
领域模型贯穿软件分析、设计、以及开发的全部过程
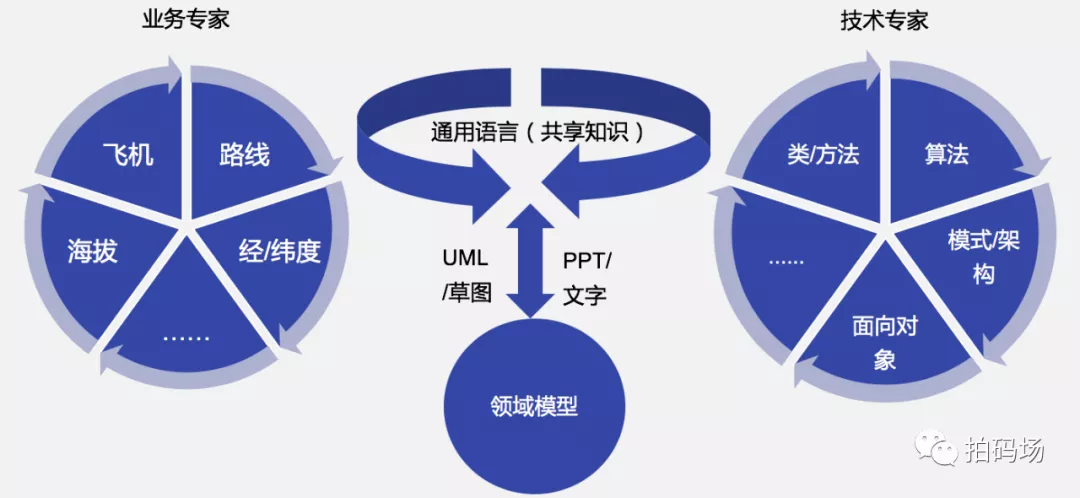
基于通用语言构建领域模型
2.1.2. 限界上下文/子域
一个显示边界,领域模型即存在于这个边界之内。在边界内,通用语言有特定明确的意义。限界上下文明确了业务范围和职责边界。其中就“上下文”来说,上下文关注的是两个系统交互时的环境,或者说语境。通用语言需要在限界上下文(语境)中保证明确其意义。比如商家管理上下文中,我们(平台)说的用户指的是商家而不是买家,支付上下文中,我们以支付单为核心,语境无需引入物流单、库存等词汇。通常来说,我们可以近似地认为子域和限界上下文是一一对应的。
-
边界的理解
-
领域逻辑层面:限界上下文确定了领域模型的业务边界,维护了模型的完整性与一致性,从而降低系统的业务复杂度。
-
团队合作层面:限界上下文确定了开发团队的工作边界,建立了团队之间的合作模式,避免团队之间的沟通变得混乱,从而降低系统的管理复杂度。
-
技术实现层面:限界上下文确定了系统架构的应用边界,保证了系统层和上下文领域层各自的一致性,建立了上下文之间的集成方式,从而降低系统的技术复杂度。
-
限界上下文:具备“自治”的单元,可以对应一个微服务
-
最小完备:实现”自治“的基本条件。所谓”完备“,是指自治单元履行的职责是完整的,无需针对自己的信息去求助别的自治单元,这样就避免了不必要的依赖关系。
-
自我履行:意味着由自治单元自身决定要做什么,这些自治单元能够对外部请求做出符合自身利益的明智判断,是否应该履行该职责,由限界上下文拥有的信息来决定。
-
稳定空间:指的是减少外界变化对限界上下文内部的影响。
-
独立进化:与稳定空间相反,指的是减少限界上下文的变化对外界的影响。
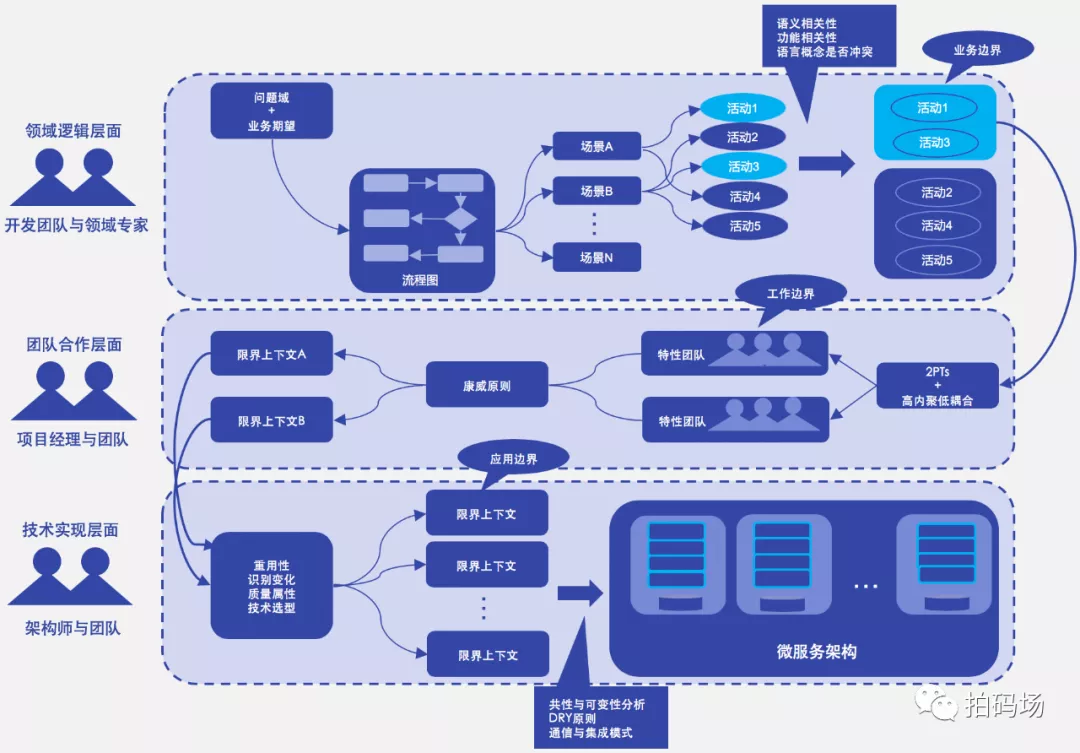
构建限界上下文的流程
2.1.4. 上下文映射图
上下文映射图其实就是不同上下文是如何进行交流的关系
- 三种集成方式
-
RPC方式
-
消息队列或者发布-订阅机制
-
restful方式
- 上下文映射的种类
-
合作关系:代表上游系统之间的关系异常密切,要么同时成功,要么同时失败。
-
共享内核:避免重复,往往用来解决合作关系引入的问题。
-
客户方-供应商开发:
-
下游团队对上游提出领域要求
-
上游团队提供服务采用的协议以及调用方式
-
上游团队给下游团队承诺的交付日期
-
遵奉者:
-
可以直接重用上游上下文模型。
-
减少了上下文之间模型转换的成本。
-
下游限界上下文对上游产生了模型上的强依赖。
-
分离方式:两个限界上下文无一点关系,它们可以独立变化而互不影响。
-
防腐层:引入中间层,隔离下游对上游的依赖;适配器、调停者or外观者等结构型设计模式。
-
开放主机模式:上游限界上下文定义边界,公开发布标准化语言(restful,rpc等),下游基于标准化语言集成。
-
发布/订阅事件:松耦合,适用于异步非实时的业务场景(基于事件驱动架构或CQRS架构模式)。
实施DDD时,我们应该将战略设计放在一个重要的位置。它帮助我们从一个宏观的角度观察和审视软件系统,其中的限界上下文和上下文映射图帮助我们正确的划分各个子域(系统)。而拆分的子域,其实就是我们需要构建的微服务。
2.2. DDD战术实现阶段
2.2.1. 实体(Entity)
一个典型的实体应该具备三个要素:
-
身份标识:管理实体生命周期,如果没有唯一的身份标识,就无法追踪实体的状态变更,也就无法正确保证实体从创建、更改到消亡的生命过程。
-
属性
-
基本属性:通过基本类型定义的属性,如整型、布尔型、字符串类型等等
-
组合属性:通过自定义类型来定义的属性,比如类别Category,重量(Weight),单价(Price),自定义类型一般是指值类型
- 领域行为
-
变更状态的领域行为
-
自给自足的领域行为
-
互为协作的领域行为
//区别传统定义Product对象,只存在属性,不会存在包含领域行为的方法,所有的行为操作放置在服务逻辑层public class Product extends Entity<ProductId> { private String name; //字符串定义的属性 private int quantity; //整型定义的属性 private Category category; //值对象定义的复合属性 private Weight weight; //值对象定义的复合属性 private Volume volume; //值对象定义的复合属性 private Price price; //值对象定义的复合属性 //领域行为,修改产品价格 public void changePriceTo(Price newPrice) { if (!this.price.sameCurrency(newPrice)) { throw new CurrencyException("Cannot change the price of this product to a different currency"); } this.pri = newPrice; }}
2.2.2. 值对象(Value Object)
通常作为实体的属性而存在,在领域建模时,应该优先考虑使用值对象来建模而不是实体对象。因为值对象没有唯一标识,具备不可变性,是线程安全的,不用考虑并发访问带来的问题。值对象比实体更容易维护,更容易测试,更容易优化,也更容易使用。
如下Money值对象的定义
-
可以通过final定义的不变性,保证了其线程安全的特征。
-
Currency定义了其Money的特征,比如是RMB,美元或其他货币类型,Value定义了其属性值,add/minus表达了其领域行为。
-
由于不存在唯一标识,可以用新的Money对象替换当前Money而不不用担心对象安全问题。
@Immutablepublic final class Money { private final double faceValue; private final Currency currency; public Money() { this(0d, Currency.RMB) } public Money(double value, Currency currency) { this.faceValue = value; this.currency = currency; } public Money add(Money toAdd) { if (!currency.equals(toAdd.getCurrency())) { throw new NonMatchingCurrencyException("You cannot add money with different currencies."); } return new Money(faceValue + toAdd.getFaceValue(), currency); } public Money minus(Money toMinus) { if (!currency.equals(toMinus.getCurrency())) { throw new NonMatchingCurrencyException("You cannot remove money with different currencies."); } return new Money(faceValue - toMinus.getFaceValue(), currency); }}
2.2.3. 聚合根(Aggregate Root)
在 Domain-Driven Design Reference 中,Eric Evans 阐释了何谓聚合模式:“将实体和值对象划分为聚合并围绕着聚合定义边界。选择一个实体作为每个聚合的根,并允许外部对象仅能持有聚合根的引用。作为一个整体来定义聚合的属性和不变量(Invariants),并将执行职责(Enforcement Responsibility)赋予聚合根或指定的框架机制。”
聚合的基本特征
-
聚合是包含了实体和值对象的一个边界
-
聚合内包含的实体和值对象形成了一棵树,只有实体才能作为这棵树的根,这个根称为聚合根(Aggregate Root),这个实体称为根实体
-
外部对象只允许持有聚合根的引用,如此才能起到边界的控制作用
-
聚合作为一个完整的领域概念整体,在其内部会维护这个领域概念的完整性,体现业务上的不变量约束
-
由聚合根统一对外提供履行该领域概念职责的行为方法,实现内部各对象之间的行为协作。
聚合与值对象、实体;聚合与聚合,实体引用聚合的关系
-
聚合内部的对象可以保持对其他聚合根的引用
-
聚合外部的对象不能引用除根实体之外的任何内部对象
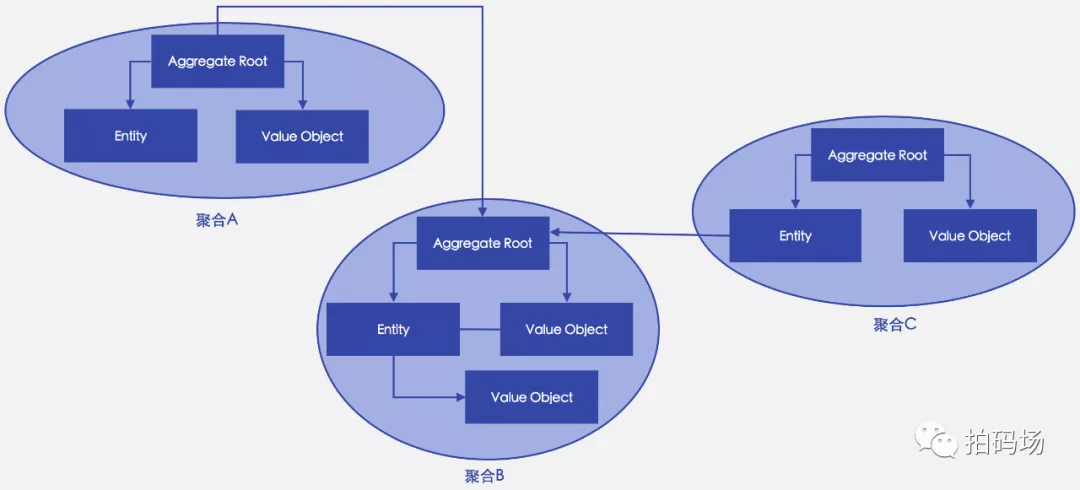 聚合引用关系图
聚合引用关系图
聚合与限界上下文、限界上下文与微服务之间的关系
-
同一个聚合和同一个限界上下文中的领域对象一定是在同一个进程边界内
-
一个限界上下文可以包含一个或多个聚合;一个微服务也可以包含一个或多个限界上下文
-
同一个进程内的聚合(聚合A和聚合B,聚合C和聚合D)之间的协作可以通过本地事务保证数据强一致性
-
跨进程聚合(聚合B和聚合C)协作,需要采取最终一致性方案(Saga/事件消息)保证数据最终一致性
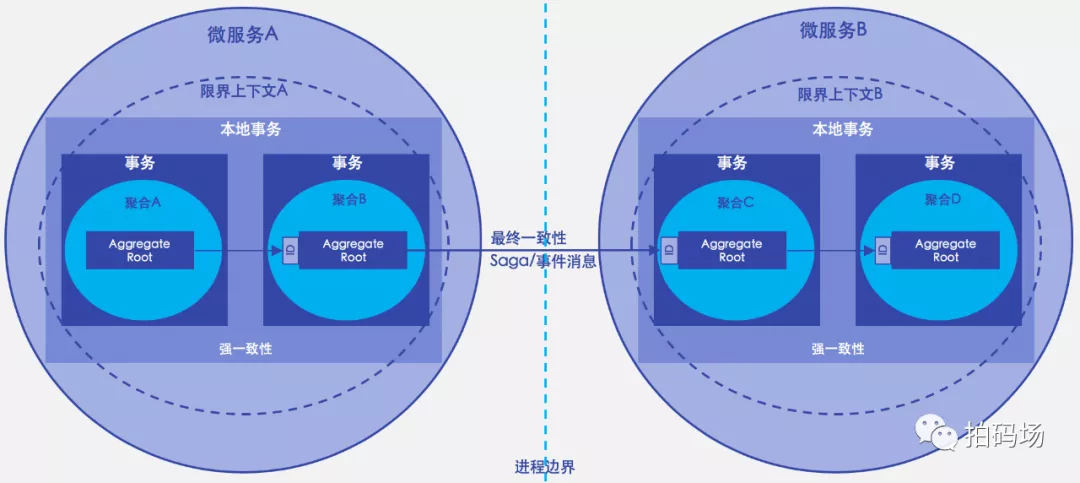 聚合与上下文
聚合与上下文
2.2.4. 工厂(Factory)
DDD要求聚合内所有对象保证一致的生命周期,这往往会导致创建逻辑趋于复杂。为了减少调用者的负担,同时也为了约束生命周期,通常都会引入工厂来创建聚合。除了极少数情况需要引入工厂方法模式或抽象工厂模式外,主要表现为四种形式:
-
由被依赖聚合担任工厂:仅适用于聚合产品的创建需要用到聚合工厂的“知识”,比如
public class Customer extends Entity<CustomerId> implements AggregateRoot<Customer> { // 工厂方法是一个实例方法,无需再传入CustomerId public Order createOrder(ShippingAddress address, Contact contact, Basket basket) { List<OrderItem> items = transformFrom(basket); return new Order(this.id, address, contact, items); }}public class PlacingOrderService { private OrderRepository orderRepository; private CustomerRepository customerRepository; public void execute(String customerId, ShippingAddress address, Contact contact, Basket basket) { Customer customer = customerRepository.customerOfId(customerId); Order order = customer.createOrder(address, contact, basket); orderRepository.save(order); }}
-
订单领域服务作为调用者,可通过Customer创建订单:
-
Order聚合引用了Customer聚合,就可以在Customer类中定义创建订单的工厂方法:
-
引入专门的聚合工厂:使用专门的聚合工厂可以明确说明它的职责,这时为了限制调用者绕开工厂直接实例化聚合,需要将聚合根实体的构造函数声明为包范围内限制,并将专门的聚合工厂与聚合产品放在同一个包中。例如:
package com.ddd.koma.order;public class Order... Order(CustomerId customerId, ShippingAddress address, Contact contact, Basket basket) {}package com.ddd.koma.order;public class OrderFactory { public static Order createOrder(CustomerId customerId, ShippingAddress address, Contact contact, Basket basket) { return new Order(customerId, address, contact, basket); }}public class PlacingOrderService { private OrderRepository orderRepository; public void execute(String customerId, ShippingAddress address, Contact contact, Basket basket) { Order order = OrderFactory.createOrder(customerId, address, contact, basket); orderRepository.save(order); }} -
聚合自身担任工厂:当不想承担多定义工厂类的负担时,可以让聚合产品自身承担工厂角色。例如
package com.praticeddd.ecommerce.order;public class Order... // 定义私有构造函数 private Order(CustomerId customerId, ShippingAddress address, Contact contact, Basket basket) {} public static Order createOrder(CustomerId customerId, ShippingAddress address, Contact contact, Basket basket) { return new Order(customerId, address, contact, basket); }}Order order = Order.of(customerId, address, contact, basket);
-
下单时创建订单
-
Order自己创建Order聚合的实例,该方法为静态工厂方法
- 使用构建者组装聚合:当需要多个参数进行组合创建,构造函数或工厂方法的处理方式就会变得很笨拙,只能通过定义方法重载,不断地定义各种方法去响应各种组合方式。通过_构建者模式_,将复杂对象的构建与类的表示分离,采用流畅接口风格来完成对聚合对象的组装。
2.2.5. 资源库(Repository)
资源库是对数据访问的一种业务抽象,使其具有业务意义。利用资源库抽象,就可以解耦领域层与外部资源,使领域层变得更为纯粹,能够脱离外部资源而单独存在。
资源库的设计原则:一个聚合对应一个资源库
同传统DAO的区别
-
资源库操作的是属于领域层中的具有边界的聚合;DAO操作的是数据传输对象,即持久化对象,该对象与DAO一起都位于数据访问层;倘若使用DAO操作领域对象,最大的区别在于聚合的引入。
-
资源库强调了聚合生命周期的管理,其目的在于获取聚合对象的引用,在形成聚合的对象图后,便于调用者对其进行操作。
2.2.6. 领域服务(Domain Service)
当存在下面其中的一种情况时,需要考虑引入领域服务
-
当存在聚合为了控制边界,并不会直接与别的聚合协作
-
当业务系统中,有一些领域行为不适合放在任一聚合中,它们要么不需要聚合自身已知携带的数据,或者存在与聚合截然不同的变化方向
-
当聚合需要同基础设施进行交互协作
领域服务的特征
-
领域行为与状态无关
-
领域行为需要多个聚合参与协作,目的是使用聚合内的实体和值对象编排业务逻辑
-
领域行为需要与访问包括数据库在内的外部资源协作
对领域行为建模时,需要优先考虑使用值对象和实体来封装领域行为,只有确定无法寻觅到合适的对象来承担时,才将该行为建模为领域服务的方法。
建模优先级顺序为:值对象(Value Object)→ 实体(Entity)→ 领域服务(Domain Service)
2.2.7. 领域事件(Domain Event)
领域事件是领域专家所关心的发生在领域中的一些事件。
主要用途
-
保证聚合间的数据一致性
-
替换批量处理
-
实现事件源模式
-
进行限界上下文集成
分类
-
内部事件:是一个领域模型内部的事件,不在限界上下文间进行共享
-
外部事件:是对外发布的事件,在多个限界上下文中进行共享
3. 与传统架构的区别
3.1. 开发模式对比
-
传统开发模式
-
适用于业务简单的系统的开发,比如大多数基于CRUD的系统
-
业务知识在传递过程中往往存在失真、甚至丢失的情况;容易造成研发构建的系统同业务需求不一致,导致项目失败
-
对技术团队整体要求不高
-
DDD开发模式
-
适用于复杂场景的业务系统的开发,具备复杂的用例场景或者用户故事。
-
整个业务系统构建的过程都基于领域模型统一构建,不存在业务知识缺失的情况,容易构建出满足业务期望的系统。
-
对技术团队的要求高,需要团队成员都了解DDD相关的知识。
DDD与传统开发模式对比
3.2. 分层架构对比
-
传统分层架构—贫血架构
-
经典三层架构中,代表领域概念的JavaBean被放在了数据访问层,而非业务逻辑层。贫血领域对象无法表达业务逻辑,当业务逻辑变得复杂时,无法有效的应对重用和变化,且可能导致臃肿的“上帝类”。
-
更多基于面向数据库、以过程范式的方式进行编码;无法充分运用面向对象的技术。
-
从分层职责和意义上讲,一个系统的基础不仅仅限于对于数据库的访问,还包括访问诸如网络、文件、消息队列或其他硬件设施。
-
按照整洁架构思想,基础设施属于架构的外层,它依赖处于内部的领域层也是正确的做法。在领域层,封装了领域逻辑的Services对象则可能需要持久化领域对象,甚至可能依赖基础设施的其他组件。此时传统架构已经无法满足此类要求。
传统架构
-
DDD分层架构—充血架构
-
是传统分层架构的进化,强调业务和技术分离,利用业务领域模型,充分表达业务。
-
基于六边形架构,通过内外六边形的两个不同的边界清晰的展现了领域与技术的边界。
-
领域层:保持业务模型的纯粹性。
-
基础设施层:提供技术支撑,非业务相关(存储、消息、事物、安全、外部资源适配以及Controllers等等)。
-
应用层:一个外观(facade),定义了一个高层接口,不包含业务逻辑,代表一个Use Case或者行为的入口。
-
天然吻合微服务架构。
DDD架构
4. 代码模型
根据领域驱动架构设计模式来区分,代码模型结构如下图所示
-
DDD:项目名称为DDD
-
order:项目中限界上下文对应的模块
-
ddd.ordercontext:限界上下文的命名空间,以context为后缀
-
application:应用层,可以理解为一个用例行为的入口,当使用事务时,定义在这一层
-
pl:即Publushed Language的缩写,该命名空间下为消息契约对象,也可以认为是DTO,乃开放主机服务的发布语言
-
domain:领域层,其内部按照聚合边界进行命名空间划分,每个聚合内的实体、值对象以及对应的领域服务和资源库接口都定义在同一个聚合内部
-
gateway:即基础设施层,又叫端口-适配器层(网关层,供外部请求调用资源定义的北向网关和请求外部资源请求的南向网关)
-
acl:外六边形适配器层(又叫南向网关,防腐层),需要将接口和实现分离
-
impl:包含了Repository实现的所有请求外部请求资源的实现
-
interfaces:除Repository之外的所有南向网关接口定义
-
ohs:内六边形适配器(又叫北向网关,开放主机服务),根据服务的不同可以分为resouces、controllers、providers以及事件的Publishers
当存在外部资源的变化,只需要更改gateway中的实现即可,无需修改领域层的代码;业务领域行为控制在domain中,技术实现以及外部交互控制在gateway中,这样有效的控制业务逻辑代码和技术实现代码,当存在技术迁移或者技术升级时,可以直接迁移domain层而无需担心对业务逻辑造成影响。
备注:一个上下文可以包含多个聚合,每个限界上下文是单独的模块;每个模块可以理解为就是一个微服务。
5. 总结
领域驱动设计涵盖的概念比较多,它要求我们在战略阶段基于通用语言进行建模,为项目的成功提供更好的可能性;在战术阶段,通过定义的领域模型元素(聚合、实体、值对象、资源库、工厂、领域事件等等)把业务和技术代码进行分离,有效的规避了系统复杂性。当我们遇到比较复杂的业务场景时,DDD是一个非常好的选择,我们可以借助的限界上下文来拆分我们的微服务;但它不是银弹,并不适合所有的系统,比如CRUD的系统;同时它对技术团队的整体能力也有一定的要求。当选择DDD时,我们需要根据团队规模、业务场景、以及整体技术能力来决定是否需要实施DDD。
领域驱动设计的演化过程
6. 参考资料
-
*《领域驱动设计:软件核心复杂性应对之道》*作者:Eric Evans
-
*《实现领域驱动设计》*作者:Vaughn Vernon
-
*《解构领域驱动设计》*作者:张逸