
软件的性能分析,往往需要查看 CPU 耗时,了解瓶颈在哪里。
火焰图(flame graph)是性能分析的利器。本文介绍它的基本用法。
一、perf 命令
让我们从 perf 命令(performance 的缩写)讲起,它是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
通常,它的执行频率是 99Hz(每秒99次),如果99次都返回同一个函数名,那就说明 CPU 这一秒钟都在执行同一个函数,可能存在性能问题。
$ sudo perf record -F 99 -p 13204 -g -- sleep 30
上面的代码中,perf record表示记录,-F 99表示每秒99次,-p 13204是进程号,即对哪个进程进行分析,-g表示记录调用栈,sleep 30则是持续30秒。
运行后会产生一个庞大的文本文件。如果一台服务器有16个 CPU,每秒抽样99次,持续30秒,就得到 47,520 个调用栈,长达几十万甚至上百万行。
为了便于阅读,perf record命令可以统计每个调用栈出现的百分比,然后从高到低排列。
$ sudo perf report -n --stdio
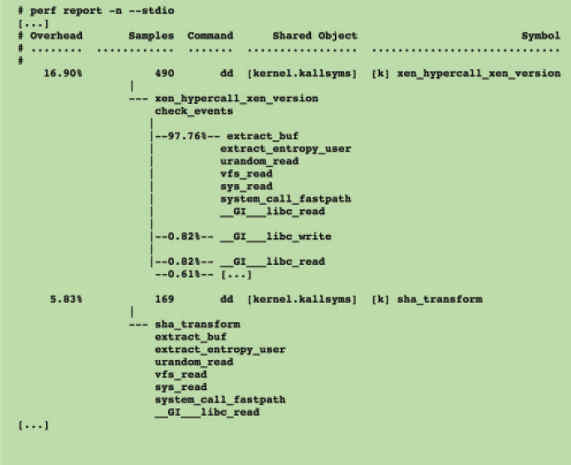
这个结果还是不易读,所以才有了火焰图。
二、火焰图的含义
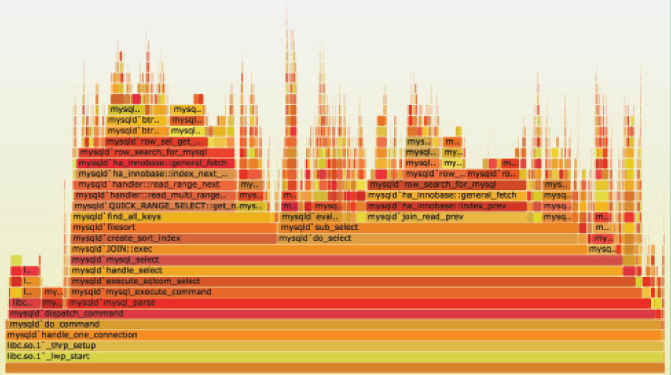
火焰图是基于 perf 结果产生的 SVG 图片,用来展示 CPU 的调用栈。

y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
三、互动性
火焰图是 SVG 图片,可以与用户互动。
(1)鼠标悬浮
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。下面是一个例子。
mysqld'JOIN::exec (272,959 samples, 78.34 percent)
(2)点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息。
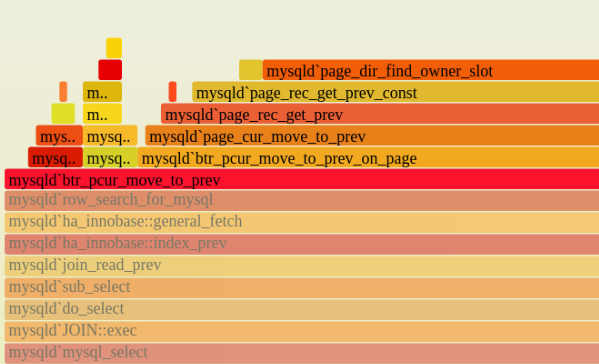
左上角会同时显示"Reset Zoom",点击该链接,图片就会恢复原样。
(3)搜索
按下 Ctrl + F 会显示一个搜索框,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。
四、火焰图示例
下面是一个简化的火焰图例子。
首先,CPU 抽样得到了三个调用栈。
func_c func_b func_a start_thread func_d func_a start_thread func_d func_a start_thread
上面代码中,start_thread是启动线程,调用了func_a。后者又调用了func_b和func_d,而func_b又调用了func_c。
经过合并处理后,得到了下面的结果,即存在两个调用栈,第一个调用栈抽中1次,第二个抽中2次。
start_thread;func_a;func_b;func_c 1 start_thread;func_a;func_d 2
有了这个调用栈统计,火焰图工具就能生成 SVG 图片。

上面图片中,最顶层的函数g()占用 CPU 时间最多。d()的宽度最大,但是它直接耗用 CPU 的部分很少。b()和c()没有直接消耗 CPU。因此,如果要调查性能问题,首先应该调查g(),其次是i()。
另外,从图中可知a()有两个分支b()和h(),这表明a()里面可能有一个条件语句,而b()分支消耗的 CPU 大大高于h()。
五、局限
两种情况下,无法画出火焰图,需要修正系统行为。
(1)调用栈不完整
当调用栈过深时,某些系统只返回前面的一部分(比如前10层)。
(2)函数名缺失
有些函数没有名字,编译器只用内存地址来表示(比如匿名函数)。
六、Node 应用的火焰图
Node 应用的火焰图就是对 Node 进程进行性能抽样,与其他应用的操作是一样的。
$ perf record -F 99 -p `pgrep -n node` -g -- sleep 30
详细的操作可以看这篇文章。
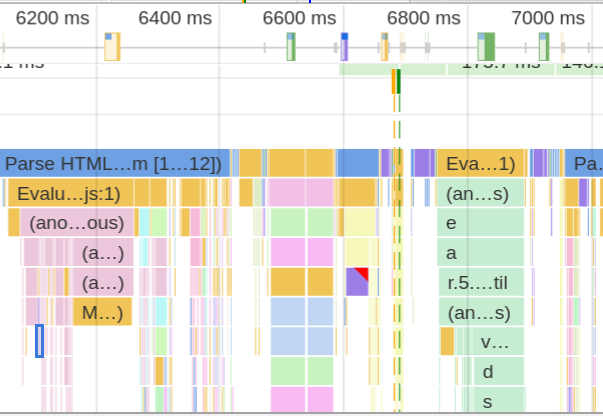
七、浏览器的火焰图
Chrome 浏览器可以生成页面脚本的火焰图,用来进行 CPU 分析。
打开开发者工具,切换到 Performance 面板。然后,点击"录制"按钮,开始记录数据。这时,可以在页面进行各种操作,然后停止"录制"。
这时,开发者工具会显示一个时间轴。它的下方就是火焰图。
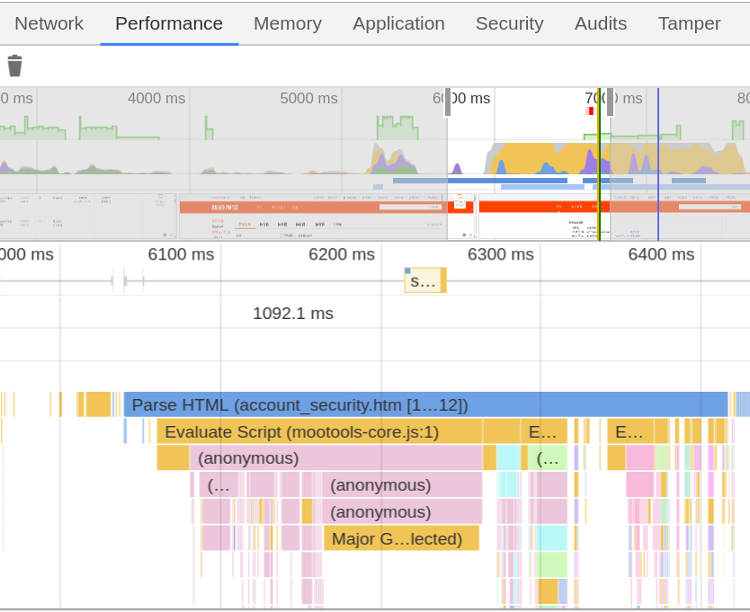
浏览器的火焰图与标准火焰图有两点差异:它是倒置的(即调用栈最顶端的函数在最下方);x 轴是时间轴,而不是抽样次数。
八、参考链接
(完)

szpzs 说:
谢谢阮老师的文章,通俗易懂!
2017年9月26日 08:12 | # | 引用
清风扬101 说:
现在前端对性能要求越来越高了。感谢阮老师的分享
2017年9月26日 08:26 | # | 引用
Micooz Lee 说:
直接观察"平顶"(plateaus)往往不能快速定位性能问题,因为顶部记录的多半是对底层库函数的调用情况。我认为,要快速定位性能问题,首先应该观察的是业务函数在火焰图中的宽度,然后在往顶部找到第一个库函数来缩小范围,而不是直接就看平顶。
2017年9月26日 09:18 | # | 引用
RRR 说:
可以再讲讲 memory 面板的调试技巧
2017年9月26日 10:33 | # | 引用
lingyong 说:
谢谢分享!
2017年9月26日 13:00 | # | 引用
野马 说:
通俗易懂,牛逼
2017年9月26日 20:28 | # | 引用
奇葩 说:
第一个命令就没法运行
2017年9月27日 10:10 | # | 引用
owenliang 说:
perf top也不错~
2017年9月27日 10:38 | # | 引用
xgfone 说:
通俗易懂,以前一直看不懂火焰图,就没认真研究,看了阮老师的这篇文章,基本上该懂的都懂了,至少入门了!
2017年9月27日 10:56 | # | 引用
mrcode 说:
真棒,以前一直不知道怎么看火焰图。阮总的文章总是娓娓道来,有条有理。
2017年9月29日 15:00 | # | 引用
业余草 说:
满满的都是知识!
2017年9月29日 15:03 | # | 引用
maxmin 说:
很直观
2017年9月30日 16:26 | # | 引用
Link 说:
感谢阮老师
2017年10月 3日 17:55 | # | 引用
王乐 说:
阮一峰老师,您好,关注您的博客很久了,第一次留言:
最近有一个困惑,我想去一些“墙”外的网站学习一下,比如 The Economist,但是由于某些原因,我无法浏览。请问一下,您平时是如何“出国”学习的?有没有好的“出国”方式推荐一下?谢谢您!期待您的回复或邮件。
2017年10月 7日 17:20 | # | 引用
PHP框架 说:
多谢阮老师讲解,很容易明白。
2017年10月 8日 18:49 | # | 引用
Bruce.Cheng 说:
通俗易懂,以前就看不懂火焰图,看完阮老师的文章还是没懂
2017年10月13日 13:42 | # | 引用
洪平样 说:
写的很好
2017年10月13日 22:28 | # | 引用
施守檑 说:
为什么不做个返回顶部的箭头。
2017年10月20日 16:47 | # | 引用
geekjc 说:
一脸懵逼的进来,一脸懵逼的出去。^_^
2017年10月26日 15:54 | # | 引用
Amecy 说:
@王乐:
可以了解一下 shadowsockes
2018年10月12日 10:08 | # | 引用
yummy 说:
感谢阮老师的分享,通俗易懂!
2019年6月15日 14:43 | # | 引用
Jessewoo 说:
需要区分 call chart 和 flame chart,前者是倒置的“火焰”,比如上面chrome的例子就是这种;后者是真正的火焰图。
2021年3月 3日 20:55 | # | 引用
Junlong 说:
“另外,从图中可知a()有两个分支b()和h(),这表明a()里面可能有一个条件语句,而b()分支消耗的 CPU 大大高于h()。”
阮老师,我看了下火焰图的介绍论文。他们对这部分的介绍是,除了两个分支之外,还有a()顺序执行b()和h()两个函数的可能。您看下要不要补充下。
2021年10月16日 18:43 | # | 引用
ponyma 说:
为什么函数g()占用 CPU 时间最多?
2021年10月25日 19:51 | # | 引用
伯沣 说:
我觉得并没有讲明白为什么看顶层就能发现性能瓶颈了;
2022年8月19日 11:16 | # | 引用
ML 说:
最顶端的函数是真正在执行的函数,而宽度是抽样抽到的次数,也可以简单的认为是执行时长,函数g()在最顶端并且最宽
2023年1月 3日 14:00 | # | 引用
wangj 说:
为什么上数第二层e()+f()的总宽度小于下层d()的总宽度?
2023年1月15日 17:16 | # | 引用
matepi 说:
因为不能有无父之子,下一层父宽度必大于等于上一层子
博主有一个事,或许应特别强调出来让读者理解:
整个火焰图是纵向n条调用栈、然后做横向合并而来;合并得到的宽度代表了调用栈中的栈片段重复情况。调用栈是一个非常强调父子关系的数据结构,如:
a->b->c的调用,在这“一个”调用栈上,不可能[父b]被调用了3次而[子c]被调用了4次。
但[子c]可以调用3次,[父b]只被调用了4次:这代表了a->b->c的调用了出现了3次,a->b出现了1次。
同时火焰图对a->b->c和a->d->c,一旦在b和d上已经分叉,就不会再c上做合并。这其实也是火焰图存在局限的问题点。比如你获取连接存在池化过程,可能存在两种:
当连接池连接可复用:mydboperation -> getconnfrompool -> reuse_conn_got -> dbop_on_conn(高度4)
当连接池连接已释放、需新建:mydboperation -> getconnfrompool -> gen_new_conn -> put_conn_inpool -> dbop_on_conn(高度5)
这样reuse_conn和new_conn之后的dbop就不能在分叉之后再合并了,甚至其高度也会有差异(高度差异对视觉效果来说影响很大),即便高度一致火焰图也不会合并。这种局限性对火焰图的泛性使用实际上是很大的一个待解决问题。
2023年7月28日 15:28 | # | 引用