你所不知道的 HSTS
作者: Barret李靖 2015-10-22 17:48:26 本文发布时间为2015年10月22日17时48分26秒 分类: 网络交互,网络安全 标签: HSTS 下面是正文内容 评论数: 热度:
原文地址:http://www.barretlee.com/blog/2015/10/22/hsts-intro/,参与评论

很多人听说过也看到过 301、302,但是几乎从来没有看到过 303 和 307 的状态码。今天在淘宝首页看到了 307 状态码,于是摸索了一把。
起因是这样,https 使用的是 443 端口进行数据传输,而浏览器的默认端口是 80. 劫持者首先劫持用户的 80 端口,当用户向目标页发起请求时,劫持者模拟正常的 https 请求向源服务器获取数据,然后通过 80 端口返回给用户,大概可以看下下面两张图:
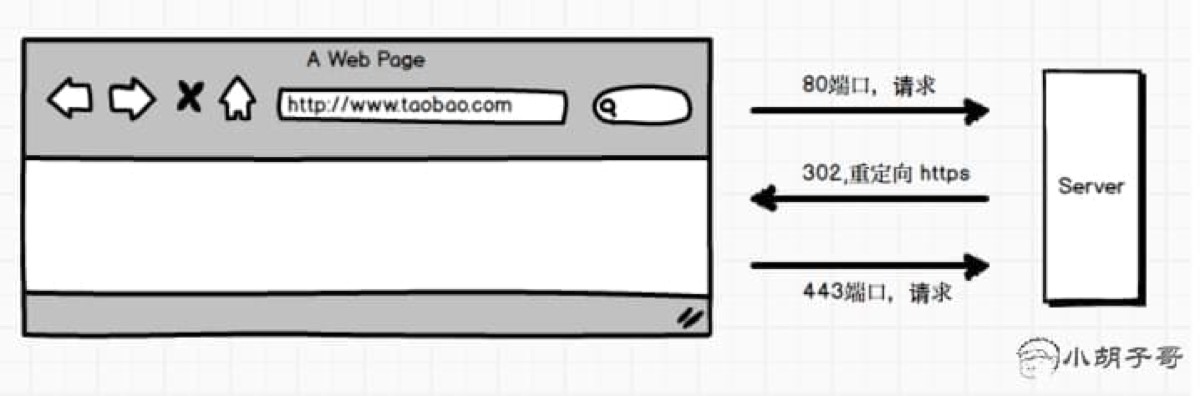
用户一般不会在地址栏输入 //www.taobao.com,而是习惯性输入 taobao.com ,此时浏览器走的是 http,请求到达服务器之后,服务器告诉浏览器 302 跳转
然后浏览器重新请求,通过 HTTPS 方式,443 端口通讯。而正因为用户不是直接输入 // 链接,劫持者利用这一点:
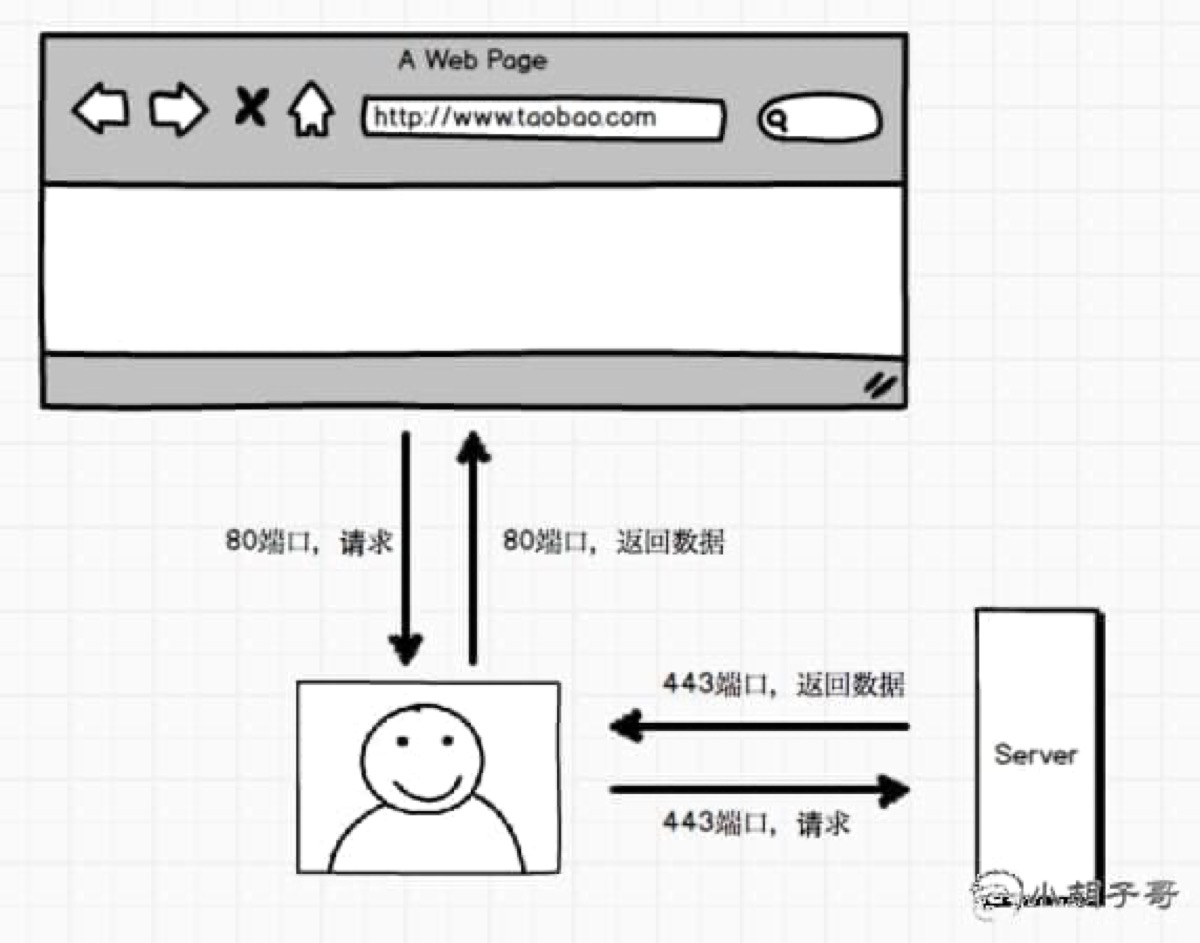
只要能够劫持你的网络,比如路由劫持、DNS劫持,就可以作为中间人注入代码、替换广告。。。(上了 https 也拗不过电信,真是日了够了)
这种劫持出现在两种情况下:
- 用户没有通过准确的方式访问页面,除非输入
//,否则浏览器默认以http方式访问 - HTTPS 页面的链接中包含 http,这个 http 页面可能被劫持
HSTS,HTTP Strict Transport Security,简单说就是强制客户端使用 HTTPS 访问页面。其原理就是:
- 在服务器响应头中添加
Strict-Transport-Security,可以设置max-age - 用户访问时,服务器种下这个头
- 下次如果使用 http 访问,只要 max-age 未过期,客户端会进行内部跳转,可以看到 307 Redirect Internel 的响应码
- 变成 https 访问源服务器
这个过程有效避免了中间人对 80 端口的劫持。但是这里存在一个问题:如果用户在劫持状态,并且没有访问过源服务器,那么源服务器是没有办法给客户端种下 Strict-Transport-Security 响应头的(都被中间人挡下来了)。
启用 HSTS 不仅仅可以有效防范中间人攻击,同时也为浏览器节省来一次 302/301 的跳转请求,收益还是很高的。我们的很多页面,难以避免地出现 http 的链接,比如 help 中的链接、运营填写的链接等,这些链接的请求都会经历一次 302,对于用户也是一样,收藏夹中的链接保存的可能也是 http 的。
在 GET、HEAD 这些幂等的请求方式上,302、303、307 没啥区别,而对于 POST 就不同了,大部分浏览器 都会302 会将 POST 请求转为 GET,而 303 是规范强制规定将 POST 转为 GET 请求,请求地址为 header 头中的 Location,307 则不一样,规范要求浏览器继续向 Location 的地址 POST 内容。
而在 HSTS 中,307 可以被缓存,缓存时间根据 max-age 而定,一般建议缓存 1 年甚至更长。
- 纯 IP 的请求,HSTS 没法处理,比如
http://2.2.2.2, 即便响应头中设置了 STS,浏览器也不会理会(未测试) - HSTS 只能在 80 和 443 端口之间切换,如果服务是 8080 端口,即便设置了 STS,也无效(未测试)
- 如果浏览器证书错误,一般情况会提醒存在安全风险,然是依然给一个链接进入目标页,而 HSTS 则没有目标页入口,所以一旦证书配置错误,就是很大的故障了
- 如果服务器的 HTTPS 没有配置好就开启了 STS 的响应头,并且还设置了很长的过期时间,那么在你服务器 HTTPS 配置好之前,用户都是没办法连接到你的服务器的,除非 max-age 过期了。
- HSTS 能让你的网站在 ssllab 上到 A+(这不是坑)
本文简单说明了 HSTS 的基本原理和相关内容,他在全站 https 下有一个较大的正向作用,推荐使用。
P.S:在 Chrome 中打开 chrome://net-internals/#hsts,添加域名之后,可以让浏览器强制对该域名启用 https,所有的 http 请求都会内部转到 https。
Page 2
![]()
作者: Barret李靖 2015-10-15 15:59:57 本文发布时间为2015年10月15日15时59分57秒 分类: 工具 标签: disqus, 多说 下面是正文内容 评论数: 热度:
关于多说,我不想多说什么,看看这两篇文章:
开始在网上搜罗了一番,没找到好用的,很多都是 python 写的,表示没学过 python,网上找了 一个方案 试用,出了好几个问题,最终还是没有搞定。所以自己重新捯饬了一个 nodejs 版本的:
使用方式
第一步
进入到你的多说后台,导出多说数据
http://{YOUR_DUOSHUO_NAME}.duoshuo.com/admin/tools/export/ |
第二步
git clone //github.com/barretlee/duoshuo-migrate-to-disqus.git |
第三步
进入你的 disqus 后台,将数据导入
//{YOUR_DISQUS_NAME}.disqus.com/admin/discussions/import/platform/generic/ |
如果操作过程中遇到什么问题,可以在本文留言。
如果导入到 disqus 无效,有可能是格式存在问题,或者某个字段的格式不对,这大多是因为多说导出的数据就不对。可以在 disqus.ejs 中加些判断,自己做过滤。
多说这种自杀式的行为颇为可耻!
Page 3
作者: Barret李靖 2015-10-14 12:27:18 本文发布时间为2015年10月14日12时27分18秒 分类: 前端杂烩 标签: bug, 渲染 下面是正文内容 评论数: 热度:
或许你曾经在 chrome 浏览器上碰到过这样让人瞠目结舌的问题:
- Hover触发一个层展示, hover离开后, 这个层还遗留残影
- 浏览器没有清理一个元素渲染的上一个状态, 导致页面多出一个错位的跟该元素一模一样的影子
- 交互时突然出现一个方形色块, 覆盖在元素上
- 或者还有更奇葩的…
以上列举到的三个问题, 我在维护淘宝首页的时候都遇到过。这些都是浏览器渲染页面时, 因为渲染引擎的 bug 导致的问题, 不常见, 更加难以写 demo 演示, 它们只在特定的复杂场景下, 程序计算存在误差或者漏洞的时候出现, 尤其是涉及到边界判断的时候。
问题复现
很难得有机会让我碰到一个可以复现的, 我把它记录下来了。如下图所示, hover 到学习模块的边界位置时:
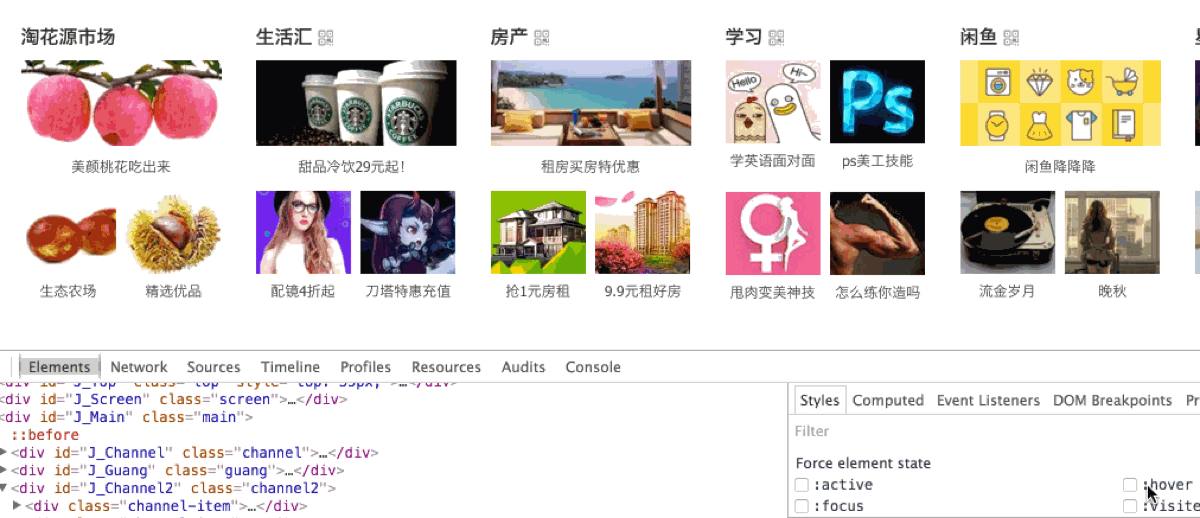
手动 hover 和模拟 hover 都有一样的问题, 没有多想, 立马加上了一句话修复了这个问题:
.channel2 .channel-item { |
这个不是直觉, 多次遇到这种奇葩问题, 我第一想到的便是使用 3D 加速将这个渲染层隔离渲染, 80% 以上的概率能够解决问题, 而解决问题的关键在于找准加这句代码的 DOM 元素。
探索 bug
这个层在我的代码中肯定是不存在的, 我们只能用 bug 来形容这个问题。因为元素刚好贴在 .channel2 的边界, 猜测应该跟层渲染有关, 于是打开了控制台 ESC -> Rendering -> Show layer borders, 看到了这个:
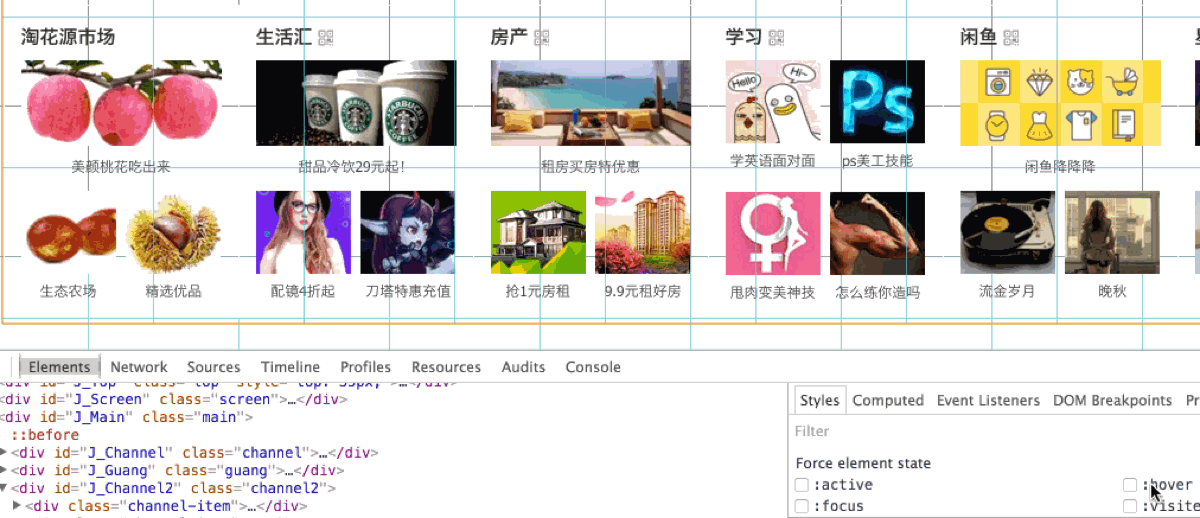
仔细观察, 可以看到, 这个粉色块在瓦片边界和父元素边界之中, 可以断定, 这几个瓦片在渲染的时候存在问题。
这里需要补充下关于瓦片的知识。瓦片, 英文里头称之为 tile, 它是 webkit/blink 渲染页面时的中间过程, 将整个页面分成多个大小一样的瓦片, 并发渲染每个瓦片的内容。一个元素开启 3D 硬件加速之后, 会变成一个独立的层, 这个层的渲染也会被分割成瓦片, 可以想象成一个子页面。
瓦片和瓦片之间的边界计算是处理的难点, 因为渲染的内容不能错位。
其实让我找到问题根本原因的是, rendering 块的颜色, 平时在网页上开启 show layer borders 看到的是半透明的绿色块, 而这里显示的是粉色块, 搜索了下不同色块代表的含义, 没找到具体的文档说明, 但是找到了 代码:
|
对应的就是这个颜色, “缺失调整验证”, 在 chromium 的源码仓库中搜了上面的代码, 找到了 具体说明:
if (!deflated_content_rect.Contains(canvas_playback_rect)) { |
这里能看的肯定就是注释啦, 没有太多上下文, 看的挺头痛!大致翻译了下上下几段注释:
- 即使完全覆盖, 对于触碰到渲染层边界的栅格化处理, 我们依然需要,在上次记录没有覆盖到的纹理下方和纹理化线性过滤的上方,栅格化处理背景颜色。
- 内容的最后的纹理可能只有部分被栅格覆盖
- 在内容边界外没有被渲染到的部分将使用 MissingResizeInvalidations 颜色, 如果这个块能够被看见, 那就意味着程序忽视处理了内边边界增长之后栅格化与内容相交的瓦片。
从第三句大致可以了解到, 因为元素的边界增长导致了这个渲染 bug, 回头看了下元素的边界状态, 果然…
直接原因
我们看看 hover 上去之后, 层边界的变化:
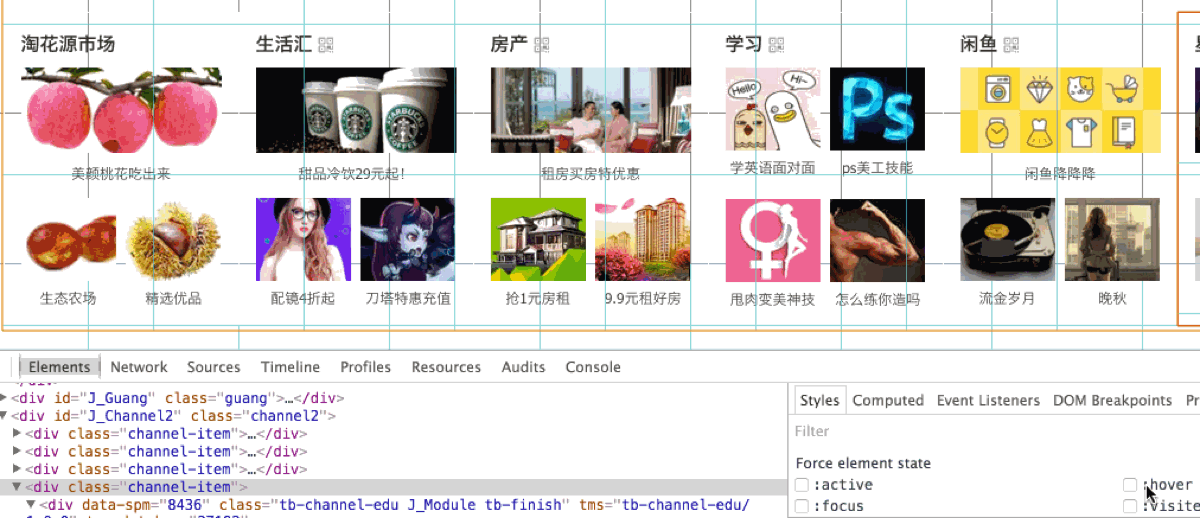
很明显, 这里的高度溢出了, 但是没有处理, 看了下这个元素的 css, 确实高度上没有做处理, 在元素上添加
.channel-item { |
同样可以解决问题。
最后的解决手段:
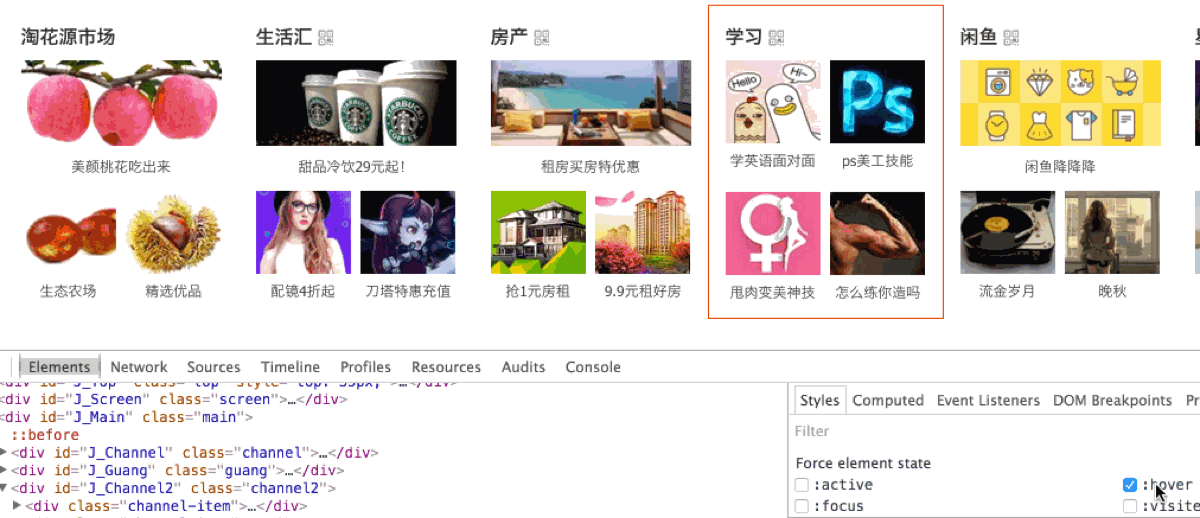
层渲染的问题我还是比较喜欢使用 3d 硬件加速来处理, 而 overflow:hidden 这样的 css 布局处理上, 我是不太推荐的, 搞不好就把哪个重要的内容隐藏掉了。
类似问题处理方案
如果以后大家遇到类似的问题, 可以打开 chrome 的层和瓦片分析工具, 看看渲染出来的块有没有异常色块, 尤其是粉色块。也可以观察交互过程中, 元素的边界有没有变化。
CSS 在浏览器中的渲染是我们触及比较少的知识, 如果想迅速找到问题, 必须对浏览器的渲染原理有所了解, 并且能够熟练的使用 chrome 提供的调试工具, 这是基础。
Page 4
NodeJS 自 2009 年显露人间,到现在已经六个年头了,由于各种原因,中间派生出了个兄弟,叫做 iojs,最近兄弟继续合体,衍生出了 nodejs4.0 版本,这东西算是 nodejs new 1.0 版本,原班人马都统一到一个战线上。我没有太关注 nodejs 背后的开发,但一直是它的忠实使用者,通读了 v4.1.2 的 文档,感觉从开发者角度去看,也没啥大的变化,所以这两个兄弟分开这么久,主要是在底层内建模块上做改造,上层建筑尚未有大的变更,具体可以看 这篇文章。
如果你一直用着 nodejs,然而一直都在写最基本的小 demo,很少深入的去剖析 nodejs 的性能问题,甚至连如何 debug 代码、如何发现性能问题都不知从哪里下手,那么赶紧往下读吧!
命令行调试
命令行中调试 nodejs 代码,这是最基础的调试技能,如同我们在 Chrome 控制中调试 JS 代码一般,然而却用的很少,因为他太原始,显得比较麻烦。
回顾下,我们平时的调试方式:
- 在某个需要输入的地方输入
console.log(),打印调试结果 - 引入
asserts模块,对调试区域进行 debug
这两种调试方式,都需要我们显式将各种 debug 信息嵌入到我们的业务逻辑代码中,而熟悉了命令行调试之后,我们可以更好地开启自己的调试之旅。NodeJS 给我们提供了 Debugger 模块,内建客户端,通过 TCP 将命令行的输入传送到内建模块以达到调试的目的。
在启动文件时,添加第二个参数 debug:
➜ $ node debug proxy2.js |
调试代码的时候存在两个状态,一个是操作调试的位置,比如下一步,进入函数,跳出函数等,此时为 debug 模式;另一个是查看变量的值,比如进入循环中,想查看循环计数器 i 的值,此时为 repl(read-eval-per-line) 状态,在 debug 模式下输入 repl 即可进入 repl 状态:
debug> repl |
按下 Ctrl+C 可以从 repl 状态回到 debug 状态下,我们也不需要记忆 debug 状态下有多少调试命令,执行 help 即可:
debug> help |
相关的命令不算很多:
| 命令 | 解释 |
|---|---|
| cont, c | 进入下一个断点 |
| next, n | 下一步 |
| step, s | 进入函数 |
| out, o | 跳出函数 |
| setBreakpoint(), sb() | 在当前行设置断点 |
| setBreakpoint(line), sb(line) | 在 line 行设置断点 |
上面几个是常用的,更多命令可以戳这里。
NodeJS的调试原理
我们平时开发都使用 IDE 工具,实际上很多 IDE 工具已经集成了 NodeJS 的调试工具,比如 Eclipse、webStorm 等等,他们的原理依然是利用 Nodejs 的 Debugger 内建模块,在这个基础上进行了封装。
细心的同学会发现,当我们使用 debug 参数打开一个 node 文件时,会输出这样一行文案:
Debugger listening on port 5858 |
可以访问下 http://localhost:5858,会看到:
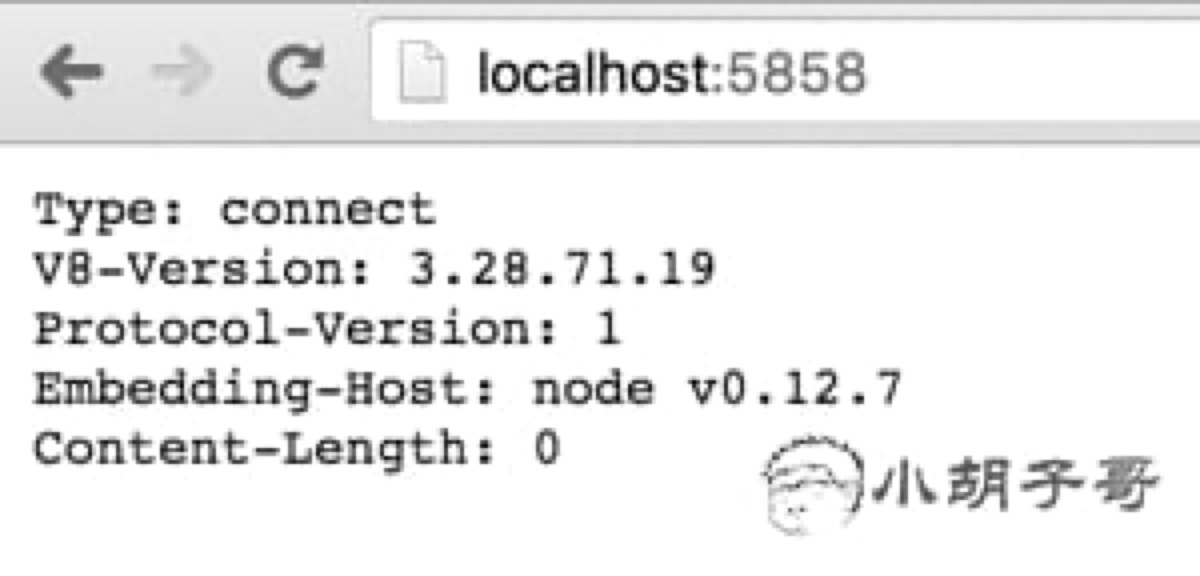
它告诉我们 nodejs 在打开文件的时候启动了内建调试功能,并且监听端口 5858 过来的调试命令。除了在命令行中直接调试之外,我们还可以通过另外两种方式去调试这个代码:
node debug <URI>, 通过 URI 连接调试,如node debug localhost:5858node debug -p <pid>通过 PID 链接调试
如果我们使用 --debug 参数打开文件:
➜ $ node --debug proxy2.js |
此时,nodejs 不会进入到命令行模式,而是直接执行代码,但是依然会开启内建调试功能,这就意味着我们具备了远程调试 NodeJS 代码的能力,使用 --debug 参数打开服务器的 nodejs 文件,然后通过:
➜ $ node debug <服务器IP>:<调试端口,默认5858> |
可以在本地远程调试 nodejs 代码。不过这里需要区分下 --debug 和 --debug-brk,前者会执行完所有的代码,一般是在监听事件的时候使用,而后者,不会执行代码,需要等到外部调试接入后,进入代码区。语言表述不会那么生动,读者可以自行测试下。
默认端口号是 5858,如果这个端口被占用,程序会递增端口号,我们也可以指定端口:
➜ node node --debug-brk=8787 proxy2.js |
更多的调试方式
node-inspector
NodeJS 提供的内建调试十分强大,它告诉 V8,在执行代码的时候中断程度,等待开发者操控代码的执行进度。我们熟知的 node-inspector 也是用的这个原理。
➜ $ node-inspector --web-port 8080 --debug-port 5858 |
这里的 --web-port 是 Chrome Devtools 的调试页面地址端口,--debug-port 为 NodeJS 启动的内建 debug 端口,我们可以在 http://localhost:8080/debug?port=5858 打开页面,调试使用 --debug(-brk) 参数打开的程序。
更多设置可以查阅官方文档。
IDE调试
Eclipse 和 webstorm 的工具栏中都有一个叫做 Run 的选择栏,在这里可以配置该文件的执行方式,比如在 webstorm 中(Navigation>Run>Edit Configurations):
第一步,为程序添加一个启动程序
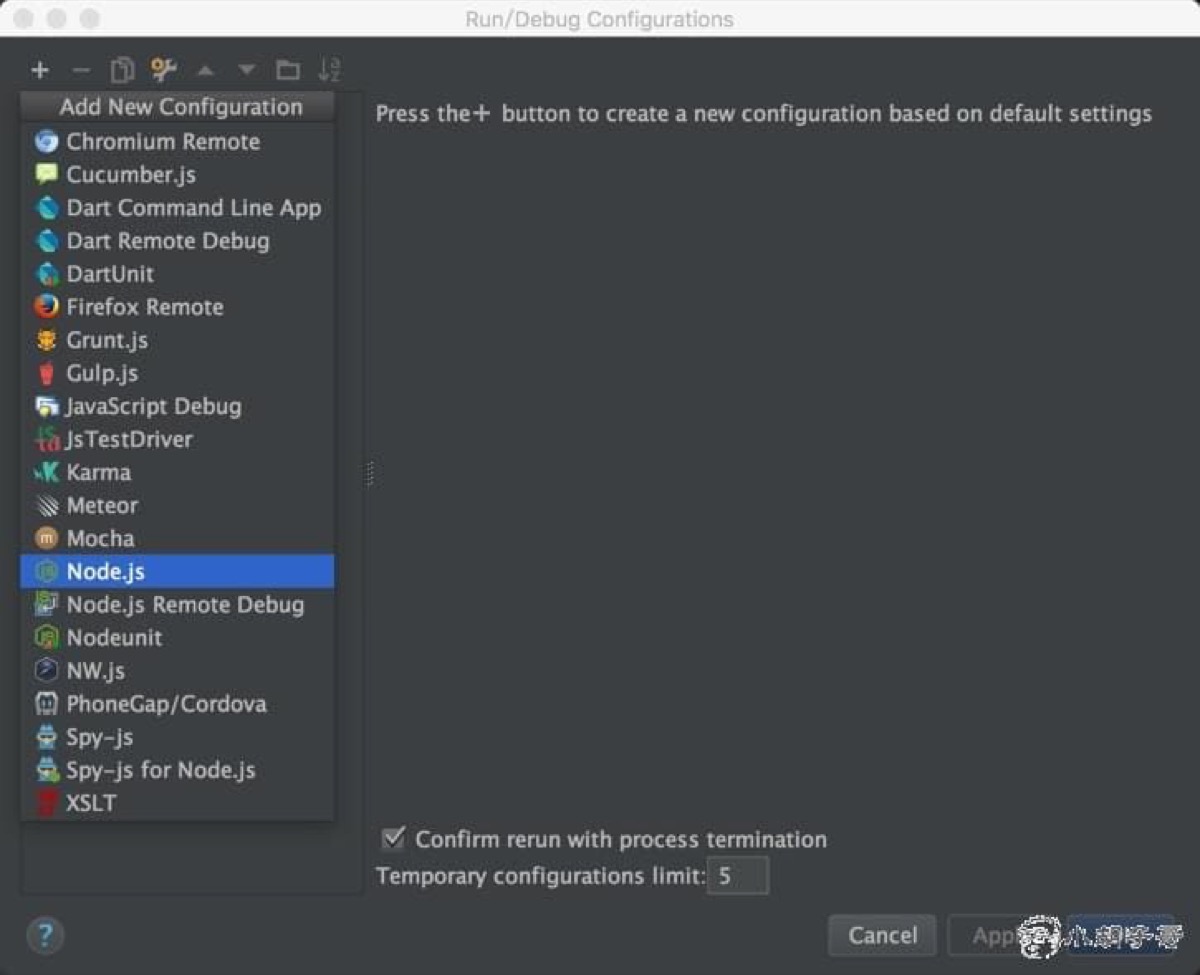
如果没有 Nodejs 的选项(如在 phpstorm 中),可以手动配置下。
第二步,配置执行项
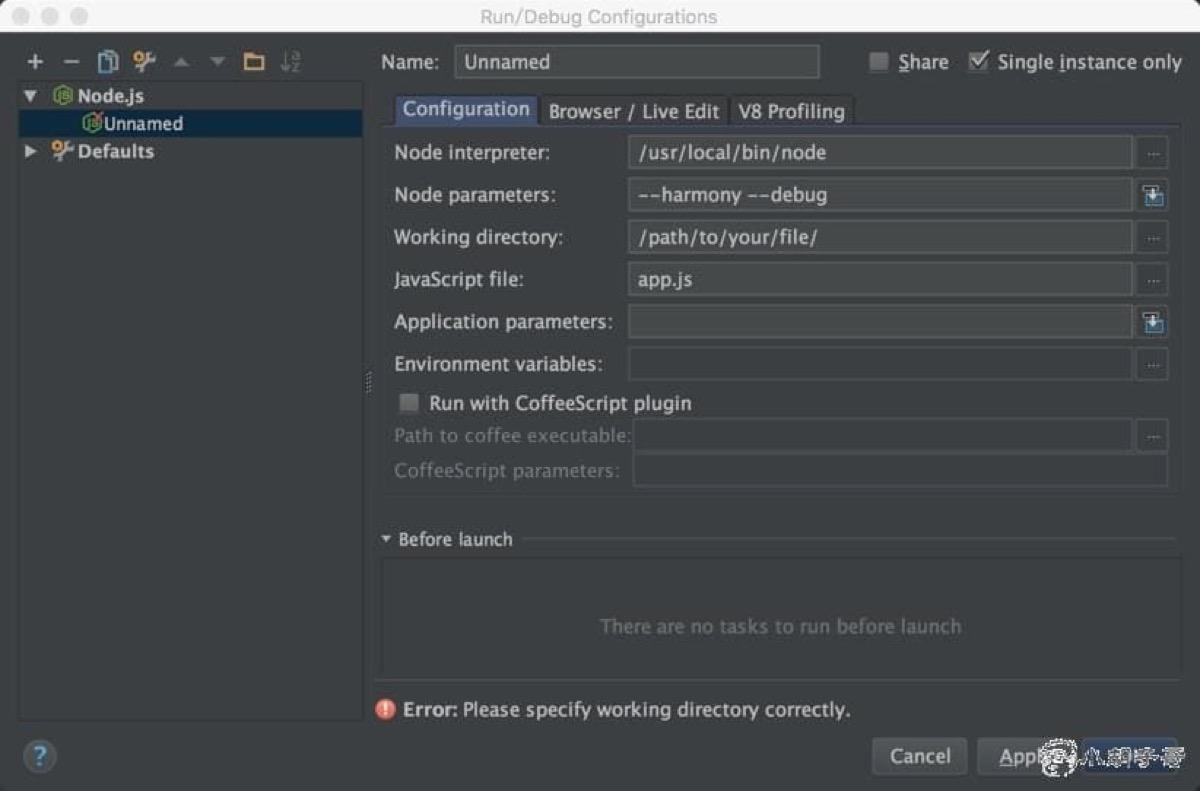
Node interpreter是你 node 程序的位置Node parameters是开启 nodejs 程序的选项,如果使用了 ES6 特性,需要开始--harmony模式,如果需要远程调试程序,可以使用--debug命令,我们采用控制台调试,显然是不需要添加--debug参数的。Working directory是文件的目录Javascript file是需要调试的文件
第三步,断点,调试
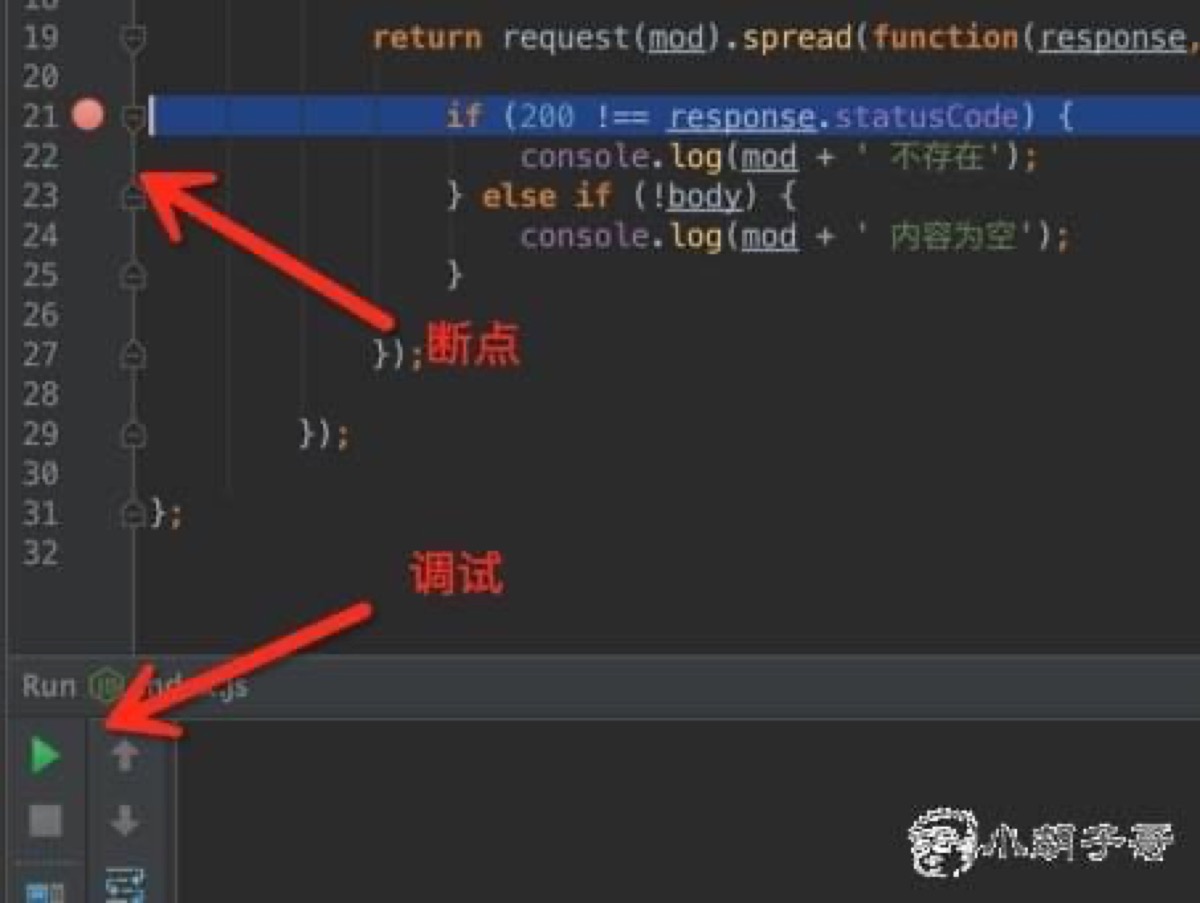
其他 IDE 工具的调试大同小异,其原理也是通过 TCP 连接到 Nodejs 开启的内建调试端口。
发现程序的问题
上面介绍了 NodeJS 调试需要掌握的几个基本技能,掌握起来还是很轻松的,但是要自己去尝试下。
Nodejs 相比 Java、PHP 这些老牌语言,其周边设施还是有所欠缺的,如性能分析和监控工具等,加上它的单线程运行特性,在大型应用中,很容易让系统的 CPU 或者内存达到瓶颈,从而导致程序崩溃。一旦发现程序警报 CPU 负载过高,或者内存飙高时,我们该如何深入排查 NodeJS 代码存在的问题呢?
首先来分析下问题,内存飙高存在哪些方面的因素呢:
- 缓存,很多人在敲程序的时候把缓存当内存用,比如使用一个对象储存用户的 session 信息
- 闭包,作用域没有被释放掉
- 生产者和消费者存在速度差,比如数据库忙不过来,Query 队列堆积
CPU 负载过高预警可能因素:
- 垃圾回收频率过高、量太大,这一般是因为内存或者缓存暴涨导致的
- 密集型的长循环计算,比如大量遍历文件夹、大量计算等
这些问题是最让人头疼的,一个项目几十上百个文件,收到这些警报如果没有经验,根本无从下手排查。
最直接的手段就是分析 GC 日志,因为程序的一举一动都会反馈到 GC 上,而上述问题也会一一指向 GC,如:
- 内存暴涨,尤其是 Old Space 内存的暴涨,会直接导致 GC 的次数和时间增长
- 缓存增加,导致 GC 的时间增加,无用遍历过多
- 密集型计算,导致 GC Now Space次数增加
这里需要稍微插一段,NodeJS 的内存管理和垃圾回收机制。
V8 的内存分为 New Space 和 Old Space,New Space 的大小默认为 8M,Old Space 的大小默认为 0.7G,64位系统这两个数值翻倍。
对象的生命周期是:首先进入 New Space,在这里,New Space 被平均分为两份,每次 GC 都会将一份中的活着的对象复制到另一份,所以它的空间使用率是 50%,这个算法叫做 Cheney 算法,这个操作叫做 Scavenge。过一段时间,如果 New Space 中的对象还活着,会被挪到 Old Space 中去,GC 会每隔一段时间遍历 Old Space 中死掉的对象,然后整理碎片(这里有两种模式 mark-sweep 和 mark-compact,不祥述)。上面提到的”死掉“,指的是对象已经没有被引用了,活着说被引用的次数为零了。
知道这些之后,我们就好分析问题了,如果缓存增加(比如使用对象缓存了很多用户信息),GC 是不知道这些缓存死了还是活着的,他们会不停地查看这个对象,以及这个对象中的子对象是否还存活,如果这个对象数特别大,那么 GC 遍历的时间也会特别长。当我们进行密集型计算的时候,会产生很多中间变量,这些变量往往在 New Space 中就死掉了,那么 GC 也会在这里多次地进行 New Space 区域的垃圾回收。
分析 GC 日志
说了这么多,如何去分析 GC 的日志?
在启动程序的时候添加 --trace_gc 参数,V8 在进行垃圾回收的时候,会将垃圾回收的信息打印出来:
➜ $ node --trace_gc aa.js |
V8 提供了很多程序启动选项:
| 启动项 | 含义 |
|---|---|
| –max-stack-size | 设置栈大小 |
| –v8-options | 打印 V8 相关命令 |
| –trace-bailout | 查找不能被优化的函数,重写 |
| –trace-deopt | 查找不能优化的函数 |
这些启动项都可以让我们查看 V8 在执行时的各种 log 日志,对于排查隐晦问题比较有用。然而这堆日志并不太好看,我们可以将日志输出来之后交给专业的工具帮我们分析,相比很多人都用过 Chrome DevTools 的 JavaScript CPU Profile,它在这里:
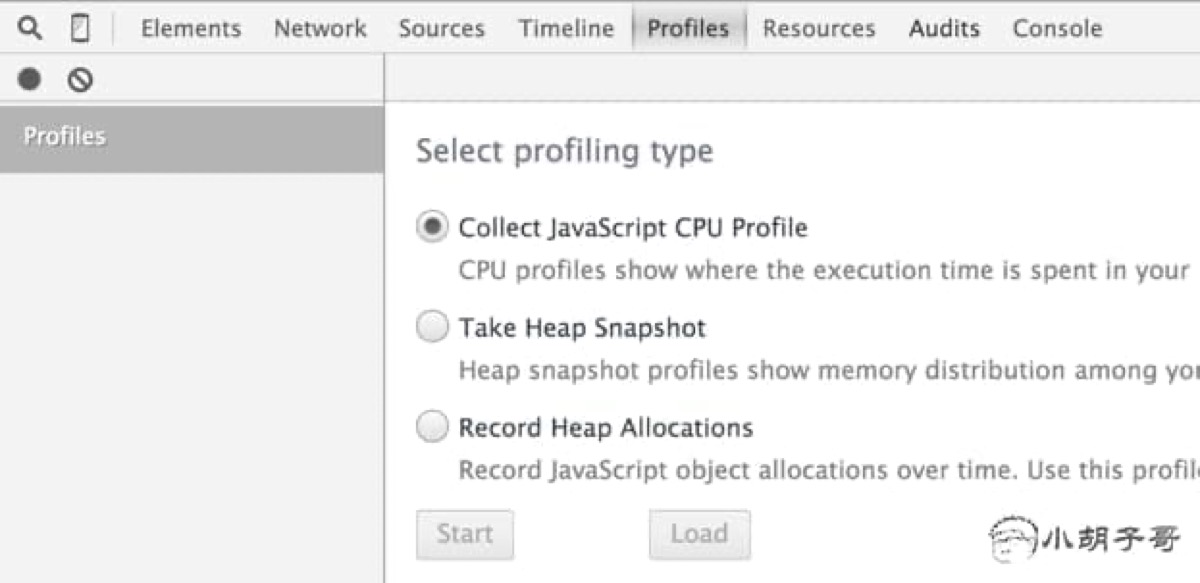
通过 Profile 可以找到具体函数在整个程序中的执行时间和执行时间占比,从而分析到具体的代码问题,V8 也提供了 Profile 日志导出:
执行命令之后,会在该目录下产生一个 *-v8.log 的日志文件,我们可以安装一个日志分析工具 tick:
➜ $ sudo npm install tick -g |
我们也可以使用 headdump 之类的工具将日志导出,然后放到 Chrome 的 Profile 中去分析。
小结
本文主要从 NodeJS 程序的调试手段上,以及调试性能的入口上做了简要的介绍,希望对你有所启发,不到之处还请斧正!
Page 5
今天摸索了下 HTTPS 的证书生成,以及它在 Nginx 上的部署。由于博客托管在 github 上,没办法部署证书,先记录下,后续有需要方便快捷操作。本文的阐述不一定完善,但是可以让一个初学者了解大致的原理,同时跟着操作可以为自己的博客/网站部署一个 HTTPS 证书。

网站部署 HTTPS 的重要性
看看下面,部分电信用户访问京东首页的时候,会看到右下角有一个浮动广告:
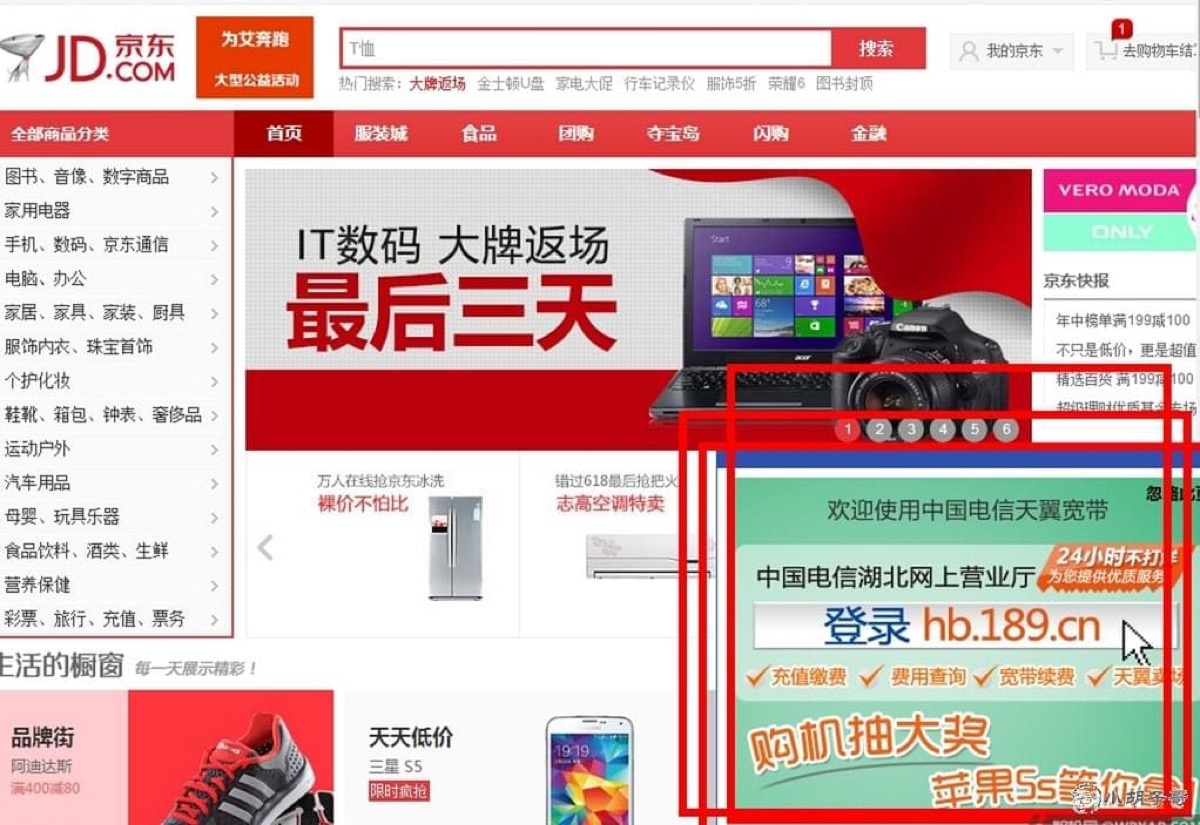
小白用户以为是京东有意放置的,细心的用户会发现,这个 iframe 一层嵌一层的恶心广告很明显是电信/中间人通过 DNS 劫持注入进去的,十分恶心,没有关闭按钮。
随着互联网的快速发展,我们几乎离不开网络了,聊天、预订酒店、购物等等,我们的隐私无时无刻不暴露在这庞大的网络之中,HTTPS 能够让信息在网络中的传递更加安全,增加了 haker 的攻击成本。
HTTPS 区别于 HTTP,它多了加密(encryption),认证(verification),鉴定(identification)。它的安全源自非对称加密以及第三方的 CA 认证。
简述 HTTPS 的运作

如上图所示,简述如下:
- 客户端生成一个随机数
random-client,传到服务器端(Say Hello) - 服务器端生成一个随机数
random-server,和着公钥,一起回馈给客户端(I got it) - 客户端收到的东西原封不动,加上
premaster secret(通过random-client、random-server经过一定算法生成的东西),再一次送给服务器端,这次传过去的东西会使用公钥加密 - 服务器端先使用私钥解密,拿到
premaster secret,此时客户端和服务器端都拥有了三个要素:random-client、random-server和premaster secret - 此时安全通道已经建立,以后的交流都会校检上面的三个要素通过算法算出的
session key
CA 数字证书认证中心
如果网站只靠上图运作,可能会被中间人攻击,试想一下,在客户端和服务端中间有一个中间人,两者之间的传输对中间人来说是透明的,那么中间人完全可以获取两端之间的任何数据,然后将数据原封不动的转发给两端,由于中间人也拿到了三要素和公钥,它照样可以解密传输内容,并且还可以篡改内容。
为了确保我们的数据安全,我们还需要一个 CA 数字证书。HTTPS的传输采用的是非对称加密,一组非对称加密密钥包含公钥和私钥,通过公钥加密的内容只有私钥能够解密。上面我们看到,整个传输过程,服务器端是没有透露私钥的。而 CA 数字认证涉及到私钥,整个过程比较复杂,我也没有很深入的了解,后续有详细了解之后再补充下。
CA 认证分为三类:DV ( domain validation),OV ( organization validation),EV ( extended validation),证书申请难度从前往后递增,貌似 EV 这种不仅仅是有钱就可以申请的。
对于一般的小型网站尤其是博客,可以使用自签名证书来构建安全网络,所谓自签名证书,就是自己扮演 CA 机构,自己给自己的服务器颁发证书。
生成密钥、证书
第一步,为服务器端和客户端准备公钥、私钥
|
第二步,生成 CA 证书
|
在执行第二步时会出现:
➜ keys openssl req -new -key ca.key -out ca.csr |
注意,这里的 Organization Name (eg, company) [Internet Widgits Pty Ltd]: 后面生成客户端和服务器端证书的时候也需要填写,不要写成一样的!!!可以随意写如:My CA, My Server, My Client。
然后 Common Name (e.g. server FQDN or YOUR name) []: 这一项,是最后可以访问的域名,我这里为了方便测试,写成 localhost,如果是为了给我的网站生成证书,需要写成 barretlee.com。
第三步,生成服务器端证书和客户端证书
|
此时,我们的 keys 文件夹下已经有如下内容了:
. |
看到上面两个 js 文件了么,我们来跑几个demo。
HTTPS本地测试
服务器代码:
|
短短几行代码就构建了一个简单的 https 服务器,options 将私钥和证书带上。然后利用 curl 测试:
➜ https curl //localhost:8000 |
当我们直接访问时,curl //localhost:8000 一堆提示,原因是没有经过 CA 认证,添加 -k 参数能够解决这个问题:
➜ https curl -k //localhost:8000 |
这样的方式是不安全的,存在我们上面提到的中间人攻击问题。可以搞一个客户端带上 CA 证书试试:
|
先打开服务器 node http-server.js,然后执行
➜ https node https-client.js |
如果你的代码没有输出 hello world,说明证书生成的时候存在问题。也可以通过浏览器访问:
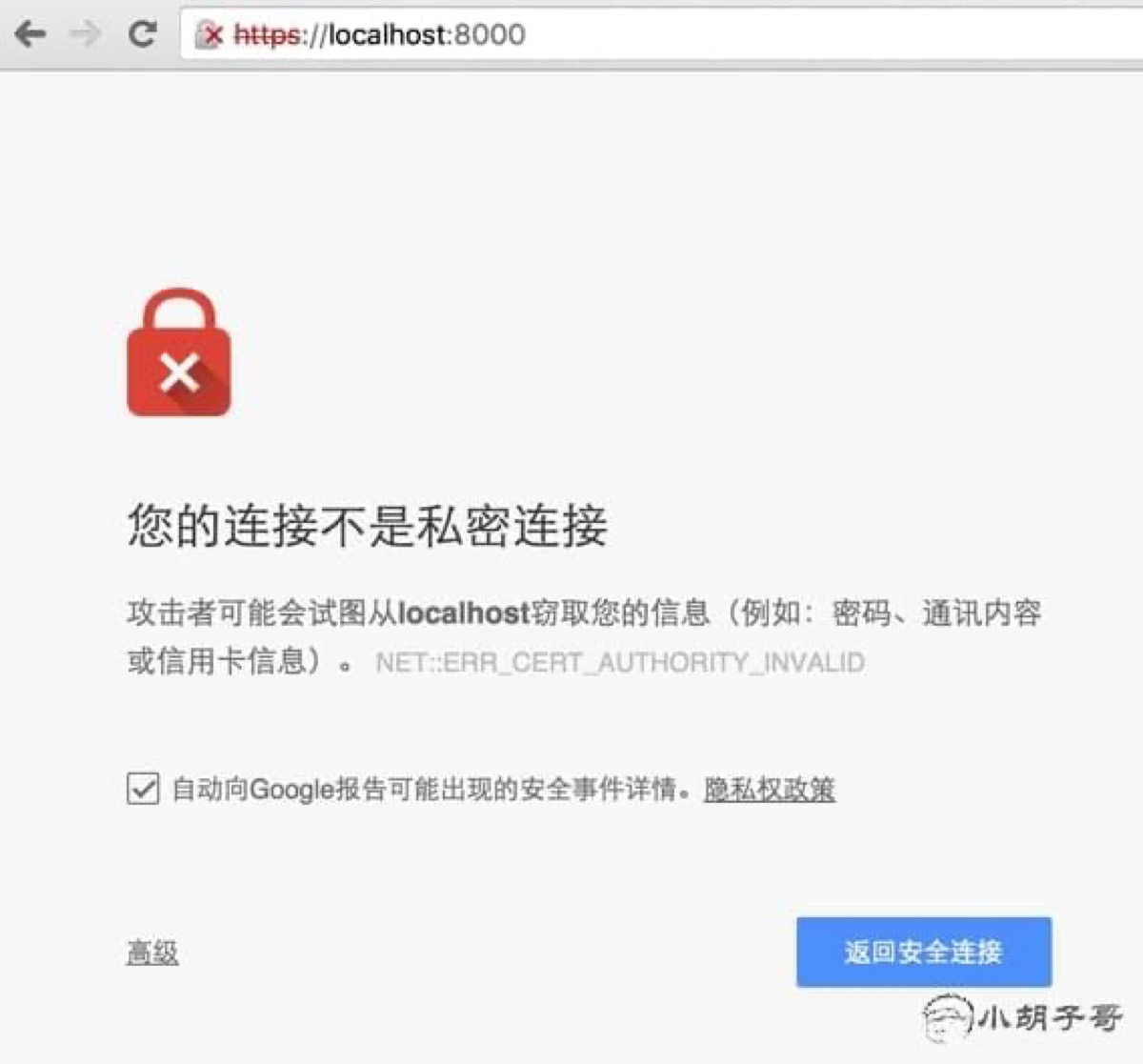
提示错误:
此服务器无法证明它是localhost;您计算机的操作系统不信任其安全证书。出现此问题的原因可能是配置有误或您的连接被拦截了。
原因是浏览器没有 CA 证书,只有 CA 证书,服务器才能够确定,这个用户就是真实的来自 localhost 的访问请求(比如不是代理过来的)。
你可以点击 继续前往localhost(不安全) 这个链接,相当于执行 curl -k //localhost:8000。如果我们的证书不是自己颁发,而是去靠谱的机构去申请的,那就不会出现这样的问题,因为靠谱机构的证书会放到浏览器中,浏览器会帮我们做很多事情。初次尝试的同学可以去 startssl.com 申请一个免费的证书。
Nginx 部署
ssh 到你的服务器,对 Nginx 做如下配置:
server_names barretlee.com *.barretlee.com |
会发现,网页 URL 地址框左边已经多出了一个小绿锁。当然,部署好了之后可以去这个网站看看测评分数,如果分数是 A+,说明你的 HTTPS 的各项配置都还不错,速度也很快。
小结
好吧,我也是初次尝试,本地测试是 ok 的,由于买的阿里云服务器到期了也没续费,就没远程折腾,其实本地 Nginx + Nodejs,然后 Hosts 配置域名也是可以较好模拟的。文中很多地方描述的可能不是十分准确,提到的点也不够全面,如果有错误,还请斧正!